
This series takes you from zero to hero with the latest and greatest cloud data warehousing platform, Snowflake.
Data can be stored in many different formats. In the previous post in this series, we discussed semi-structured file formats, focusing on a particular approach called JSON, which is formed of arrays, objects and key value pairs. This is one of many semi-structured data formats and is supported by Snowflake, along with other formats like Avro, ORC, Parquet and XML.
Up-to-date documentation of supported semi-structured file formats can be found in Snowflake’s Introduction to Semi-Structured Data.
For the purposes of this post, we will be using the following JSON structure as our example:
[
{
"Category" : "Transport, Logistics and Vehicles",
"Regions" : [
{
"Region" : "North",
"Sub-Categories" : [
{
"Sub-Category" : "Transport",
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 1100,
"Comment" : "Above expectation | Expected 1000"
},
{
"Employee" : "Employee 2",
"Sales" : 900,
"Comment" : "Below expectation | Expected 1000"
}
]
},
{
"Sub-Category" : "Logistics",
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 5000
},
{
"Employee" : "Employee 2",
"Sales" : 6000
}
]
},
{
"Sub-Category" : "Vehicles",
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 7000
},
{
"Employee" : "Employee 2",
"Sales" : 8000
}
]
}
]
}
]
},
{
"Category" : "Hardware",
"Regions" : [
{
"Region" : "North",
"Sub-Categories" : [
{
"EmployeeSales" : [
{
"Employee" : "Employee 1",
"Sales" : 10000
},
{
"Employee" : "Employee 2",
"Sales" : 15000
}
]
}
]
},
{
"Region" : "East",
"Sub-Categories" : [
{
"EmployeeSales" : [
{
"Employee" : "Employee 3",
"Sales" : 23000
},
{
"Employee" : "Employee 4",
"Sales" : 27000
}
]
}
]
},
{
"Region" : "South",
"Sub-Categories" : [
{
"EmployeeSales" : [
{
"Employee" : "Employee 5",
"Sales" : 20000
},
{
"Employee" : "Employee 6",
"Sales" : 30000
}
]
}
]
},
{
"Region" : "West",
"Sub-Categories" : [
{
"EmployeeSales" : [
{
"Employee" : "Employee 7",
"Sales" : 50000,
"Comment" : "Won the \"Hardware Salesman of the Year\" award"
},
{
"Employee" : "Employee 8",
"Sales" : 25000
}
]
}
]
}
]
}
]
Goal in Snowflake
Our goal is to load this data into Snowflake and flatten it to achieve the following table:
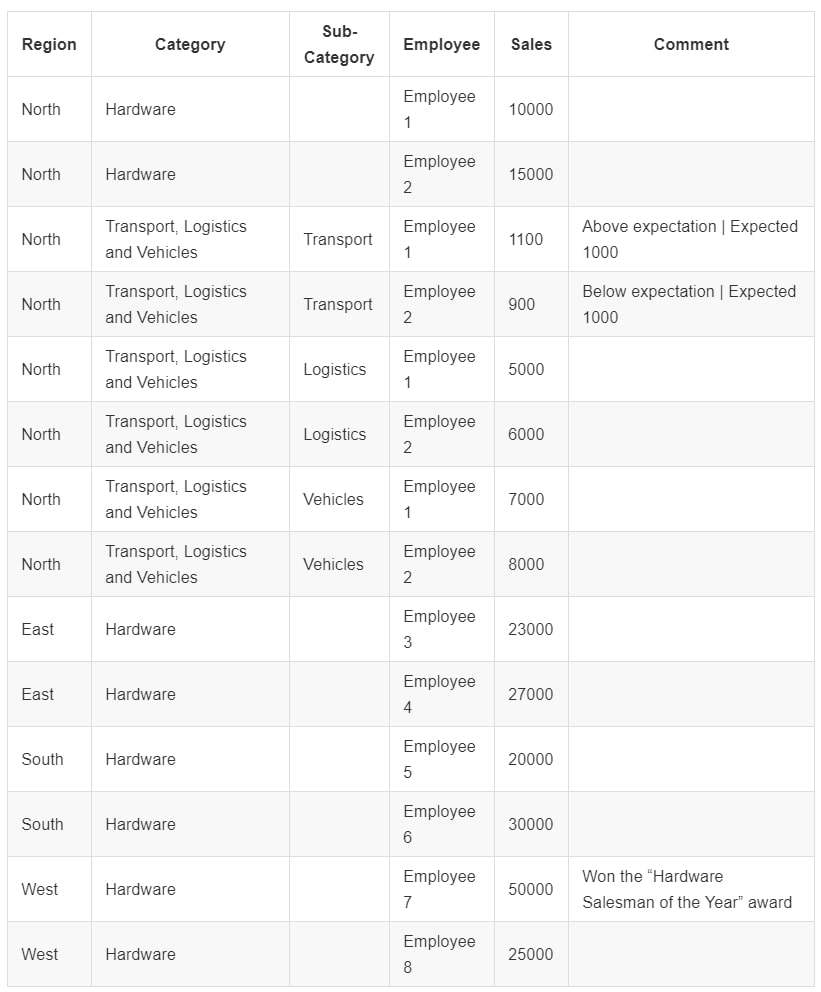
Loading the Data into a Snowflake Table
This post assumes you are comfortable with staging data in Snowflake. It is recommended to look at earlier posts in this series if you are unfamiliar with this.
Before we can load any data into Snowflake, we first must create a database and schema where we will stage the data, as well as create the table into which the data will be loaded. For this example, we will be using the DEMO_DB.DEMO_SCHEMA namespace and the stage DEMO_STAGE. As for the table itself, we will need to consider the data that we are loading. Snowflake stores semi-structured data using the VARIANT field type, so we create a table with this field type:
CREATE OR REPLACE TABLE DEMO_DB.DEMO_SCHEMA.DEMO_INPUT_TABLE (
JSON_DATA VARIANT
);
It is worth noting that Snowflake is capable of loading structured files with semi-structured fields as well. In this case, each field would have the appropriate data type, and the semi-structured field(s) would use the VARIANT data type. In this example, we only have a single set of semi-structured data—hence, a single VARIANT field.
Now that we have a destination table and the data is staged, the COPY INTO command is used to load the data. For current and complete information on the specific file format options when loading JSON data, take a look at Snowflake’s JSON File Format Documentation.
As our example dataset is relatively simple and clean, it can be loaded with the following script in Snowflake:
COPY INTO DEMO_DB.DEMO_SCHEMA.DEMO_INPUT_TABLE FROM @DEMO_DB.DEMO_SCHEMA.DEMO_STAGE FILE_FORMAT = ( TYPE = 'JSON' STRIP_OUTER_ARRAY = TRUE ) ;
We have used an option called STRIP_OUTER_ARRAY for this load. This removes the outer set of square brackets [ ] when loading the data, separating the initial array into multiple lines. If we did not strip the outer array, our entire dataset would be loaded into a single row in the destination table. With our low data volumes, this is not a problem; however, it would be an issue in larger datasets. As we have stripped the outer array, the data is loaded into two rows in Snowflake. The file format and STRIP_OUTER_ARRAY option are explained in more detail in the previous blog post.
Once loaded, we can view the data with a simple SELECT * FROM statement:

