
This series shows you the various ways you can use Python within Snowflake.
Snowpark for Python is the name for the new Python functionality integration that Snowflake has recently developed. At the Snowflake Summit in June 2022, Snowpark for Python was officially released into Public Preview, which means anybody is able to get started using Python in their own Snowflake environment.
I would understand if you wanted to skip this post and cut directly to the Snowflake’s monolithic documentation page; however, I would strongly recommend reading through this post first, along with my other definitive guides for Python and Snowflake, as these posts will give you an introduction to both the possibilities and limitations of this new functionality whilst walking you through how to get going yourself. In this post, we will walk through the steps you can take to create your own Python User Defined Function, or Python UDF for short, by connecting to Snowflake as part of an external Python script using the Snowpark for Python package.
If you are not interested in connecting to Snowflake and instead wish to simply dive into creating Python UDFs and Stored Procedures from within the Snowflake User Interface, then I would recommend these posts:
- A Definitive Guide to Python UDFs in the Snowflake UI
- A Definitive Guide to Python Stored Procedures in the Snowflake UI
If you are interested in finding out about Python UDFs instead of Stored Procedures, be sure to check out my matching Definitive Guide to Creating Python UDFs in Snowflake Using Snowpark.
Why Define and Leverage a Python Stored Procedure Through Snowpark Instead of the Snowflake UI?
As is made clear in my previous blog posts, you can create Python Stored Procedures directly within the Snowflake UI instead of connecting with Snowpark. However, there are a few benefits to using Snowpark instead:
- Use your IDE of choice to develop your Python functions instead of relying on the Snowflake UI, especially when facilitating access to users who may not be familiar with Snowflake but are familiar with Python
- More freedom to leverage Git and other tools to maintain and deploy Python functions, especially if the same functions are used elsewhere in your technology stack
- Directly create and leverage Python functions from within wider Python scripts outside of Snowflake whilst still pushing the compute down to Snowflake when calling functions
A Warning Regarding Staged Files and Libraries
It is important to note at this time that Stored Procedures do not have access to the “outside world.” This is a security restriction put in place by Snowflake intentionally. If you wish to create a Stored Procedure that accesses the outside world, for example to hit an API using the requests library, then it is recommended to use external functions instead.
Requirements
This post focuses on leveraging Snowflake Snowpark Sessions from the Snowpark for Python package to connect to Snowflake and create Python Stored Procedures. If you haven’t already, I would recommend reading my Definitive Guide to Snowflake Sessions with Snowpark for Python as this will give you a strong introduction into setting up a Snowpark environment to connect to Snowflake and provide you with a few shortcuts in the form of code snippets.
Throughout this blog post, I will always use the variable snowpark_session to refer to a Snowflake Snowpark Session that we have established using the above-mentioned post.
How to Create Your Own Python Stored Procedure from a Snowflake Snowpark Session
Snowflake have integrated the ability to create Python Stored Procedures directly into the standard commands that can be executed for a Snowflake Snowpark Session object. Here is a sample Python code to demonstrate how to create your own Stored Procedure using Snowpark.
This could easily be overwhelming at this stage, so we will follow this template’s description with some examples, starting off simple and getting more complex as we go.
This template includes lines regarding optional packages and imports that will be discussed after our simple examples
# Define Python function locally
def <name of main Python function>(snowpark_session: snowflake.snowpark.Session, <arguments>):
# Python code to determine the main
# functionality of the UDF.
# This ends with a return clause:
return <function output>
# Import data type for returned value
from snowflake.snowpark.types import <specific Snowpark DataType object>
# Optional: Import additional data types
from snowflake.snowpark.types import <specific Snowpark DataType object>
# Optional: Import additional packages or files
snowpark_session.add_packages('<list of required packages natively available in Snowflake (i.e. included in Anaconda Snowpark channel)>')
snowpark_session.add_import('<path\\to\\local\\directory\\or\\file>')
# Upload Stored Procedure to Snowflake
snowpark_session.sproc.register(
func = <name of main Python function>
, return_type = <specific Snowpark DataType object for returned value>
, input_types = [snowpark_session, <list of input DataType() objects for input parameters>]
, is_permanent = True
, name = '<Stored Procedure name>'
, replace = True
, stage_location = '@<Stored Procedure stage name>'
<optional: , execute_as = 'CALLER'>
)
The main elements to understand here are:
- On rows 2-6, we define the main Python function that will be leveraged by our Stored Procedure. This function can leverage other functions that you have defined in your script or imported from elsewhere; however, the Stored Procedure can only be assigned a single main Python function.
- An additional argument called “snowpark_session” is also included on row 2 before the other arguments. This is the active Snowflake session being used by
snowflake-snowpark-pythonand is passed into our function so that we can directly interact with Snowflake objects within our Stored Procedure, for example to execute SQL queries. We specify that this object is asnowflake.snowpark.Sessionclass. - On rows 19-27, we leverage the
sproc.register()method of the Snowflake Snowpark Session object to create a new Stored Procedure in Snowflake. - On row 20, we determine the Python function that will be leveraged by our Stored Procedure. The name here would match the function name on row 2.
- On row 24, we determine the name of the Stored Procedure within Snowflake. You can pass a fully qualified name here if you prefer, otherwise the Stored Procedure will be created in the same namescace as your Snowflake Snowpark Session object.
- On row 26, we determine the name of the Snowflake stage to which the files for our Stored Procedure will be uploaded.
- On row 9, we import the specific Snowpark DataType object that will be used for the value returned by the Stored Procedure. This is discussed more in a note below.
- On row 21, we determine the specific Snowpark DataType object that will be used for the value returned by the Stored Procedure. This would match that which we imported on row 9.
- On row 10, we have an optional import for any additional specific Snowpark DataType objects that will be used for the inputs to our Stored Procedure. If required, there may be more than one additional line here.
- On row 22, we determine the list of specific Snowpark DataType object that will be used for the input arguments for the Stored Procedure. All of these must be included in the imports on rows 9 and 12.
- Notice how row 22 does not include the additional argument “snowflake_session”, as this is implicitly understood in the underlying mechanism of the
sproc.register()method. - On rows 15 and 16, we provide optional rows to add additional packages and imports to our Stored Procedure. This will be discussed after our simple examples.
- On row 23, we determine that the Stored Procedure we create will not be temporary. A temporary Stored Procedure will only exist within our specific Snowflake Snowpark Session object.
- On row 25, we determine whether or not to overwrite an existing Stored Procedure with the same name. If this is set to
Falseand a Stored Procedure already exists, an error will be returned. - On row 27, we can instruct the Stored Procedure to execute as the CALLER. If this is not speciified, then the default is to execute as the OWNER.
The
execute_asoption was only recently added to thesnowflake.snowpark.pythonpackage in September 2022. If you are experiencing errors when trying to leverage this, you can either update your snowflake.snowpark.python package to the latest version, or you can remove the code that specifies this option and follow up thesnowpark_session.sproc.register()command with asnowpark_session.sql(ALTER PROCEDURE ... EXECUTE AS CALLER).collect()command. The latter command will modify your new Stored Procedure to execute as the caller.
Snowpark DataType Objects
Snowpark must leverage compatible data types for inputs and returned value when creating both UDFs and Stored Procedures. You can find the full list of types in Snowflake’s documentation. The examples provided in this blog leverage several different data types, which should give you a reasonable idea for how to configure your own use-cases.
Simple Examples
Let’s break this down and provide a few simple examples to explain what is happening more clearly. Each of these three examples don’t really have any business being a Stored Procedure instead of a UDF; however, I want to clearly explain how these procedures work in the simplest terms before we move on to the useful examples.
Please note that these examples are deliberately minimalistic in their design and thus do not include any error handling or similar concepts. Best practices would be to prepare functions with error handling capabilities to prevent unnecessary execution and provide useful error outputs to the end user.
