
This series takes you from zero to hero with the latest and greatest cloud data warehousing platform, Snowflake.
If there has been a lot of hype around how Tableau and Snowflake work so well together, it’s simply because they do! Tableau is a modern BI platform that enables powerful, self-service analytics in a continuously visual process to uncover rapid business insights. Snowflake is a true SaaS multi-cluster modern cloud data platform that enables instant elastic scalability for unlimited concurrent users. It’s a match made in data heaven! If BI technologies could get married, InterWorks would perform the ceremony:
Obviously, these tools are not mutually exclusive to each other. By my last count, Tableau has over 80 native connectors to different types of data sources. And you can report out of Snowflake using almost whatever BI tool you want. But there is a world of difference between something that works and a solution that is best. In our opinion, Tableau + Snowflake is best.
Unlike other articles in this series, we will be shifting gears here to address the topic from the perspective of a Tableau user who wants to know, “Why Snowflake?”. For those who are Snowflake customers wondering why Tableau is the #1 visual analytics tool in the world, there are plenty of other articles on the InterWorks blog that help provide answers.
Optimized for Analytical Queries
Snowflake is a modern cloud data platform that is optimized for analytical queries. It is so optimized that you are encouraged to use live connections to Snowflake from Tableau rather than extracts.
Columnar Database: Most traditional on-prem databases are row-oriented rather than column-oriented, and columnar databases are much better suited for analytical queries. When data is loaded into Snowflake, Snowflake reorganizes that data into its internal optimized, compressed, columnar format. This makes aggregations perform much faster. Querying a row-oriented table typically involves pulling all the data into memory, so it can parse through which values should be used from which columns.
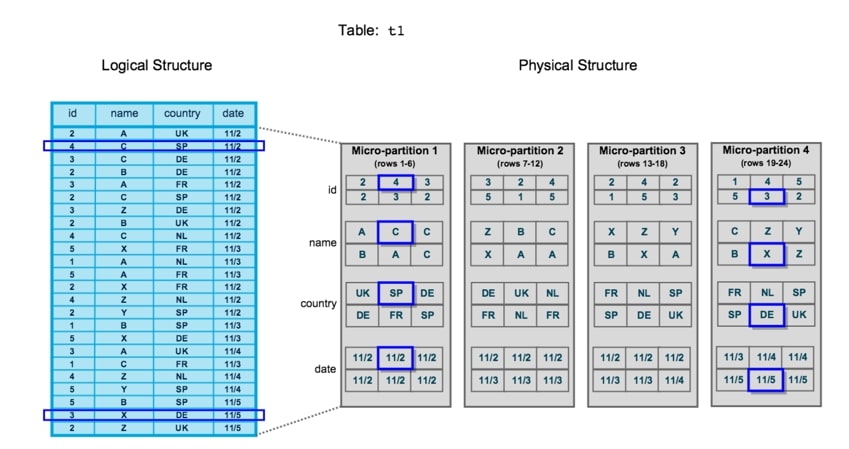
Micro-partitions: In Snowflake, tables are not physically stored but rather are logical representations of small files in cloud storage called micro-partitions. Why does this matter when querying the database? Because the query can be further “pruned,” not just based on which columns get used but also on which micro-partitions are used based on the filtering. If you want to SELECT A, B, C FROM table WHERE C=1 then you will only have to query the micro-partitions where C=1:
Result Caching: Snowflake has three layers of result caching, but the key thing for a Tableau user to know is that query results are cached for 24 hours at the cloud services metadata layer, so if you run the same query within a day, the results will snap right back without using any compute resources. Running the same query again will reset the 24-hour timer on the cache. For Tableau users clicking around on a dashboard and bouncing back and forth between filters, this will dramatically enhance the user experience. Big surprise—databases like SQL Server or flat file sources like Excel do not have any query result caching, so a user clicking around a dashboard could be running the same queries again multiple times:
Zero Query Administration: Unlike its competitors in the modern data platform space, Snowflake does not have any indexing, partitioning, vacuuming or distribution keys. The goal is simplicity and removing the headache of administering when it comes to performance-tuning queries. This is made possible via the unique micro-partition architecture mentioned above which essentially clusters the data automatically. Tuning is not required or recommended for any tables under a terabyte, allowing Tableau users to worry about analytics rather than performance.