Above: Data loaded into two rows in Snowflake
Querying the Data in Snowflake
Snowflake is extremely powerful when it comes to querying semi-structured data. To begin, use standard : notation to retrieve the category for each row. We can achieve this as Category is at the highest level in our JSON object for each line:
SELECT JSON_DATA, JSON_DATA:Category FROM DEMO_INPUT_TABLE;

Above: Demonstrating category using : notation
By using :: notation, it is possible to define the end data type of the values being retrieved. Notice how in this example, the outer quotes “ are removed:
SELECT
JSON_DATA
, JSON_DATA:Category::string
FROM DEMO_INPUT_TABLE;

Above: Demonstrating conversion of category into a string
Standard : notation can fall short when tackling an array, depending on your intentions. It is possible to use : notation to target specific entries of an array; however, it is possible to target specific entries in an array using [ ] notation:
SELECT
JSON_DATA
, JSON_DATA:Category::string
, JSON_DATA:Regions[0]
, JSON_DATA:Regions[1]
, JSON_DATA:Regions[2]:Region::String
, JSON_DATA:Regions[3]:Region::String
FROM DEMO_INPUT_TABLE;

Above: Demonstrating specific array query
This approach receives each entry as its own column, which is not ideal.
Flattening Arrays
Unfortunately, it is not possible to dynamically retrieve all objects in an array with : and [ ] notation alone. This is where flattening comes in. Flattening is a term for unpackaging the semi-structured data into a columnar format by converting arrays into different rows of data. The most up-to-date information on flattening can be found in Snowflake’s Flatten Documentation.
In our case, we execute the flatten as part of our FROM clause using the function LATERAL FLATTEN. The input for the function is the array in the JSON structure that we want to flatten. It is crucial that the flatten is given an alias; in our case, the alias is Regions. There are several fields output by the LATERAL FLATTEN function; however, we are only interested in the Value for now. This contains the object within the array, and each object is provided its own row in the output view:
SELECT
JSON_DATA
, JSON_DATA:Category::string
, Regions.Value
FROM DEMO_INPUT_TABLE
, LATERAL FLATTEN (JSON_DATA:Regions) as Regions;

