
It’s kind of hard keeping track of terms in the world of data. It seems like every time you turn around, there’s a new concept, idea, implementation, tool or even argument about data. To contribute to the confusion, each and every idea is given a new name and every name, it seems, starts with the word “Data.” There is a plurality of data! Data is everywhere! No, technically, data ARE everywhere!
Terms, Jargon, and More
Imagine an episode of the quiz-show “Jeopardy!” where the late, great Alex Trebek gently intones, “This data term can be used whenever you want to confuse your listener.” Just about any response would be correct, there’s so many to choose from. My response would be, “What is Data Yogurt?”
Still, there is merit in understanding the labels. Words mean things, even when they seem to be repeated over and over. I recall the first time I heard of “machine learning.” I thought to myself, “Well, I know what each of those words mean by themselves – what are they supposed to mean put together!?” Too often, we have this same reaction to data terms.
So, let’s figure out what groups the data terms fall into, and how they’re related. It’s time to sort the data! (See what I did there?)
Common Data Terms, Categorized
Here is my modest suggestion for keeping track of the data terms you might run into. It is not an exhaustive list, nor do I claim to have the final word in categorization of these terms. For now, though: print it out, pin it to your monitor or workspace, and you can avoid the confusion of tripping over data definitions daily.
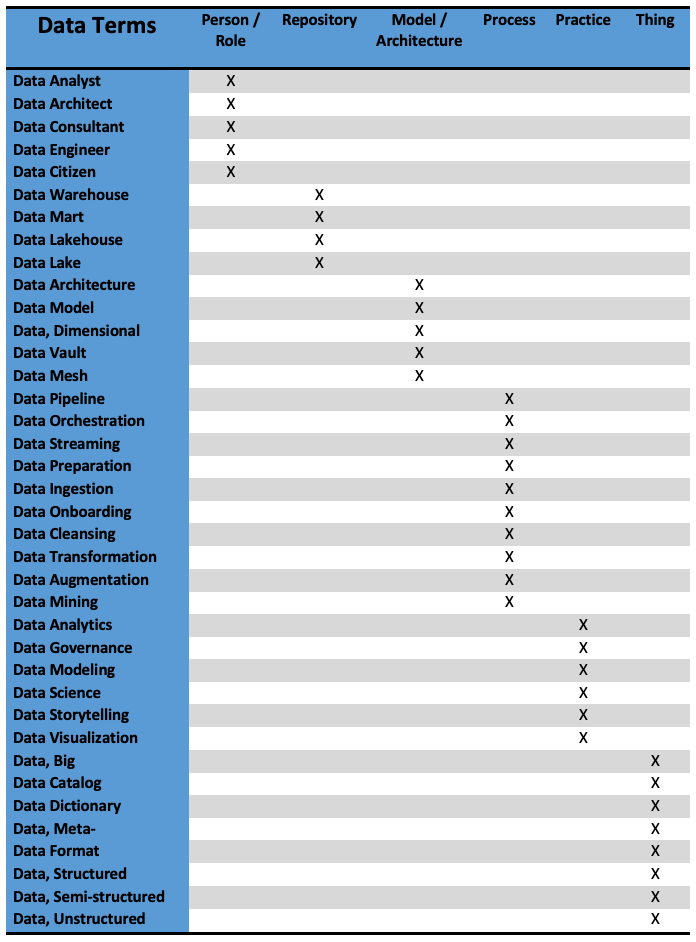
This may be madness, but at least there is method to it. I’m not going to give a detailed definition for every single term, but let’s look at the categories they fall into and see how they fit together.
Persons and Roles
Full disclosure, my job title is “Data Architect,” and I was sorely tempted to put that term first. Altogether, the terms in this category describe the folks who work with, design, define, rework and consume data. Consuming data is especially important to the data analyst and data citizen, whose purpose is to tease some meaning out of the data, either analytically or on an ad-hoc basis. Depending upon who you talk to, data architect and data engineer could be interchangeable, and of course data consultant can be any of the above as well. There is a lot overlap here. I’ve also heard of a “data intern,” but that’s just going too far.
