
This series takes you from zero to hero with the latest and greatest cloud data warehousing platform, Snowflake.
Snowflake is a versatile powerhouse of cloud-based data storage. As in previous posts, I want to start this blog by reviewing the types of structured and semi-structured data that Snowflake can support:
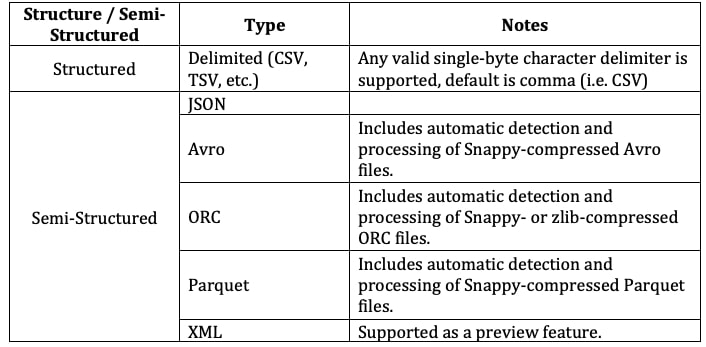
*Note: The XML preview feature link can be accessed here
As always, an updated list of supported file formats can be found in Snowflake’s documentation. As I’ve also mentioned in previous posts, it’s crucial that Snowflake understand how to read the data that it is ingesting. If, for some reason, it does not, errors both minor and major can result.
Data can be stored in many different formats. In the previous post in this series, we discussed structured CSV files. CSV is one of the most commonly used data formats; it is a structured approach where chosen characters are used to separate a text file into columns and rows. In that same blog post, we also discussed text qualifiers and escape characters; these will be referenced again in this post.
A Brief Introduction to JSON
JSON files are a standard output for data storage, processing or construction tools. Among many others, the following softwares and services all ingest and output JSON data natively:
- Application Program Interfaces (APIs) such as:
- Data transformation tools such as:
- Matillion
- Alteryx
- SQL Server Integration Services
- Data visualisation tools such as:
- Tableau
- Power BI
- Looker
- Languages such as:
- Python
- JavaScript
- R
JSON Data Structures
Consider the following table of data:
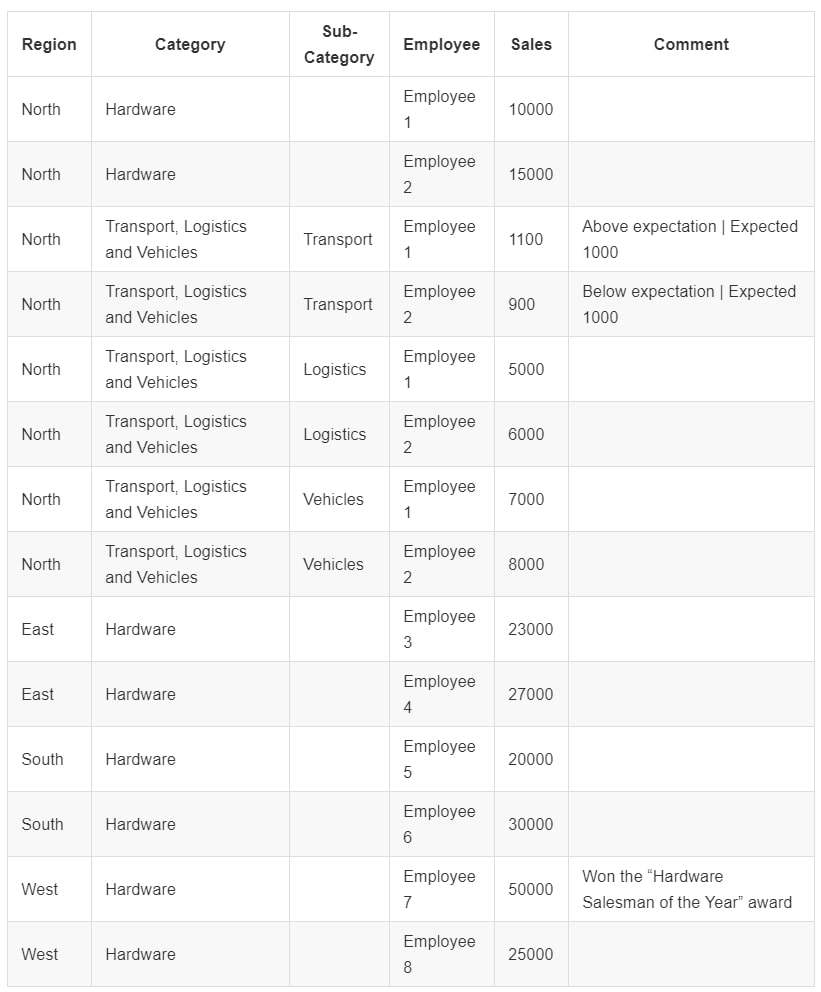
This can be stored in a CSV format such as the following:
"Region"|"Category"|"Sub-Category"|"Employee"|"Sales"|"Comment" "North"|"Hardware"||"Employee 1"|"10000"| "North"|"Hardware"||"Employee 2"|"15000"| "North"|"Transport, Logistics and Vehicles"|"Transport"|"Employee 1"|"1100"|"Above expectation | Expected 1000" "North"|"Transport, Logistics and Vehicles"|"Transport"|"Employee 2"|"900"|"Below expectation | Expected 1000" "North"|"Transport, Logistics and Vehicles"|"Logistics"|"Employee 1"|"5000"| "North"|"Transport, Logistics and Vehicles"|"Logistics"|"Employee 2"|"6000"| "North"|"Transport, Logistics and