Above: Demonstrating regions’ value
Our specific semi-structured data in fact has three arrays: Regions, Sub-Categories and EmployeeSales. To fully convert this into a tabular format, it is first necessary to flatten each of these arrays in turn:
SELECT
JSON_DATA
, JSON_DATA:Category::string
, Regions.value:Region::string
, "Sub-Categories".value:"Sub-Category"::string
, EmployeeSales.value
FROM DEMO_INPUT_TABLE
, LATERAL FLATTEN (JSON_DATA:Regions) as Regions
, LATERAL FLATTEN (Regions.value:"Sub-Categories") as "Sub-Categories"
, LATERAL FLATTEN ("Sub-Categories".value:EmployeeSales) as EmployeeSales;
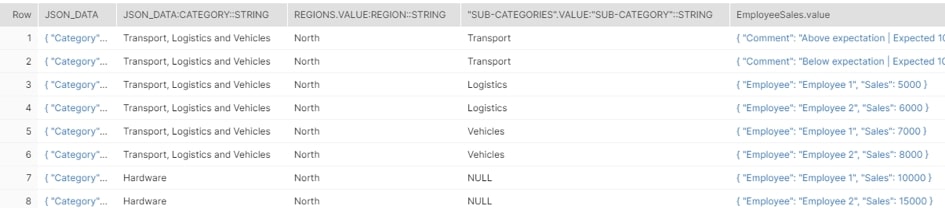
Above: Demonstrating multiple lateral flattens
Notice how “Sub-Categories”.value:”Sub-Category”::string returns NULL when the category is Hardware. This is because the “Sub-Category” key does not exist for that category.
Full Structured Query
Combining what we have learned, we can convert the entire JSON dataset into a tabular format:
SELECT
JSON_DATA:Category::string as Category
, Regions.value:Region::string as Region
, "Sub-Categories".value:"Sub-Category"::string as "Sub-Category"
, EmployeeSales.value:Employee::string as "Employee"
, EmployeeSales.value:Sales::number as "Sales"
, EmployeeSales.value:Comment::string as "Comment"
FROM DEMO_INPUT_TABLE
, LATERAL FLATTEN (JSON_DATA:Regions) as Regions
, LATERAL FLATTEN (Regions.value:"Sub-Categories") as "Sub-Categories"
, LATERAL FLATTEN ("Sub-Categories".value:EmployeeSales) as EmployeeSales;
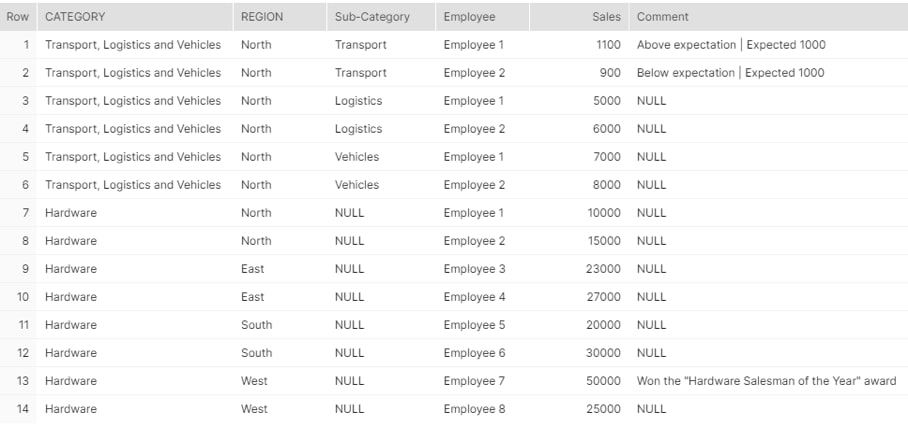
Above: Final output in Snowflake
Summary
Using the tools above, Snowflake can be leveraged to easily load and query semi-structured JSON data. If your data is in another semi-structured format such as Avro, ORC, Parquet and XML (or any other formats listed among Snowflake’s supported file formats), Snowflake can handle it in a similar fashion. This is extremely helpful when dealing with modern data sources, and I encourage you to load some JSON data into Snowflake and practice this functionality yourself.