Elastic Scaling for Seamless Performance
Snowflake is a true multi-cluster cloud data platform that can elastically scale up or out. Its ability to ramp up computing power and eliminate concurrency issues further support making live connections to Snowflake from Tableau.
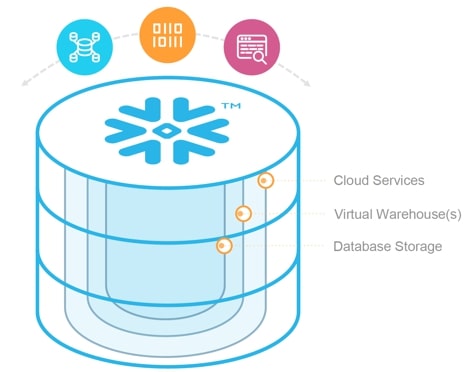
Storage and Compute Separated: To start with, we must understand that Snowflake is uniquely designed to separate storage and compute. As an example, the laptop I’m using to type this article has storage and compute coupled together. If I want to add more storage, I need to buy hardware and install it. If I want the computer to run faster, I will need to do the same thing. Most databases work in this way (even the modern ones), but not Snowflake. Storage and compute are entirely separate and independently managed.
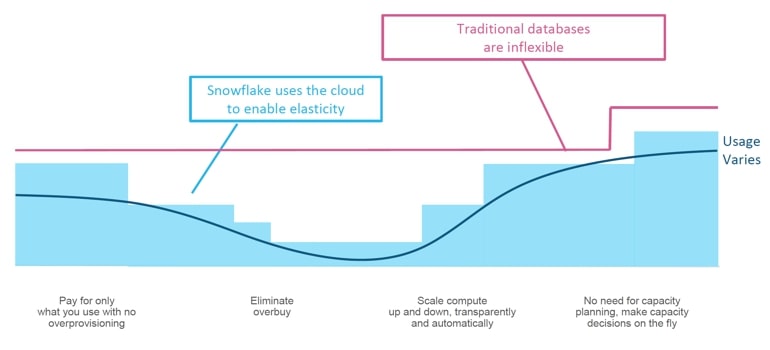
Elasticity: The primary benefit from the separation of storage and compute is that these elements can be added on-demand as needed. This is only made possible with a modern cloud platform. Snowflake keeps a pool of computing nodes at the ready and assigns them to different accounts depending on the configuration of the virtual warehouses. As a result, Snowflake can add or swap out the computing resources depending on the need to scale up or out. With another database, you would have to appropriately size the storage or compute according to a worst-case scenario to handle peak usage. And then size up once you hit your limit. Snowflake’s elastic architecture allows the user to dynamically and automatically scale up or down according to actual usage:
Scaling Up: Scaling up means that you need a bigger computer with more nodes because you have a complicated query. In Snowflake, you can re-size your virtual warehouse according to t-shirt sizes (XS, S, M, L, etc.) to add more nodes:
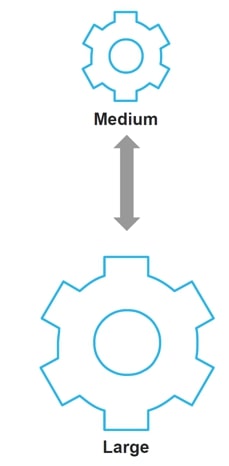
Above: Scale your compute resources UP to handle more complex queries
Scaling Out: Scaling out means that you need more computing resources because you are running more queries. A Tableau deployment may have thousands of users hitting dozens of dashboards that all query from the same few tables. Concurrency can be a real issue that affects performance in the user experience. Instead of making the queries wait in a queue, Snowflake’s true multi-cluster functionality allows for a virtual warehouse to split into multiple clusters to eliminate queuing:
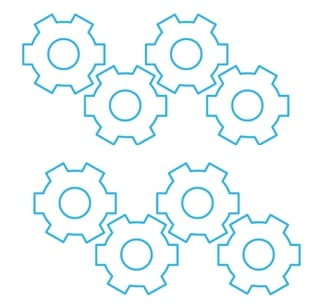
Above: Scale your compute resources OUT to handle more concurrent queries
Handling Semi-Structured Data
A game-changing feature of Snowflake is its ability to natively handle semi-structured data. This format of data does not conform to standards of traditional structured data (i.e. columns and rows). It contains tags or other types of markups to indicate distinct entities within the data and is characterized by nested data structures and a lack of a fixed schema.
