
Every Snowflake account comes with a shared database called “SNOWFLAKE” which stores a fantastic amount of account-level and organisation-level information. Most notably, this shared database contains a series of account usage views which covers all of the activity that has taken place in the account. This is incredibly useful, however there is one potential risk/flaw with this process:
Data is only retained in the “SNOWFLAKE” shared database for 1 year. After 1 year, this data is no longer available through this shared database.
Fortunately, we can fully backup this database without much difficulty using the stored procedure below.
Required Privileges to Execute the Stored Procedure
This stored procedure must be executed by a role that has:
- CREATE DATABASE privileges on the account.
- IMPORTED PRIVILEGES on the SNOWFLAKE shared database.
- USAGE on a warehouse to execute the queries.
- USAGE on this stored procedure.
I would recommend using a role that is not part of your standard role hierarchy so that the created backup databases do not overcrowd the object explorer for standard users. Some people choose to add the prefix “Z_” to put these backups at the end of the object explorer when sorted alphabetically.
Stored Procedure Overview
The stored procedure itself will perform the following steps:
- Determine the current date and create a new destination database; named in the form “
BACKUP_SNOWFLAKE_SHARE_YYYY_MM_DD.” - Retrieve the metadata for all views in the “
SNOWFLAKE” shared database by querying the table “SNOWFLAKE.INFORMATION_SCHEMA.VIEWS.” - Iterate through each view and create a matching table in the destination database, using statements of the following form to create the tables:
CREATE TABLE "DESTINATION_TABLE"."SCHEMA_NAME"."VIEW_NAME" AS SELECT * FROM "SNOWFLAKE"."SCHEMA_NAME"."VIEW_NAME" ;
As you can see, we are directly querying the views using “SELECT *” statements. Naturally, the resources required to execute this performantly will vary depending on the size of your specific “SNOWFLAKE” shared database. However, I have executed this successfully for several clients using an XS warehouse and found the process to complete in about 10 minutes. There is nothing to stop you from using a larger warehouse if you like.
Stored Procedure Code
I’m sure some readers will have scrolled down straight to this section, so without further ado, here is the code for the stored procedure:
CREATE OR REPLACE PROCEDURE BACKUP_SNOWFLAKE_SHARED_DATABASE()
returns string not null
language python
runtime_version = '3.8'
packages = ('snowflake-snowpark-python')
handler = 'backup_snowflake_shared_database'
execute as caller
as
$$
# Import module for inbound Snowflake session
from snowflake.snowpark import session as snowpark_session
# Import required modules
from datetime import datetime
# Define function to backup a view as a table with CTAS
def backup_view_as_table(
snowpark_session: snowpark_session
, source_view_metadata: dict
, destination_database: str
):
## Create FQNs
source_view_FQN = f'"{source_view_metadata["TABLE_CATALOG"]}"."{source_view_metadata["TABLE_SCHEMA"]}"."{source_view_metadata["TABLE_NAME"]}"'
destination_table_FQN = f'"{destination_database}"."{source_view_metadata["TABLE_SCHEMA"]}"."{source_view_metadata["TABLE_NAME"]}"'
## Determine comment
source_comment = source_view_metadata["COMMENT"]
destination_comment = 'NULL'
if source_comment and len(source_comment) > 0 :
source_comment_as_string = source_comment.replace("'", "\\'")
destination_comment = f"'{source_comment_as_string}'"
## Execute SQL to create a new table via CTAS
## using ''' for a multi-line string input
snowpark_session.sql(f'''
CREATE SCHEMA IF NOT EXISTS "{destination_database}"."{source_view_metadata["TABLE_SCHEMA"]}"
''').collect()
## Execute SQL to create a new table via CTAS
## using ''' for a multi-line string input
snowpark_session.sql(f'''
CREATE TABLE {destination_table_FQN}
AS
SELECT * FROM {source_view_FQN}
''').collect()
## Execute SQL to set the comment
snowpark_session.sql(f'''
ALTER TABLE {destination_table_FQN}
SET COMMENT = {destination_comment}
''').collect()
return
# Define function to create the destination database
def create_destination_database(
snowpark_session: snowpark_session
):
## Determine process timestamp
now = datetime.now()
processed_timestamp = now.strftime("%Y_%m_%d")
## Determine destination database
destination_database = f'BACKUP_SNOWFLAKE_SHARE_{processed_timestamp}'
## Create destination database
## using ''' for a multi-line string input
snowpark_session.sql(f'''
CREATE OR REPLACE DATABASE "{destination_database}"
''').collect()
return destination_database
# Define function to retrieve view metadata from information schema
def retrieve_view_metadata_from_information_schema(
snowpark_session: snowpark_session
):
## Retrieve stage overview details
## using ''' for a multi-line string input
sf_df_view_metadata = snowpark_session.sql(f'''
SELECT * FROM SNOWFLAKE.INFORMATION_SCHEMA.VIEWS
WHERE TABLE_SCHEMA != 'INFORMATION_SCHEMA'
''')
df_view_metadata = sf_df_view_metadata.to_pandas()
view_metadata_list = df_view_metadata.to_dict('records')
return view_metadata_list
# Define main function to backup the SNOWFLAKE shared database
def backup_snowflake_shared_database(
snowpark_session: snowpark_session
):
## Execute function to create and return the destination database
destination_database = create_destination_database(snowpark_session=snowpark_session)
## Execute function to get list of view metadata
view_metadata_list = retrieve_view_metadata_from_information_schema(snowpark_session=snowpark_session)
## Loop over views in list
for view_metadata in view_metadata_list :
### Execute function to backup a view as a table with CTAS
backup_view_as_table(
snowpark_session = snowpark_session
, source_view_metadata = view_metadata
, destination_database = destination_database
)
return 'Complete'
$$
;
This procedure can then be executed with the following simple command:
CALL BACKUP_SNOWFLAKE_SHARED_DATABASE();
The result will be a fresh database as demonstrated in the following screenshot:
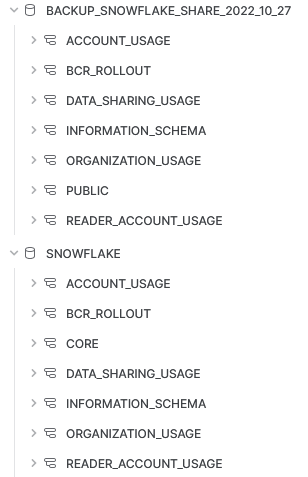
Wrap Up
And there we have it. Short and sweet. I would encourage you to take this a step further and set up a task which automatically triggers this stored procedure at a regular cadence of 6 months, so that you continue to create backups automatically without losing the information after a year.
If you wish to see any more of our Snowflake Python functionality, be sure to check out the repository on GitHub. If you ever want to work with us on Snowflake or other data projects, you can reach out to us here.