Vehicles"|"Vehicles"|"Employee 1"|"7000"| "North"|"Transport, Logistics and Vehicles"|"Vehicles"|"Employee 2"|"8000"| "East"|"Hardware"||"Employee 3"|"23000"| "East"|"Hardware"||"Employee 4"|"27000"| "South"|"Hardware"||"Employee 5"|"20000"| "South"|"Hardware"||"Employee 6"|"30000"| "West"|"Hardware"||"Employee 7"|"50000"|"Won the \"Hardware Salesman of the Year\" award "West"|"Hardware"||"Employee 8"|"25000"|
However, this may not be the best way to store this data, especially as the data grows in size. As structured data is columnar, every data point for every column is included in the file. This can result in a lot of repetition, i.e. storing the same region and category multiple times on different lines.
The columnar approach to storage also includes empty or NULL values, such as in the partially-populated Comment field. Furthermore, the data may contain fields which are only populated under certain conditions. For example, our data contains a Sub-Category field that is only populated for the category Transport, Logistics and Vehicles.
As the data volume grows, these could each result in repetition and wasted space in the file. Whilst each occurrence may be minimal, this can compound into files that are larger than necessary and have high rates of redundancy.
Taking a Semi-Structured Approach
An alternative way to store this data would be using a semi-structured approach, in which data is aggregated where possible, and only fields with values are provided. We will now follow a series of steps to convert this file into a semi-structured format. These steps are not how the file itself is created but are intended to demonstrate the logic behind why the file is created as it is.
We begin by removing the columnar nature of the data, converting each row into its own miniature dataset of field names and field values. For example, the first row of our data can be written as follows:
{
"Region" : "North",
"Category" : "Hardware",
"Sub-Category" : "",
"Employee" : "Employee 1",
"Sales" : 10000,
"Comment" : ""
}
Each field of the data is provided as a field name and field value. We call this the key and the value respectively, and we call the entry a key value pair. The information is contained with a set of curly brackets { } to denote the set of key value pairs, called an object.