These same characteristics make it very frustrating to work with reporting tools. For Tableau users who have had to frustrate themselves with Tableau’s JSON connector, Snowflake’s ability to handle semi-structured data opens a whole new world of possibilities.
Snowflake can store semi-structured data formats such as JSON, Avro, ORC, Parquet and XML using its new VARIANT data type and read from it using SQL. Using weather data formatted in JSON as an example, a user could store the JSON in a column value with the VARIANT data type, query from it using SQL, build a view that flattens the data into a table and connect Tableau to the view:

Above: JSON stored in the VARIANT data type. Each one of these cells has over 1,000 lines of JSON!

Above: Example of SQL used to query the JSON data to flatten out the data
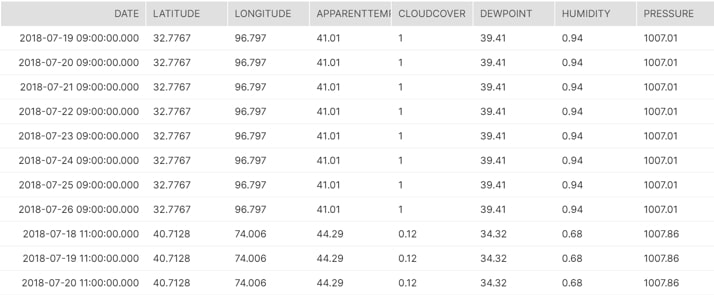
Above: Query can be stored as a view and connected to Tableau for reporting
Connecting to Snowflake from Tableau
Before connecting to Snowflake with Tableau, you may need to download the Snowflake ODBC driver first. Go to your instance of Snowflake, and select Help > Download > ODBC Driver as shown below:
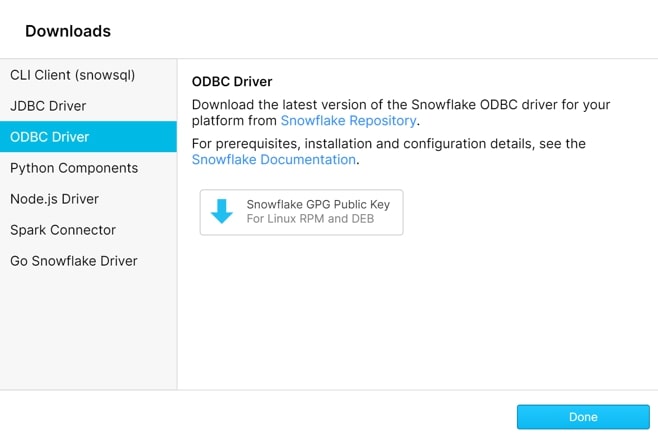
Tableau has a native connector to Snowflake. Be sure to use the first-class connector instead of the generic Other Databases (ODBC) connector because then Tableau will generate SQL specifically optimized for running on Snowflake:
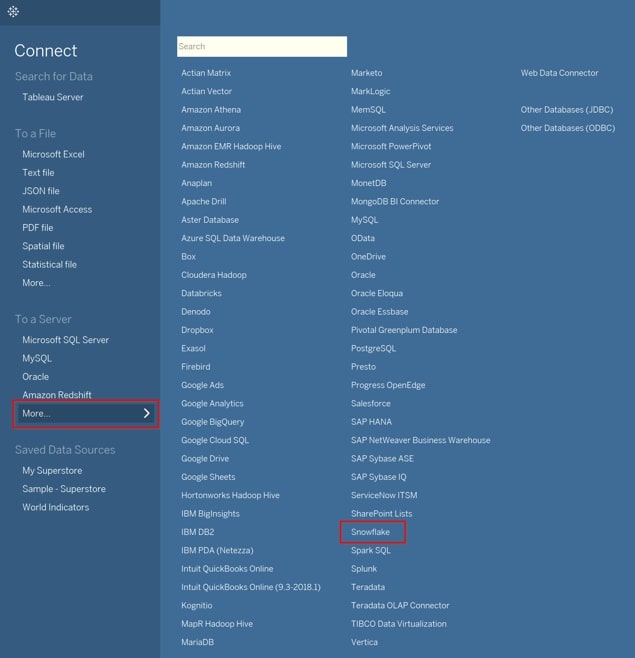
Log in using Snowflake credentials. The Server corresponds to the account URL used to navigate to the Snowflake instance. Please note that you should not put in the https:// in front as the connector will generate that automatically. Role is an optional field:
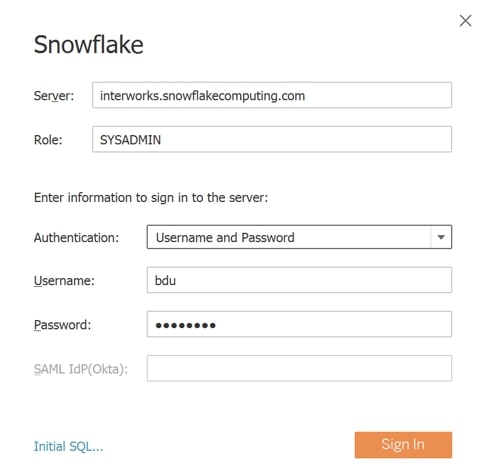
Upon successful login, the Data Source pane will provide drop-down menus for selecting a Warehouse, Database and Schema. Click and drag the tables/views onto the canvas and join:
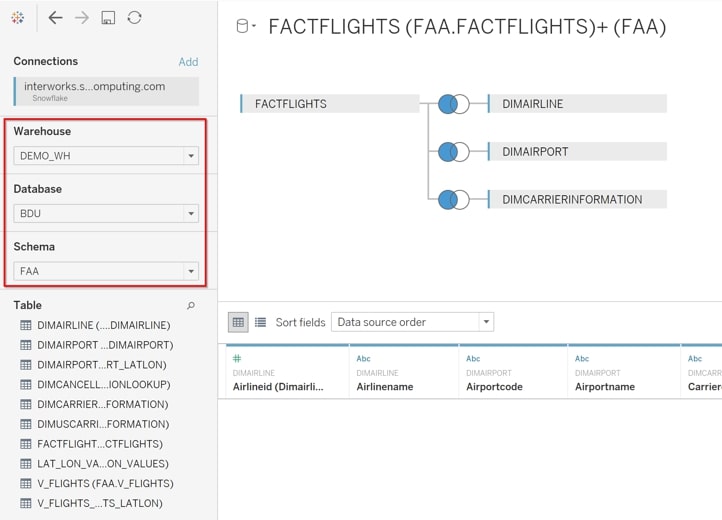
Note that with Snowflake, all the performance and scaling optimizations we discussed in the beginning make it optimal for users to have live connections to Snowflake rather than running extracts:
After that, you should be all set to build a dashboard that is fed from Snowflake!
Your Tableau + Snowflake Journey
We hope you enjoyed this article and found compelling reasons to explore Tableau + Snowflake as part of your stack. If you’re looking for an expert in these technologies to help guide you, let InterWorks help. A top partner of both solutions, we are uniquely equipped to support you in navigating your analytics challenges. We’re also implementation and enablement leaders and offer events all over the world led by experts in analytics, data engineering and more. If we can assist you, don’t hesitate to email me or contact us today!