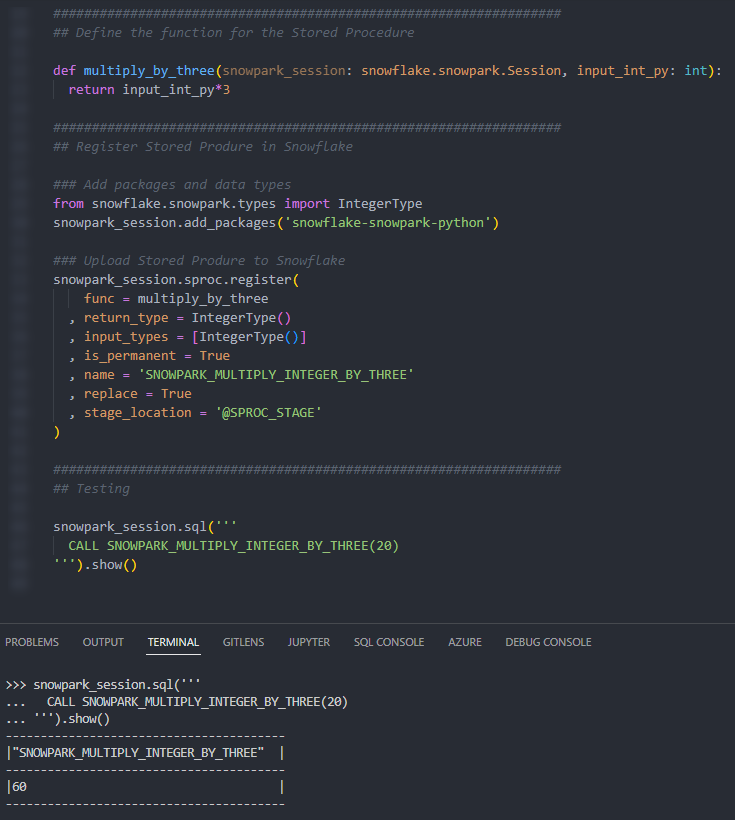
Multiply Input Integer by Three
Our first example is a very simple Stored Procedure that takes an integer and multiples it by three. First, let’s see the code:
There are a few things to break down here to confirm our understanding:
- On rows 4 and 5, we have defined a very simple function in Python which multiples an input number by three.
- The name of our function on row 16 matches that of our Python function defined on row 4.
- On row 12, we added the core
snowflake-snowpark-pythonpackage to our session, so that the Stored Procedure can leverage it. This is required for any Stored Procedure created through Snowpark. - On row 17, we can see that our function will return an integer as it uses
IntegerType(), which we can also see has been imported on row 11. - On row 18, we can see that the input arguments for our function is also an integer using
IntegerType(). This is already imported on row 11.
If we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result.
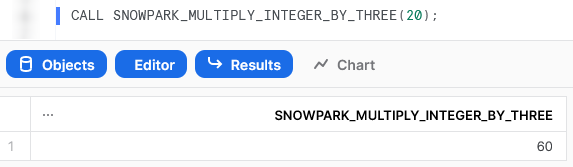
 We can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
We can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
 Multiply Two Input Integers Together
Multiply Two Input Integers Together
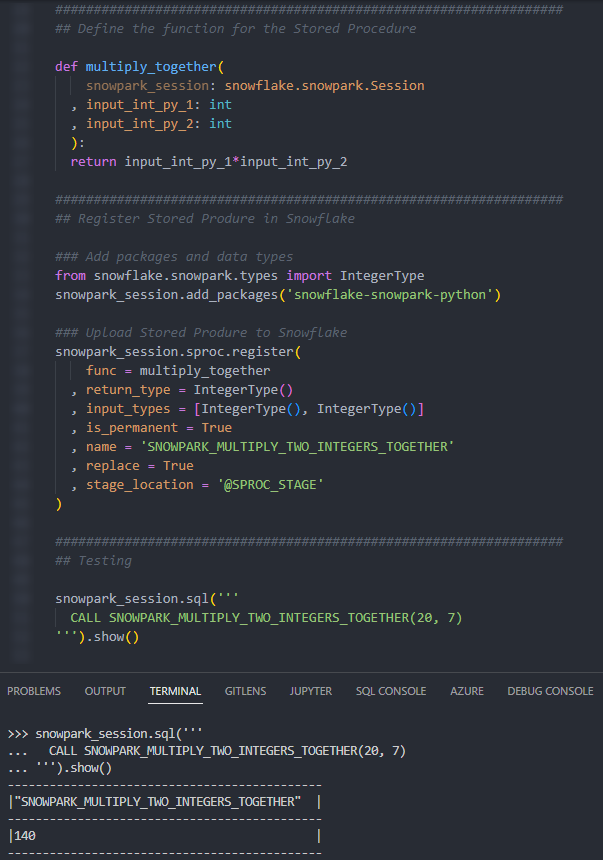
Our second example is another simple function, this time taking two input integers and multiplying them together. Let’s see the code:
##################################################################
## Define the function for the Stored Procedure
def multiply_together(
snowpark_session: snowflake.snowpark.Session
, input_int_py_1: int
, input_int_py_2: int
):
return input_int_py_1*input_int_py_2
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import IntegerType
snowpark_session.add_packages('snowflake-snowpark-python')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = multiply_together
, return_type = IntegerType()
, input_types = [IntegerType(), IntegerType()]
, is_permanent = True
, name = 'SNOWPARK_MULTIPLY_TWO_INTEGERS_TOGETHER'
, replace = True
, stage_location = '@SPROC_STAGE'
)
There are a lot of similarities between this and our previous function; however, this time, we have multiple inputs.
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result.
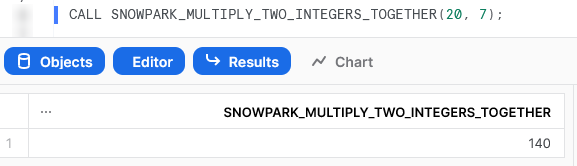
 Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
 Multiply All Integers in an Input Array by Another Integer
Multiply All Integers in an Input Array by Another Integer
The last of our simple examples takes things one step further so that we can introduce an additional Python function in our script and demonstrate the power of list comprehension. This Stored Procedure will accept an array of integers as an input along with a second input of a single integer. The Stored Procedure will multiply all members of the array by that second integer.
Let’s see the code:
##################################################################
## Define the functions for the Stored Procedure
# First define a function which multiplies two integers together
def multiply_together(
a: int
, b: int
):
return a*b
# Define main function which maps multiplication function
# to all members of the input array
def multiply_integers_in_array(
snowpark_session: snowflake.snowpark.Session
, input_list_py: list
, input_int_py: int
):
# Use list comprehension to apply the function multiply_together_py
# to each member of the input list
return [multiply_together(i, input_int_py) for i in input_list_py]
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import ArrayType
from snowflake.snowpark.types import IntegerType
snowpark_session.add_packages('snowflake-snowpark-python')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = multiply_integers_in_array
, return_type = ArrayType()
, input_types = [ArrayType(), IntegerType()]
, is_permanent = True
, name = 'SNOWPARK_MULTIPLY_ALL_INTEGERS_IN_ARRAY'
, replace = True
, stage_location = '@SPROC_STAGE'
)
There are several things to note here:
- On row 33, we can see that we are now expecting an array as an output instead of an integer. To support this, we leverage the
ArrayType(), which is imported on row 26. - On row 27, we must still import the
IntegerType()as this is leveraged in our list of inputs on row 32. - On rows 5-9, we are defining a second Python function called
multiply_together, which is leveraged by our main function that we define on rows 13-20. This is not strictly needed as we could use a lambda function; however, I have included it to demonstrate the functionality. - On row 20, we use the concept of list comprehension to apply our
multiply_together_pyfunction to every member of our input array
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result.