Already, we can see some empty fields, namely Sub-Category and Comment. Since these are empty anyway, we can decide to exclude them completely:
{
"Region" : "North",
"Category" : "Hardware",
"Employee" : "Employee 1",
"Sales" : 10000
}
We can repeat this process for each row of data. Below is the second row of data demonstrating this:
{
"Region" : "North",
"Category" : "Hardware",
"Employee" : "Employee 2",
"Sales" : 15000
}
By using square brackets [ ], a list can be defined and used to combine our two objects, along with introducing a third:
[
{
"Region" : "North",
"Category" : "Hardware",
"Employee" : "Employee 1",
"Sales" : 10000
},
{
"Region" : "North",
"Category" : "Hardware",
"Employee" : "Employee 2",
"Sales" : 15000
},
{
"Region" : "East",
"Category" : "Hardware",
"Employee" : "Employee 3",
"Sales" : 23000
}
]
We now have three rows of data contained within a list, with each row written as a set of key value pairs. This list is called an array. At this stage, it would be beneficial if we could avoid the repetition in Region and Category. The first step to achieve this is to place these keys above the rest in our structure. We start by moving Employee and Sales into a lower object called EmployeeSales:
[
{
"Region" : "North",
"Category" : "Hardware",
"EmployeeSales" : {
"Employee" : "Employee 1",
"Sales" : 10000
}
},
{
"Region" : "North",
"Category" : "Hardware",
"EmployeeSales" : {
"Employee" : "Employee 2",
"Sales" : 15000
}
},
{
"Region" : "East",
"Category" : "Hardware",
"EmployeeSales" : {
"Employee" : "Employee 3",
"Sales" : 23000
}
}
]
Now that the EmployeeSales object is provided as its own key value pair, we can use the same array notation to aggregate by Region and Category:
[
{
"Region" : "North",
"Category" : "Hardware",
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 10000
},
{
"Employee" : "Employee 2",
"Sales" : 15000
}
]
},
{
"Region" : "East",
"Category" : "Hardware",
"EmployeeSales" : [
{
"Employee" : "Employee 3",
"Sales" : 23000
}
]
}
]
On first glance, this can be a confusing jump. We have converted EmployeeSales into an array of objects, so that Region and Category only need to be provided once whilst each occurrence of Employee and Sales is listed beneath.
By expanding this idea of arrays and objects of key value pairs, the entire Hardware dataset can be aggregated first by Category, then by Region, and converted into this semi-structured format:
[
{
"Category" : "Hardware",
"Regions" : [
{
"Region" : "North",
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 10000
},
{
"Employee" : "Employee 2",
"Sales" : 15000
}
]
},
{
"Region" : "East",
"EmployeeSales" : [
{
"Employee" : "Employee 3",
"Sales" : 23000
},
{
"Employee" : "Employee 4",
"Sales" : 27000
}
]
},
{
"Region" : "South",
"EmployeeSales" : [
{
"Employee" : "Employee 5",
"Sales" : 20000
},
{
"Employee" : "Employee 6",
"Sales" : 30000
}
]
},
{
"Region" : "West",
"EmployeeSales" : [
{
"Employee" : "Employee 7",
"Sales" : 50000,
"Comment" : "Won the \"Hardware Salesman of the Year\" award"
},
{
"Employee" : "Employee 8",
"Sales" : 25000
}
]
}
]
}
]
Whilst this is initially confusing to look at, it is a far more efficient approach in regard to data storage. No entries are repeated, and no space is wasted on empty values. For example, the comment for Employee 7 in the West region has been provided without needing to enter a comment for each object.
It remains to handle the Transport, Logistics and Vehicles category, which breaks down into sub-categories. The structure that we have built should be the same throughout the whole file, which leaves us with a decision to make. Our options include:
- Add the sub-category to the objects within the EmployeeSales array, allowing for a small amount of repetition
- Aggregate by sub-category, changing our existing structure and adding a new level
- Other options are available based on personal preference
We will proceed with the second option and aggregate by sub-category. This changes our entire structure to first aggregate by category then by region and finally by sub-category.