Repositories
If you’ve got data, it needs a place to be stored (unless you’re talking about NULL data — that’s another story.) The data terms for such storage places cover a few different styles, or an amalgam of styles. The data warehouse is typically the central repository of a business’ data, implying a form or structure related to the business analytics. It has a little brother, the data mart, which is a store of data used by a particular group within a company, targeted to their specific need (there’s also a big brother, the Enterprise Data Warehouse or EDW, but we’re not talking about that.)
Meanwhile, the data lake can also be a central repository, but usually in a raw, original, and unformatted form – a somewhat more flexible, if unstructured, format. For some reason, this is often preferred for machine learning. The data lakehouse strives to be a combination of data warehouse and data lake (just smoosh “lake” and “warehouse” together: “lakehouse!”), meaning it strives to provide both analytical and machine learning access, if it can pull it off (it’s a relatively new thing.)
Models and Architectures
Data Models and Data Architectures go together, and can sometimes be confused for one another. A good data architecture design is what defines how information flows – both logically and physically – and governs how it is controlled. Meanwhile a good data model defines and visualizes those data elements and the relationships between them.
You may not have heard of a data mesh, which was proposed only recently. It is a special kind of data architecture that emphasizes separate but cooperating concepts to combine (or mesh) the process of data flow and availability. The concepts used by data mesh are: domain ownership, data as a product, self-serve data platform, and federated governance (more terms! At least they don’t all start with “data”).
Among our data terms we have two types of data models, both of which aid in analysis. The dimensional data model (sometimes called a Kimball-esque model after its creator) emphasizes the relationships between facts or measures in the data and the dimensions or descriptors associated with those facts. This is often illustrated with facts in the middle and dimensions surrounding it – producing a star-shaped diagram called a “Star Schema.” Another model, the data vault model, emphasizes the relationships (or “links”) between the core business concepts within the data; each core concept having its own