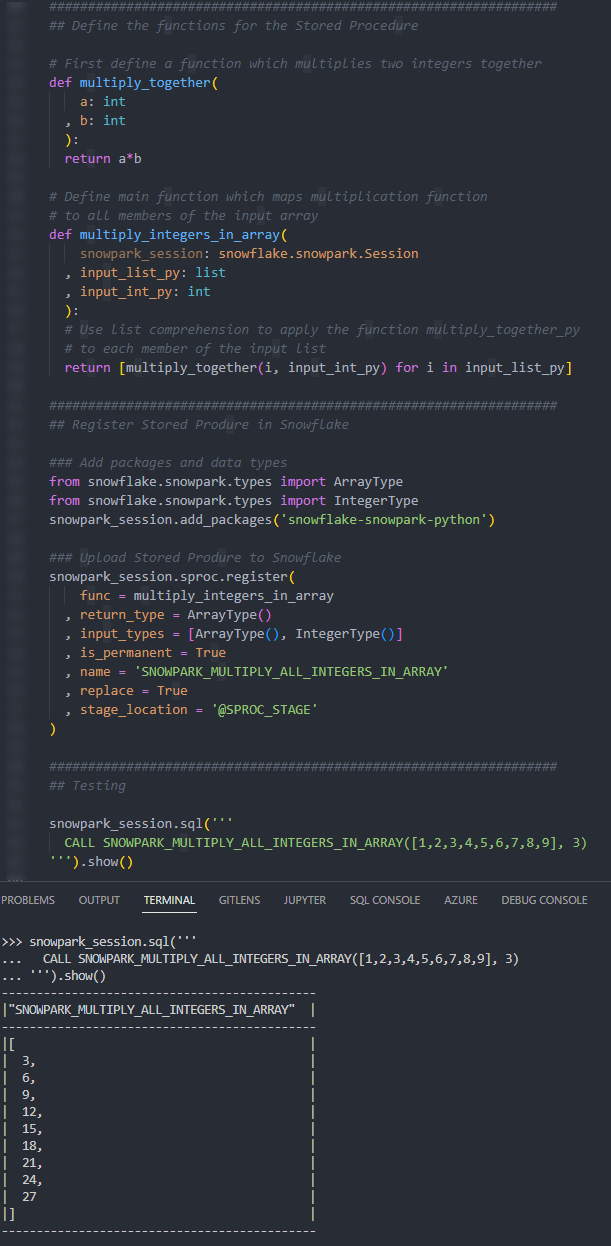
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
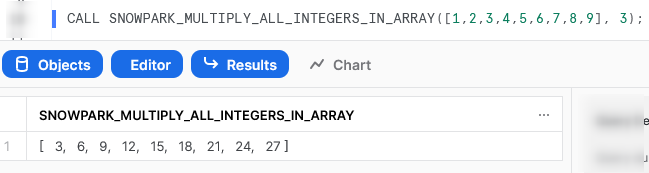 Interacting with Snowflake Within a Stored Procedure
Interacting with Snowflake Within a Stored Procedure
We have now covered the basics around Stored Procedure creation; however, we haven’t constructed anything particularly useful since our examples so far would all be better suited as UDFs. It is now time to change that as we investigate some examples that directly interact with Snowflake.
Simple Examples that Interact with Snowflake
Here are some simple examples that interact with Snowflake. Each will introduce another concept to demonstrate different functionality.
Retrieve Current User and Date
Our first example to interact with Snowflake is a very simple Stored Procedure that executes a SQL statement to retrieve the current user and date. Let’s see the code:
##################################################################
## Define the function for the Stored Procedure
def retrieve_current_user_and_date(snowpark_session: snowflake.snowpark.Session):
## Execute the query into a Snowflake dataframe
results_df = snowpark_session.sql('SELECT CURRENT_USER, CURRENT_DATE')
return results_df.collect()
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import StringType
snowpark_session.add_packages('snowflake-snowpark-python')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = retrieve_current_user_and_date
, return_type = StringType()
, input_types = []
, is_permanent = True
, name = 'SNOWPARK_RETRIEVE_CURRENT_USER_AND_DATE'
, replace = True
, stage_location = '@SPROC_STAGE'
)
There are a few things to break down here to confirm our understanding:
- On row 7, we use the
.sql()method of oursnowpark_sessionconnection to execute our SQL statement and store the results in a Snowflake dataframe calledresults_df. - On row 8, we use the
.collect()method to convert our dataframe object into a string that we can output. This output is actually a list of Snowflake Row objects, but it appears nicely as a list for our requirements. This isn’t a very clean output in this format; however, this is just a simple example to demonstrate the functionality.
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result.
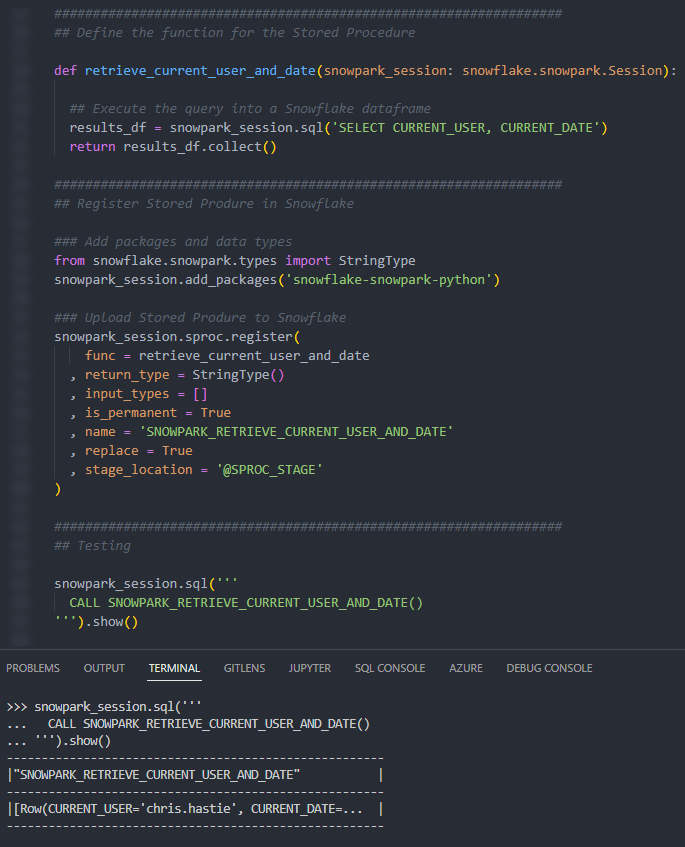
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
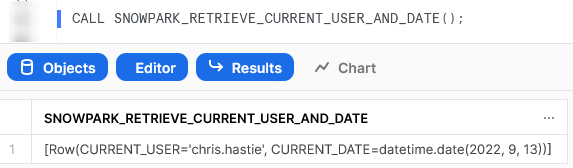 Create and Modify a Table in Snowflake Using the SQL Method
Create and Modify a Table in Snowflake Using the SQL Method
This example expands on our example usage of the .sql() method by demonstrating creating a very simple table and making some changes to it. There is nothing overly complex about this example compared to the last, however it looks more complex upon first sight due to its length. This allows us to demonstrate chaining multiple statements and executing both DDL and DML commands.
Let’s see the code:
##################################################################
## Define the function for the Stored Procedure
def create_and_modify_table_via_sql_method(snowpark_session: snowflake.snowpark.Session):
## Execute the query to create the table
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql('''
CREATE OR REPLACE TABLE MY_TEMP_TABLE (
RECORD_ID INT IDENTITY
, USER_NAME STRING
)
''').collect()
## Execute the query to drop the RECORD_ID field
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql('''
ALTER TABLE MY_TEMP_TABLE
DROP COLUMN RECORD_ID
''').collect()
## Execute the query to add the TIMESTAMP field
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql('''
ALTER TABLE MY_TEMP_TABLE
ADD COLUMN TIMESTAMP STRING
''').collect()
## Execute the query to insert a new record
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql('''
INSERT INTO MY_TEMP_TABLE (USER_NAME, TIMESTAMP)
SELECT CURRENT_USER, CURRENT_TIMESTAMP
''').collect()
## Execute a star select query into a Snowflake dataframe
results = snowpark_session.sql('SELECT * FROM MY_TEMP_TABLE').collect()
## Execute the query to drop the table again
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql('''
DROP TABLE IF EXISTS MY_TEMP_TABLE
''').collect()
return results
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import StringType
snowpark_session.add_packages('snowflake-snowpark-python')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = create_and_modify_table_via_sql_method
, return_type = StringType()
, input_types = []
, is_permanent = True
, name = 'SNOWPARK_CREATE_AND_MODIFY_TABLE_VIA_SQL_METHOD'
, replace = True
, stage_location = '@SPROC_STAGE'
)
The important differences to understand within this examples are:
- The script executes multiple SQL statements in order to create a table, drop a field, add a new field, insert a record, select all records and finally drop the table. This is a simple demonstration of how SQL commands can be executed in order through a Python Stored Procedure
- On rows 19, 27, 35, 43, 46 and 53, we use the
.collect()to actually execute our SQL command in Snowflake. Without this.collect()method, we are only defining a SQL command and not executing it. We do not have to use.collect()specifically to execute SQL commands as any of the action methods will do the same, however.collect()is the simplest to apply for our requirement
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result. Due to the length of the Stored Procedure, I will only screenshot the output.