Notice how the Hardware category does not have any sub-categories, instead passing through the Sub-Categories array straight into the EmployeeSales array:
[
{
"Category" : "Transport, Logistics and Vehicles",
"Regions" : [
{
"Region" : "North",
"Sub-Categories" : [
{
"Sub-Category" : "Transport",
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 1100,
"Comment" : "Above expectation | Expected 1000"
},
{
"Employee" : "Employee 2",
"Sales" : 900,
"Comment" : "Below expectation | Expected 1000"
}
]
},
{
"Sub-Category" : "Logistics",
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 5000
},
{
"Employee" : "Employee 2",
"Sales" : 6000
}
]
},
{
"Sub-Category" : "Vehicles",
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 7000
},
{
"Employee" : "Employee 2",
"Sales" : 8000
}
]
}
]
}
]
},
{
"Category" : "Hardware",
"Regions" : [
{
"Region" : "North",
"Sub-Categories" : [
{
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 10000
},
{
"Employee" : "Employee 2",
"Sales" : 15000
}
]
}
]
},
{
"Region" : "East",
"Sub-Categories" : [
{
"EmployeeSales" : [
{
"Employee" : "Employee 3",
"Sales" : 23000
},
{
"Employee" : "Employee 4",
"Sales" : 27000
}
]
}
]
},
{
"Region" : "South",
"Sub-Categories" : [
{
"EmployeeSales" : [
{
"Employee" : "Employee 5",
"Sales" : 20000
},
{
"Employee" : "Employee 6",
"Sales" : 30000
}
]
}
]
},
{
"Region" : "West",
"Sub-Categories" : [
{
"EmployeeSales" : [
{
"Employee" : "Employee 7",
"Sales" : 50000,
"Comment" : "Won the \"Hardware Salesman of the Year\" award"
},
{
"Employee" : "Employee 8",
"Sales" : 25000
}
]
}
]
}
]
}
]
There are other ways we could have achieved this, including potentially aggregating the data in another way or using a different format. However, this is an example of a complete semi-structured data format.
This particular approach in which we utilise arrays, objects and key value pairs is the basis for a format called JSON. This is one of many semi-structured data formats and is supported by Snowflake along with other formats including Avro, ORC, Parquet and XML.
A current list of supported semi-structured file formats can be found in Snowflake’s Introduction to Semi-Structured Data.
How Does Snowflake Load JSON Data?
The above is a brief introduction to semi-structured JSON data. Specific file formats can be far more nuanced than this, and Snowflake is fully equipped to read these file formats. Before I highlight the key file format options that relate to the approaches we’ve discussed, I would like to note that the full and up-to-date list of file format options can be found in Snowflake’s JSON documentation.
We begin by building out the basic building blocks of a file format creation statement. It is also good practice to always enter a comment:
CREATE OR REPLACE FILE FORMAT MY_JSON_FORMAT
TYPE = 'JSON'
COMMENT = 'Demonstration file format for JSON with default settings'
;
When loading JSON data into a table in Snowflake, each object in the top layer of the file becomes its own row in the table. This often does not immediately agree with the JSON file format being loaded. Let’s use the JSON file we just constructed as an example. Here it is again; however, we have simplified the view by collapsing the lower objects:
[
{
"Category" : "Transport, Logistics and Vehicles",
"Regions" : [...]
},
{
"Category" : "Hardware",
"Regions" : [...]
}
]
The entire structure is included in a single list [], resulting in the entire structure loading into a single row in Snowflake. Visually, it would appear as a table like this:

By using the STRIP_OUTER_ARRAY option, it is possible to remove this initial array and treat each object in the array as a row in Snowflake:

As our example dataset is relatively simple and clean, this is the only change we need to make to prepare our file format in Snowflake:
CREATE OR REPLACE FILE FORMAT MY_JSON_FORMAT
TYPE = 'JSON'
STRIP_OUTER_ARRAY = TRUE
COMMENT = 'Demonstration file format for JSON'
;
Depending on the data being used, we may need to employ further Snowflake options when preparing the file format.
Summary
JSON structures are an advanced method for storing data, and Snowflake is fully equipped to handle this through the use of File Formats. Using the steps above, it is possible to provide Snowflake with the understanding of how to interpret a given JSON file. Once the data is staged, Snowflake has an excellent functionality for directly querying semi-structured data along with flattening it into a columnar structure. We will be demonstrating how JSON data can be loaded and queried in the next blog in our series, so come back next week for more.