satellite attributes describing those concepts. This type of modeling is very effective for large data warehouses that need to capture historical changes, integrate data from many sources, and adapt to changes in business rules quickly.
Beware: the term “model” is overused and often overloaded – for instance, there is a data build tool that calls simple SQL queries “models.” This can be brain-wrenching when first encountered.
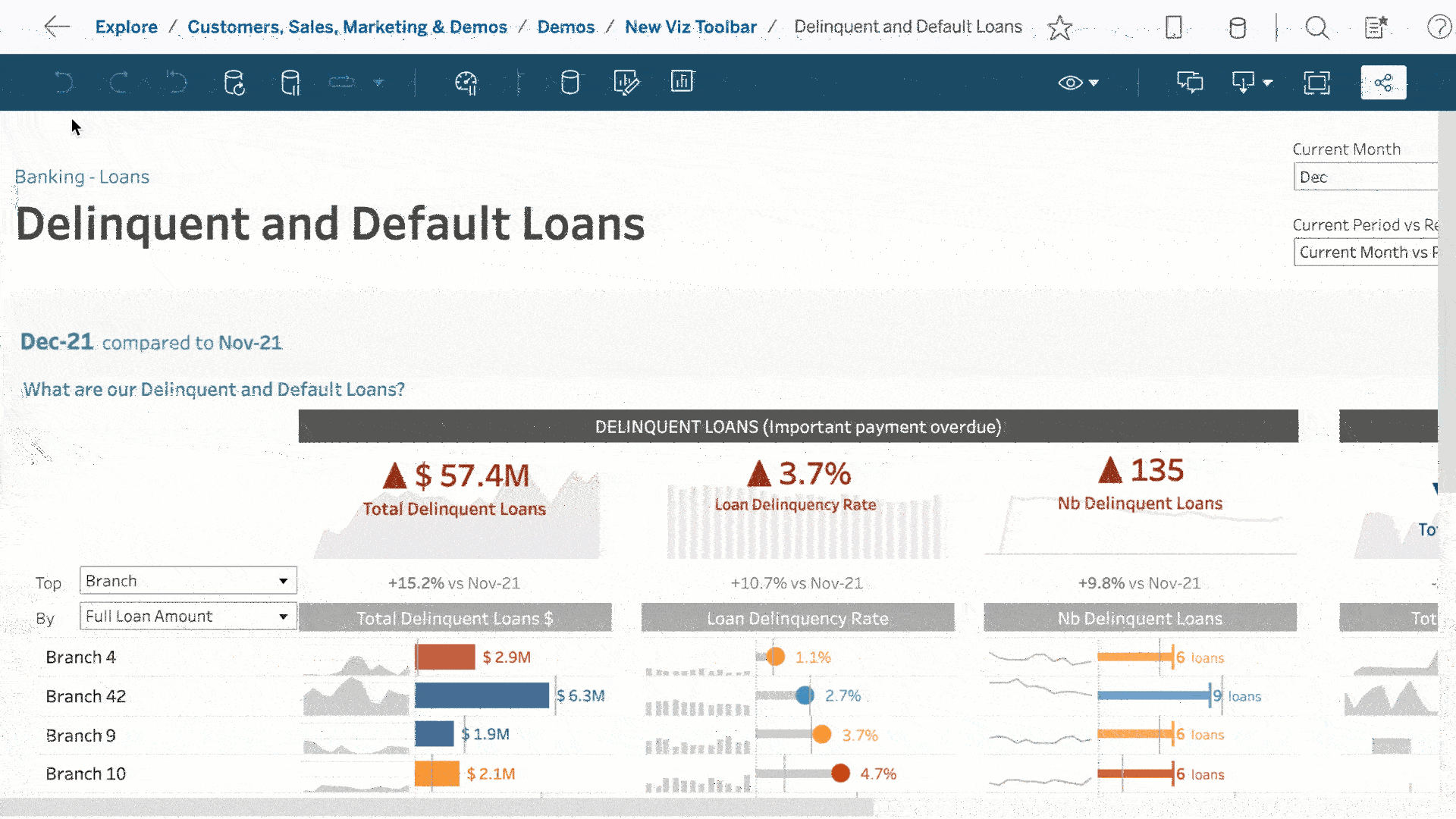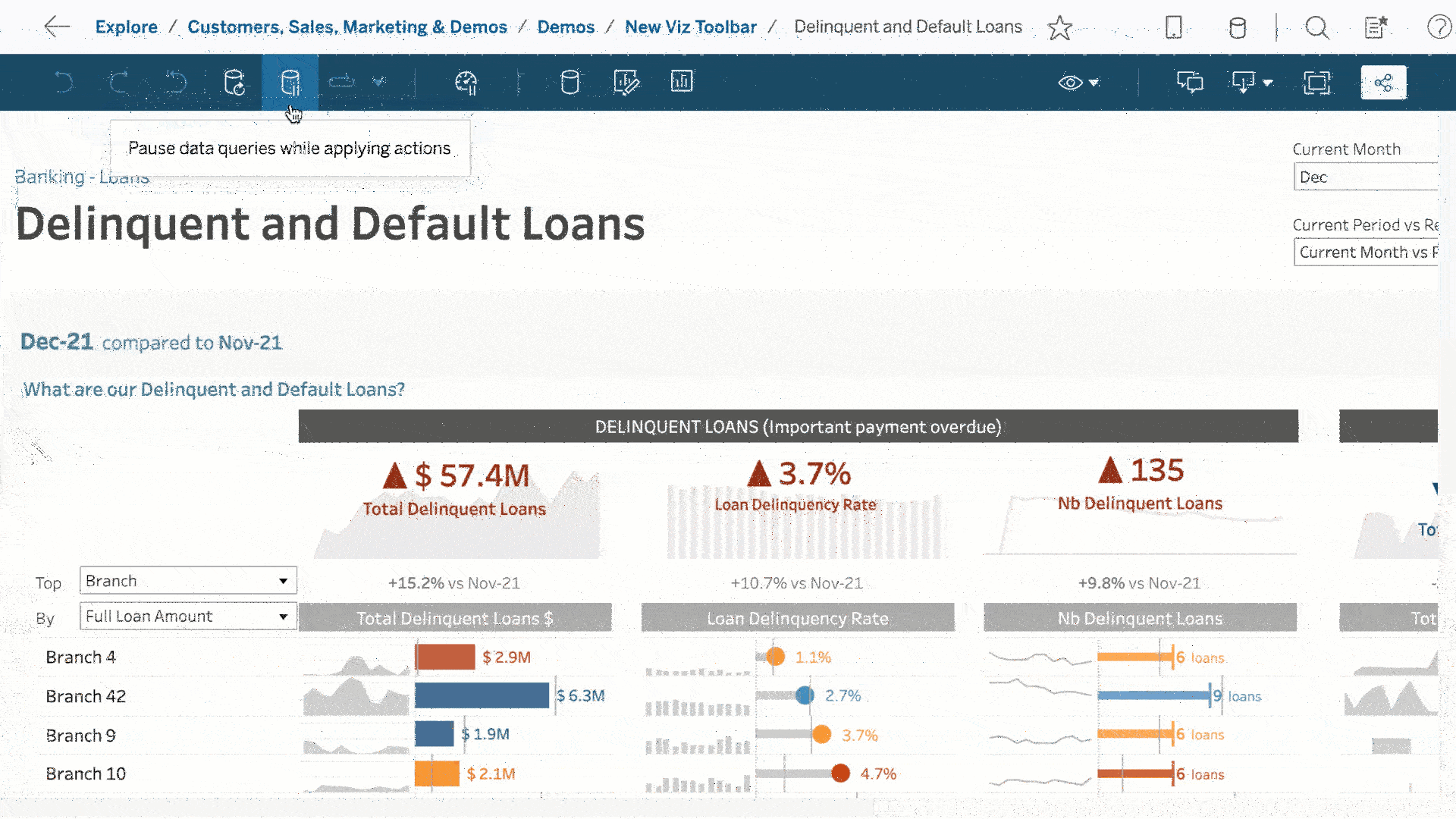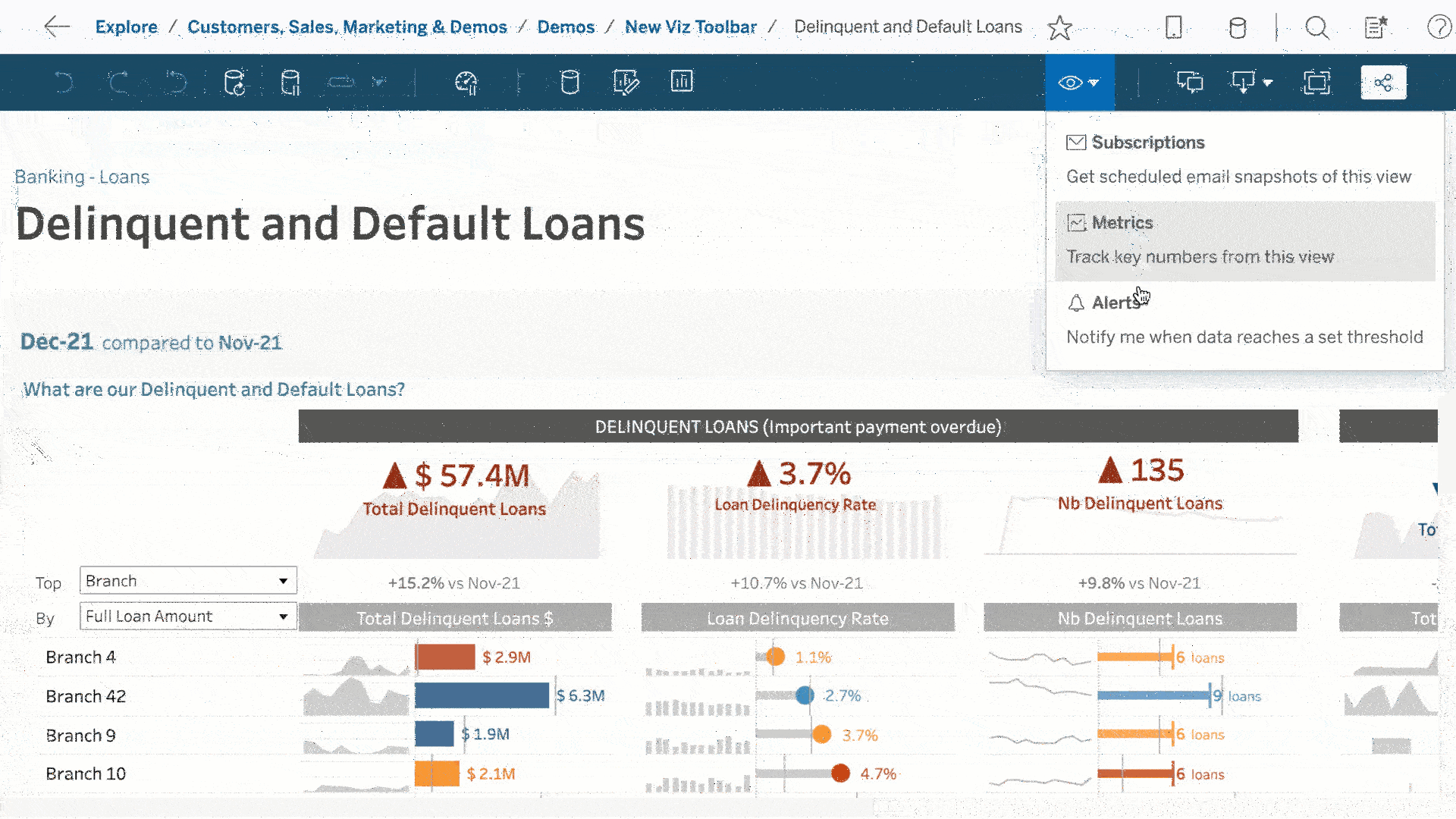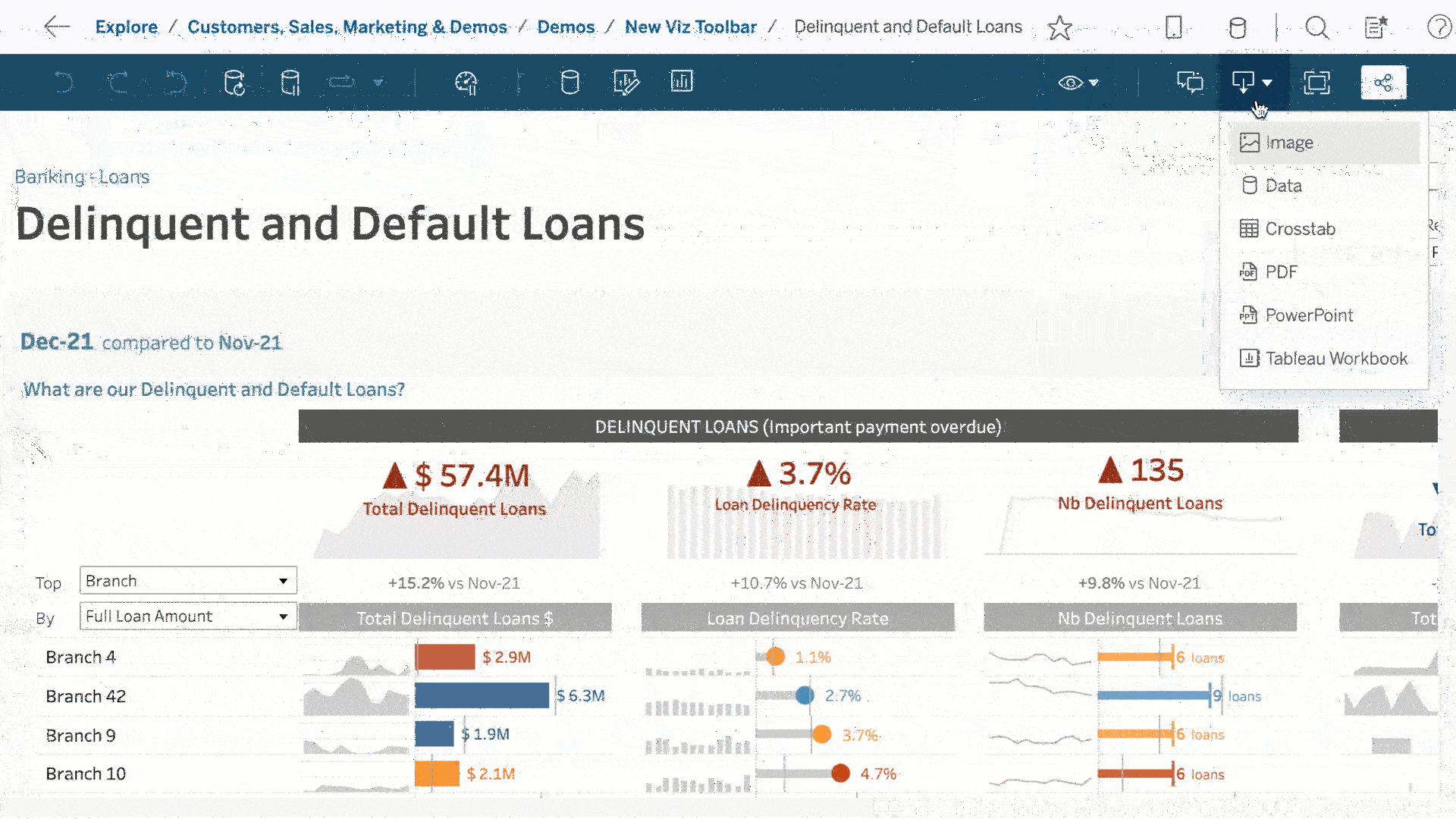
Above: A data visualization, the public-facing display of data. There are many, many data terms describing the steps between raw data and a visualization, many of which are outlined here.
Processes
If you’ve got data stored somewhere, you’ve likely got processes that move them into and between repositories. Overall, these processes are called a data pipeline, as if the data were flowing gently from place to place.
Data are conducted along the pipeline by way of data orchestration. They are loaded into the pipeline through data ingestion or data onboarding – high-volume continuous ingestion is referred to as data streaming. Within the pipeline, data