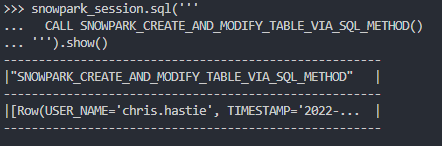
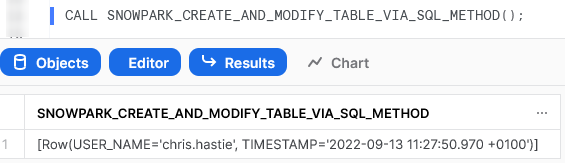
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result. Again, due to the length of the Stored Procedure, I will only screenshot the output.
Create and Modify a Table with a aVriable Input Name in Snowflake Using the SQL Method
This example is very similar to our last example; however, it allows us to demonstrate using variables as part of strings and SQL commands. Let’s see the code:
##################################################################
## Define the function for the Stored Procedure
def using_variables_create_and_modify_table_via_sql_method(
snowpark_session : snowflake.snowpark.Session
, table_name: str
):
# This procedure uses standard python
# string manipulation to leverage variables
# within strings. For example, we can
# insert table_name into a string as follows:
example_string = f'My table name is {table_name}'
## Execute the query to create the table
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql(f'''
CREATE OR REPLACE TABLE {table_name} (
RECORD_ID INT IDENTITY
, USER_NAME STRING
)
''').collect()
## Execute the query to drop the RECORD_ID field
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql(f'''
ALTER TABLE {table_name}
DROP COLUMN RECORD_ID
''').collect()
## Execute the query to add the TIMESTAMP field
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql(f'''
ALTER TABLE {table_name}
ADD COLUMN TIMESTAMP STRING
''').collect()
## Execute the query to insert a new record
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql(f'''
INSERT INTO {table_name} (USER_NAME, TIMESTAMP)
SELECT CURRENT_USER, CURRENT_TIMESTAMP
''').collect()
## Execute a star select query into a Snowflake dataframe
results = snowpark_session.sql(f'SELECT * FROM {table_name}').collect()
## Execute the query to drop the table again
## using ''' for a multi-line string input
## and .collect() to ensure execution on Snowflake
snowpark_session.sql(f'''
DROP TABLE IF EXISTS {table_name}
''').collect()
return results
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import StringType
snowpark_session.add_packages('snowflake-snowpark-python')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = using_variables_create_and_modify_table_via_sql_method
, return_type = StringType()
, input_types = [StringType()]
, is_permanent = True
, name = 'SNOWPARK_USING_VARIABLES_CREATE_AND_MODIFY_TABLE_VIA_SQL_METHOD'
, replace = True
, stage_location = '@SPROC_STAGE'
)
The only difference between this example and the previous one is how we use formatted string literals to leverage a variable within each of our SQL commands.
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result. Again, due to the length of the Stored Procedure, I will only screenshot the output.
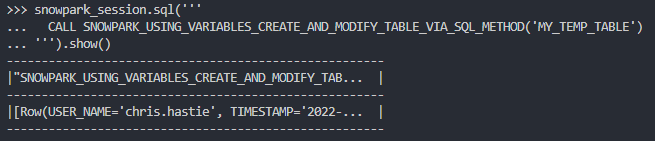
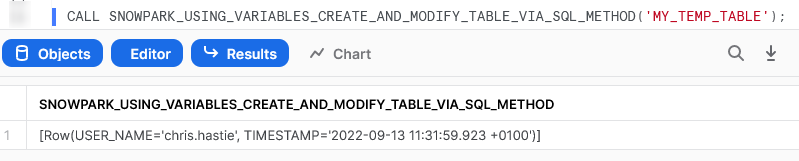
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result. Again, due to the length of the Stored Procedure, I will only screenshot the output.
Execute a Metadata Command (SHOW/LIST/DESCRIBE) into a Table
This example is a lot more interesting than the previous ones, in my opinion. Within this example, we take a metadata command and a destination table as inputs, then execute the metadata command and write the results to the destination table.
Let’s see the code:
##################################################################
## Define the function for the Stored Procedure
def basic_metadata_command_to_table(
snowpark_session: snowflake.snowpark.Session
, metadata_command: str
, destination_table: str
):
## Read the command into a Snowflake dataframe
results_df = snowpark_session.sql(metadata_command)
## Write the results of the dataframe into a target table
results_df.write.mode("overwrite").save_as_table(destination_table)
return f"Succeeded: Results inserted into table {destination_table}"
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import StringType
snowpark_session.add_packages('snowflake-snowpark-python')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = basic_metadata_command_to_table
, return_type = StringType()
, input_types = [StringType(), StringType()]
, is_permanent = True
, name = 'SNOWPARK_BASIC_METADATA_COMMAND_TO_TABLE'
, replace = True
, stage_location = '@SPROC_STAGE'
, execute_as = 'CALLER'
)
### Optionally update stored procedure to execute as CALLER
### if your version of snowflake.snowpark.python does not
### support the execute_as option
snowpark_session.sql('''
ALTER PROCEDURE IF EXISTS SNOWPARK_BASIC_METADATA_COMMAND_TO_TABLE(VARCHAR, VARCHAR) EXECUTE AS CALLER
''').collect()
There are a few things to unpack here:
- On row 34, we have added a clause that forces the Stored Procedure to execute as the caller. By default, Stored Procedures are executed by the owner instead. This is strongly advised and often a strict requirement for metadata commands in Snowflake.
- On row 14, we use the
save_as_table()method of the write property to directly store our results into the destination table. - You may have noticed that we do not use the
.collect()method in this example. We do not need to as thesave_as_table()method of the write property is also on of the action methods. - On rows 37-42, we can see the alternative code that can be used to execute a separate SQL statement that modifies our new Stored Procedure to leverage the EXECUTE AS CALLER option as explained in the information callout below.
The
execute_asoption was only recently added to thesnowflake.snowpark.pythonpackage in September 2022. If you are experiencing errors when trying to leverage this, you can either update your snowflake.snowpark.python package to the latest version, or you can remove the code that specifies this option and follow up thesnowpark_session.sproc.register()command with asnowpark_session.sql(ALTER PROCEDURE ... EXECUTE AS CALLER).collect()command. The latter comman will modify your new Stored Procedure to execute as the caller.
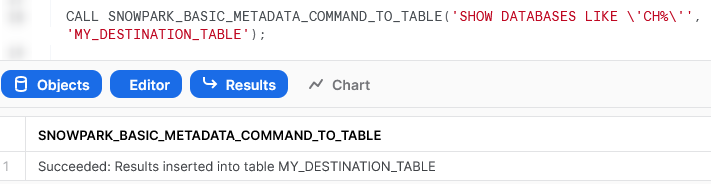
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result.
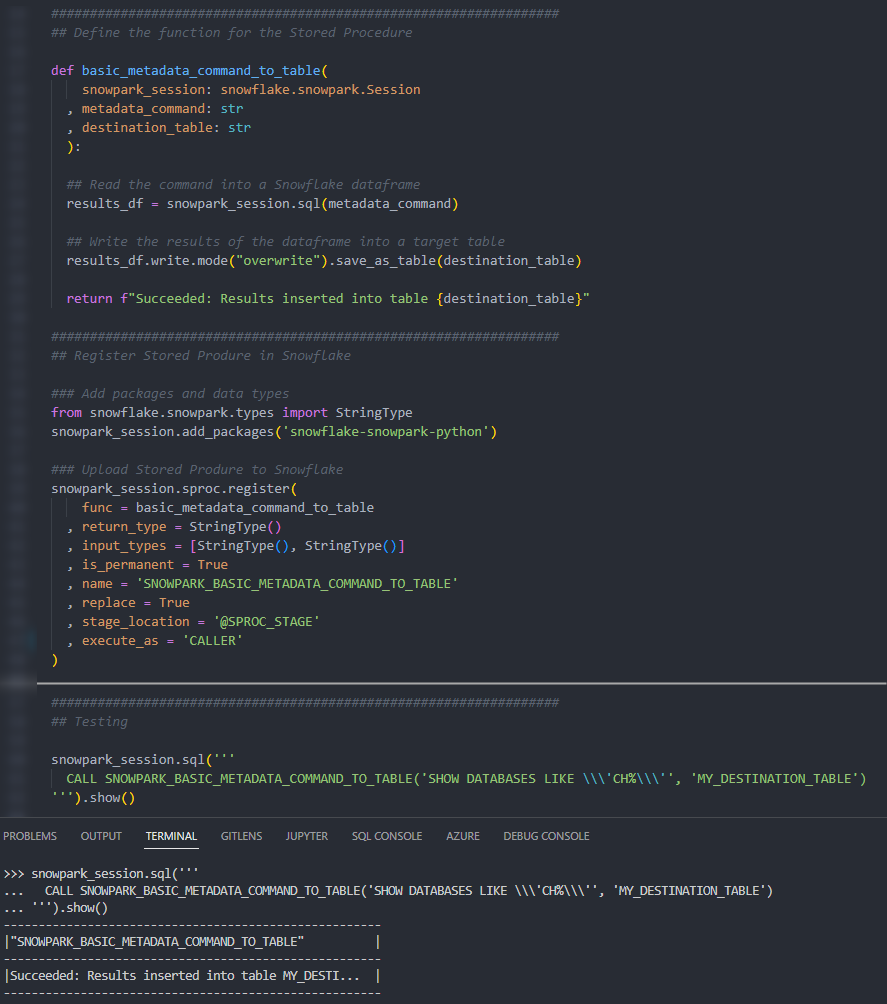
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
Importing Additional Libraries from Anaconda
Even though our examples so far have all been fairly basic, we can already start to see how powerful Pytthon Stored Procedures could be. Not only are we able to receive inputs and use them to produce outputs, we can also define our own functionality within the Python script and perform more complex logical steps when executing our function, storing the results in tables in Snowflake.
What about if we wish to use Python libraries that are not part of the standard inbuilt set? For example, what if we wish to leverage Pandas, PyTorch or a wide range of other popular libraries? The good news here is that Snowflake have partnered with Anaconda and you already have everything you need to leverage any of the libraries listed in Anaconda’s Snowflake channel.
If you wish to leverage any libraries that are not included in Anaconda’s Snowflake channel, including any libraries you have developed in-house, then you will need to import them separately. This will be discussed in the next section.
Accepting the Terms of Usage to Enable Third-Party Packages
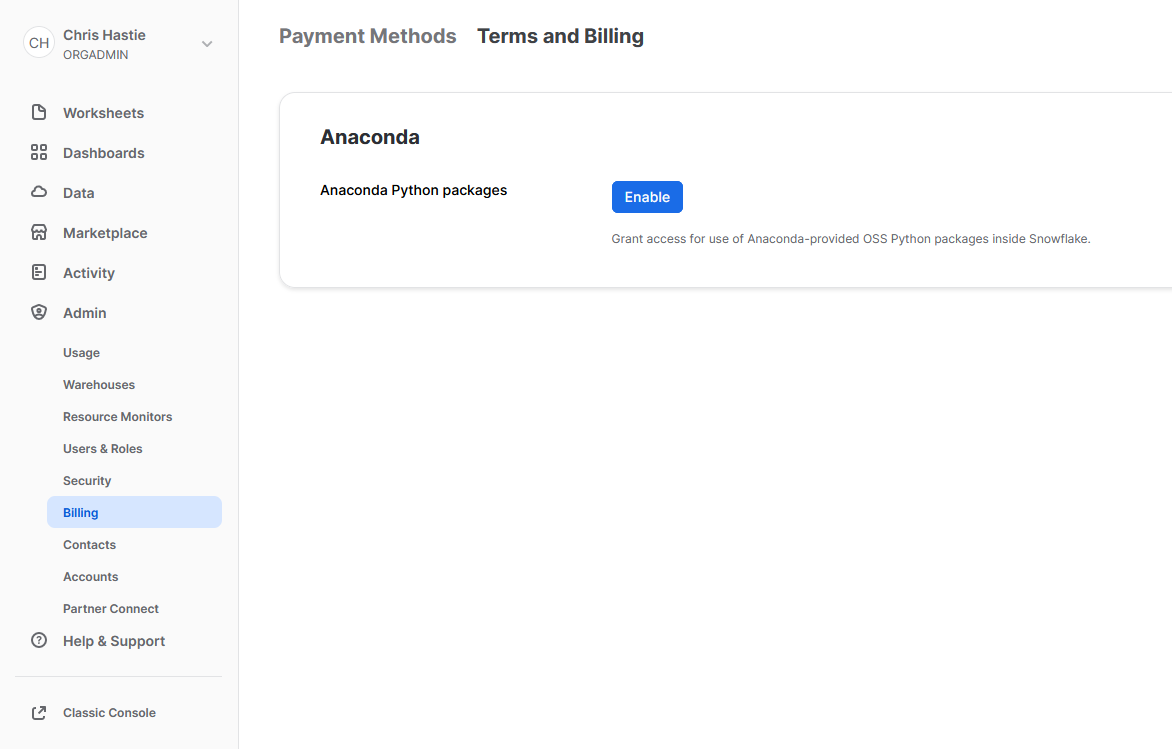
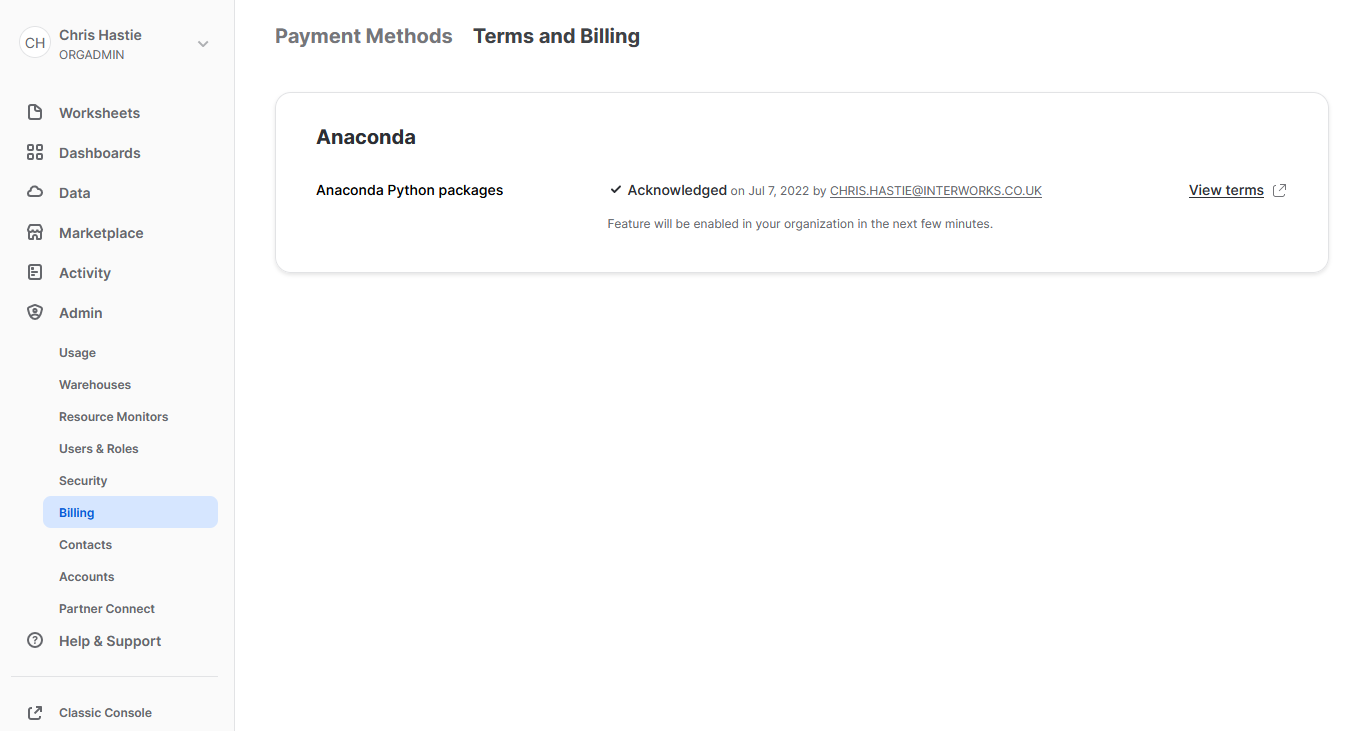
To leverage third party packages from Anaconda within Snowflake, an ORGADMIN must first accept the third-party terms of usage. I walk through the process now; however, more details can be found here for those who desire it. This step must only be completed once for the entire organisation.