are prepared through data preparation, cleaned from mistakes through data cleansing, and just generally transformed through data transformation. You can even make up sample data through data augmentation.
All of this contributes to the process of data mining, which is discovering the anomalies, patterns, and correlations within large volumes of data (you can argue that data mining is more a practice than a process, which leads to our next category.)
Practices
Some data operations are big enough to qualify as their own field of study. I categorize such large-sounding data terms as practices, and not just because we are continually practicing them to get things right. The reason why we even deal with data is to analyze and gain insights from the information we have collected – we call this data analytics. The techniques of data visualization and data storytelling are tools within data analytics, presenting the analysis in terms of pictures or narratives to aid in comprehension.
Data modeling is the practice of using data models such as those described above. The lofty-sounding but often overlooked practice of data governance is the system of defining what’s needed to manage, organize, and protect your data assets. If you ignore either of these, it will be at your own peril!
Lastly, data science is a practice which uses a number of approaches – mathematics, computer science, statistics, and machine learning among them – to extract insights and exploit the opportunities hidden in big data. Consider it kind of like data mining on steroids. The results of data science are often fed back into the data pipeline we mentioned earlier.
Things
The final category called “Things” is a catch-all grouping, convenient for when I couldn’t place the data term somewhere else. In this category, we see the data catalog and the data dictionary, which are kinds of documentation about data. They are reference works used to understand the meta-data, or descriptive information about the data. Data about data, that is.
Other “things” include data formats, which generally fall into structured data, unstructured data, and the ever-popular semi-structured data.
All of these contribute to our understanding of the massive amounts of data that companies are using today, commonly called “Big Data.” And let’s face it – “Big Data” is a Thing.
If you liked this breakdown and want to see how we can help you with your data needs, feel free to contact us here so we can reach out!