- Using the ORGADMIN role in the SnowSight UI, navigate to Admin > Billing to accept the third-party terms of usage.
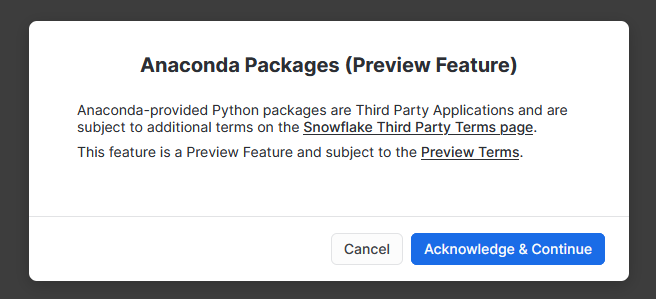
- Confirm acknowledgement.
- The screen will then update to reflect the accepted terms.
Examples Using Supported Third-Party Libraries
Now that we have enabled third-party libraries for our organisation, we can show some more interesting examples.
Manipulate Data in Snowflake Using Pandas
This Stored Procedure demonstrates using Pandas to manipulate data from a table. Specifically, we will use Pandas on the contents of a table to make some minor modifications (a filter) before writing the result to another table.
Let’s see the code:
##################################################################
## Define the function for the Stored Procedure
# Import required modules
import pandas
# Define function
def manipulate_data_with_pandas(
snowpark_session: snowflake.snowpark.Session
, origin_table: str
, destination_table: str
, filter_field: str
, filter_value: str
):
# Read the origin table into a Snowflake dataframe
results_df_sf = snowpark_session.table(origin_table)
# Convert the Snowflake dataframe into a Pandas dataframe
results_df_pd = results_df_sf.to_pandas()
# Filter the Pandas dataframe to databases where the field matches the value
results_df_pd_filtered = results_df_pd[results_df_pd[filter_field] == filter_value]
# Convert the filtered Pandas dataframe into a Snowflake dataframe
results_df_sf_filtered = snowpark_session.create_dataframe(results_df_pd_filtered)
# Write the results of the dataframe into a target table
results_df_sf_filtered.write.mode("overwrite").save_as_table(destination_table)
return f"Succeeded: Results inserted into table {destination_table}"
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import StringType
snowpark_session.add_packages('snowflake-snowpark-python', 'pandas')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = manipulate_data_with_pandas
, return_type = StringType()
, input_types = [StringType(), StringType(), StringType(), StringType()]
, is_permanent = True
, name = 'SNOWPARK_MANIPULATE_DATA_WITH_PANDAS'
, replace = True
, stage_location = '@SPROC_STAGE'
)
The core difference between this Stored Procedure and our previous examples are:
- On row 5, we use standard Python functionality to import the required tools from the
pandaslibrary, which are then leveraged in our Python function. - On row 38, we have now included the
pandaslibrary in the set of packages that we add to our session. - On row 17, we use the
.table()method to read the contents of a Snowflake table into a Snowflake dataframe. - On row 20, we convert a Snowflake dataframe into a Pandas dataframe.
- On row 26, we convert a Pandas dataframe into a Snowflake dataframe.
It is important to note the following according to Snowflake’s own documentation, which prevents us from directly sending results from metadata commands such as SHOW into Pandas:
If you use
Session.sql()with this method, the input query ofSession.sql()can only be a SELECT statement.
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result.
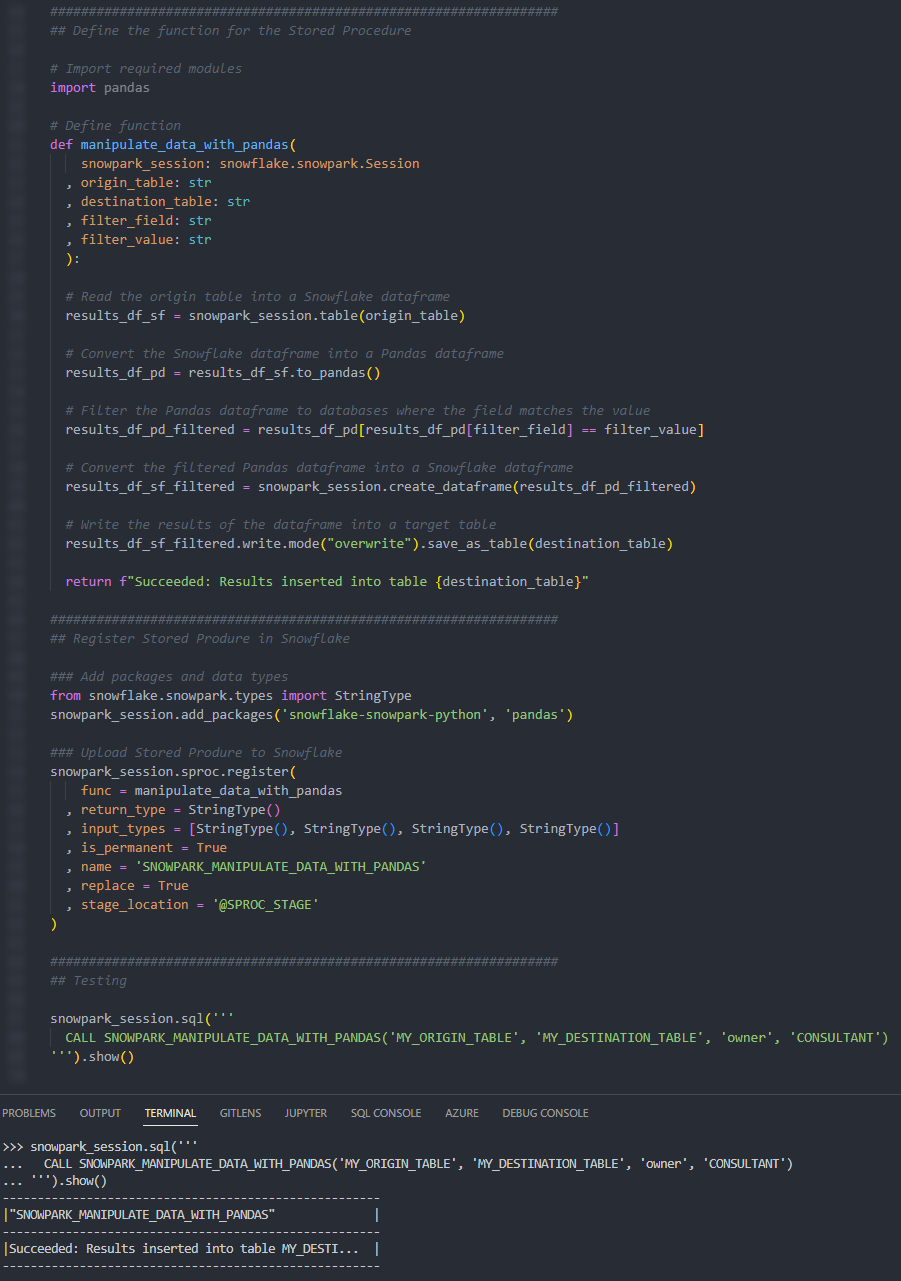
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
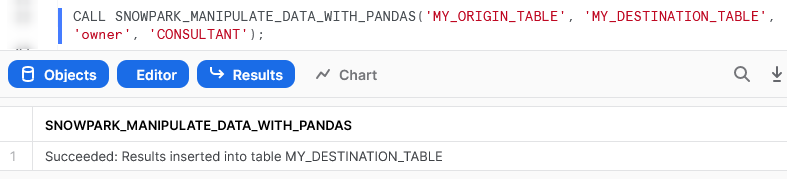
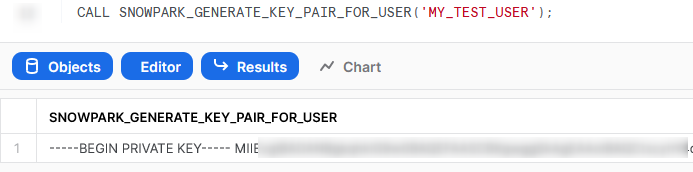
Generate a Snowflake-Compliant Key Pair and Rotate the Keys for a User
This function imports the cryptography library to generate an authentication key pair that is compliant with Snowflake. I have discussed the benefits of this in a previous blog; however, this new Python functionality renders the technical side of this blog redundant!
It is important to note that this specific approach is not best practice as unintended users may be able to access the private key from Snowflake’s history; however, I will resolve this in an upcoming blog post.
Let’s see the code:
##################################################################
## Define the function for the Stored Procedure
# Import the required modules
from cryptography.hazmat.primitives import serialization as crypto_serialization
from cryptography.hazmat.primitives.asymmetric import rsa
import re
# Define function which generates a Snowflake-compliant key pair
def generate_key_pair():
keySize = 2048
key = rsa.generate_private_key(public_exponent=65537, key_size=keySize)
privateKey = key.private_bytes(
crypto_serialization.Encoding.PEM,
crypto_serialization.PrivateFormat.PKCS8,
crypto_serialization.NoEncryption()
)
privateKey = privateKey.decode('utf-8')
publicKey = key.public_key().public_bytes(
crypto_serialization.Encoding.PEM,
crypto_serialization.PublicFormat.SubjectPublicKeyInfo
)
publicKey = publicKey.decode('utf-8')
key_pair = {
"private_key" : privateKey
, "public_key" : publicKey
}
return key_pair
def retrieve_current_public_key_for_user(
snowpark_session: snowflake.snowpark.Session
, username: str
):
# Retrieve user's current key
# using ''' for a multi-line string input
# and formatted string literals to leverage variables
desc_user_df = snowpark_session.sql(f'''
DESCRIBE USER "{username}"
''').collect()
rsa_public_key_value = [row["value"] for row in desc_user_df if row["property"] == 'RSA_PUBLIC_KEY'][0]
return rsa_public_key_value
def rotate_public_key_for_user(
snowpark_session: snowflake.snowpark.Session
, username: str
, old_public_key: str
, new_public_key: str
):
# Parse the new_public_key into the format preferred by Snowflake
# by stripping the start and end clauses
regex_pattern = "-----BEGIN PUBLIC KEY-----\\n(.*)\\n-----END PUBLIC KEY-----\\n?"
result = re.search(regex_pattern, new_public_key, re.S)
new_public_key_parsed = result.group(1)
# Rotate user's current key
# using ''' for a multi-line string input
# and formatted string literals to leverage variables
# and .collect() to ensure execution on Snowflake
if old_public_key is not None \
and len(old_public_key) > 0 \
and old_public_key != 'null' \
:
snowpark_session.sql(f'''
ALTER USER "{username}"
SET RSA_PUBLIC_KEY_2 = '{old_public_key}'
''').collect()
snowpark_session.sql(f'''
ALTER USER "{username}"
SET RSA_PUBLIC_KEY = '{new_public_key_parsed}'
''').collect()
return 0
# Define main function to generate and rotate the key pair for a user
def generate_key_pair_for_user(
snowpark_session: snowflake.snowpark.Session
, username: str
):
new_key_pair = generate_key_pair()
new_public_key = new_key_pair["public_key"]
new_private_key = new_key_pair["private_key"]
old_public_key = retrieve_current_public_key_for_user(snowpark_session, username)
rotate_public_key_for_user(snowpark_session, username, old_public_key, new_public_key)
return new_private_key
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import StringType
snowpark_session.add_packages('snowflake-snowpark-python', 'cryptography')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = generate_key_pair_for_user
, return_type = StringType()
, input_types = [StringType()]
, is_permanent = True
, name = 'SNOWPARK_GENERATE_KEY_PAIR_FOR_USER'
, replace = True
, stage_location = '@SPROC_STAGE'
, execute_as = 'CALLER'
)
### Optionally update stored procedure to execute as CALLER
### if your version of snowflake.snowpark.python does not
### support the execute_as option
snowpark_session.sql('''
ALTER PROCEDURE IF EXISTS SNOWPARK_GENERATE_KEY_PAIR_FOR_USER(VARCHAR) EXECUTE AS CALLER
''').collect()
Similar to our last example, the core difference between this Stored Procedure and our previous examples are:
- On rows 5 and 6, we use standard Python functionality to import the required tools from the
cryptographylibrary, which are then leveraged in our Python function. - On row 38, we have now included the
cryptographylibrary in the set of packages that we add to our session. - On row 115, we have again added a clause that forces the Stored Procedure to execute as the caller. By default, Stored Procedures are executed by the owner instead. This is strongly advised and often a strict requirement for metadata commands in Snowflake.
- On rows 118-123, we can see the alternative code that can be used to execute a separate SQL statement that modifies our new Stored Procedure to leverage the EXECUTE AS CALLER option as explained in the information callout below.
The
execute_asoption was only recently added to thesnowflake.snowpark.pythonpackage in September 2022. If you are experiencing errors when trying to leverage this, you can either update your snowflake.snowpark.python package to the latest version, or you remove the code that specifies this option and follow up thesnowpark_session.sproc.register()command with asnowpark_session.sql(ALTER PROCEDURE ... EXECUTE AS CALLER).collect()command. The latter command will modify your new Stored Procedure to execute as the caller.
This is a much longer Stored Procedure than any of our previous examples, and I will not dive into specifics of the Python script itself. My hope is that this is enough to give readers an idea of importing a package (crytopgraphy) and leveraging it within a Stored Procedure.
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result. Again, due to the length of the Stored Procedure, I will only screenshot the output.
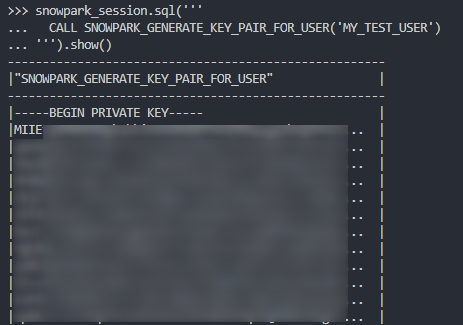
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
Importing Files and Libraries via a Stage
So far, we have demonstrated quite a lot in our miniature crash course into Python Stored Procedures in Snowflake. Before we wrap up, I’d like to cover one last piece, which is how to import libraries that are not covered by the Anaconda Snowflake channel and how to import other external files.
For these examples, we will be uploading all of our required files with the snowpark_session.add_import() method.
Import an External Excel xlsx File
This example reads an Excel xlsx file into a pandas dataframe, then writes the dataframe into a destination table in Snowflake.
The file we will be leveraging is a very simple mapping file that looks like this:
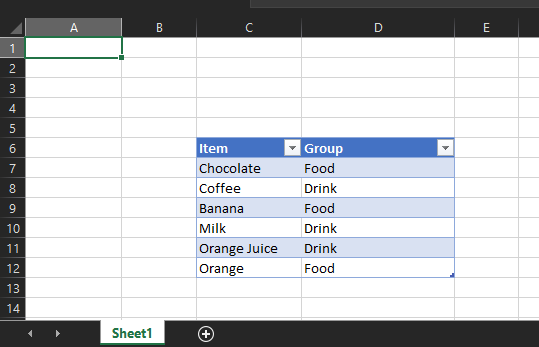
The file is called “Dummy Mapping File.xlsx” and sits on our local machine in the following relative directory path:
Stored Procedures\Supporting Files\
Here is the code for the Stored Procedure itself:
##################################################################
## Define the function for the Stored Procedure
# Import the required modules
import pandas
import sys
# Define main function which leverages the mapping
def leverage_external_mapping_file(
snowpark_session: snowflake.snowpark.Session
, destination_table: str
):
# Retrieve the Snowflake import directory
IMPORT_DIRECTORY_NAME = "snowflake_import_directory"
import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME]
# Read mapping table using Pandas
mapping_df_pd = pandas.read_excel(import_dir + 'Dummy Mapping File.xlsx', skiprows=5, usecols="C:D")
# Convert the filtered Pandas dataframe into a Snowflake dataframe
mapping_df_sf = snowpark_session.create_dataframe(mapping_df_pd)
# Write the results of the dataframe into a target table
mapping_df_sf.write.mode("overwrite").save_as_table(destination_table)
return f"Succeeded: Results inserted into table {destination_table}"
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import StringType
snowpark_session.add_packages('snowflake-snowpark-python', 'pandas', 'openpyxl')
snowpark_session.add_import('Stored Procedures/Supporting Files/Dummy Mapping File.xlsx')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = leverage_external_mapping_file
, return_type = StringType()
, input_types = [StringType()]
, is_permanent = True
, name = 'SNOWPARK_LEVERAGE_EXTERNAL_MAPPING_FILE'
, replace = True
, stage_location = '@SPROC_STAGE'
)
The unique differences for this example are:
- On rows 15 and 16 within our Python function, we leverage the
syslibrary to access the location where Snowflake stores files that have been imported into the UDF. This is potentially the most useful snippet of code in this blog I found it to be the hardest thing to find in the documentation! - Row 35 includes a line to import the file from our local directory into our Snowflake Snowpark Session. This is a critical component for our Python function to be able to access the file during the
pandas.from_excel()function on row 17 - On row 34 we also demonstrate adding multiple packages in a single line.
The rest of the code in this script is specific Python code to download the Excel file into a Pandas dataframe, convert it to a Snowflake dataframe and write it to the destination table.
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result.
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
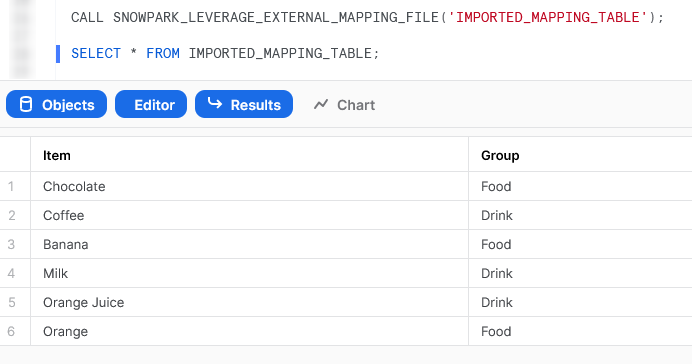
Import an Non-Standard External Library
This example is designed to leverage the xldate function of the xlrd library. This library is not included in the standard set of supported libraries, so it must be imported specifically.
Let’s see the code:
##################################################################
## Define the function for the Stored Procedure
# Import the required modules
import xlrd
# Define main function which leverages the package
def leverage_external_library(
snowpark_session: snowflake.snowpark.Session
, input_int_py: int
):
return xlrd.xldate.xldate_as_datetime(input_int_py, 0)
##################################################################
## Register Stored Produre in Snowflake
### Add packages and data types
from snowflake.snowpark.types import StringType
from snowflake.snowpark.types import IntegerType
snowpark_session.add_packages('snowflake-snowpark-python')
snowpark_session.add_import('Stored Procedures/Supporting Files/xlrd')
### Upload Stored Produre to Snowflake
snowpark_session.sproc.register(
func = leverage_external_library
, return_type = StringType()
, input_types = [IntegerType()]
, is_permanent = True
, name = 'SNOWPARK_LEVERAGE_EXTERNAL_LIBRARY'
, replace = True
, stage_location = '@SPROC_STAGE'
)
The unique differences for this example are:
- Row 22 includes a line to import the package from our local directory into our Snowflake Snowpark Session. This is a critical component for our Python function to be able to access the file during the
xlrd.xldate.xldate_as_datetime()function on row 13.
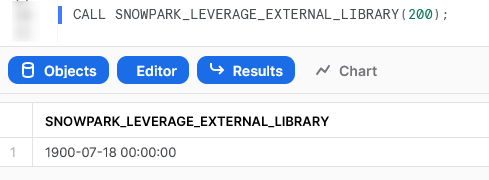
Again, if we execute this code as part of a Python script, we can then execute the Stored Procedure using the snowpark_session.sql().show() method to see the result.
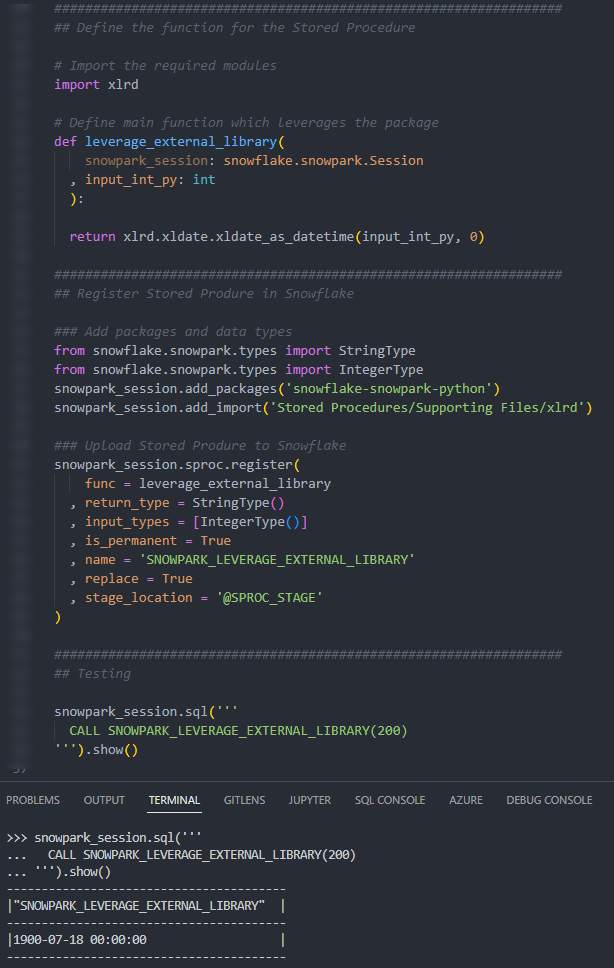
Again, we can also execute the Stored Procedure from within a Snowflake worksheet in the same way that we would any other Stored Procedure to see the result.
Wrap Up
So, there we have it. We have covered a lot of content in this post and some of these Stored Procedures could potentially have their own blog post all on their own! My goal is to demonstrate how to create Stored Procedures for different scenarios and provide that in a single post so that it is easy for readers to find and refer back to if needed.
I hope this helps you get started on your own journey with Python Stored Procedures in Snowflake via Snowpark. Let us know what cool things you come up, it’s always great to see new functionality lead to productive and useful innovation.
If you wish to see the code for all of this, and other content that we have, you can find it on the InterWorks GitHub.
If you are interested in finding out about Python UDFs, be sure to check out my matching Definitive Guide to Creating Python UDFs in Snowflake using SnowPpark.