
This series takes you from zero to hero with the latest and greatest cloud data warehousing platform, Snowflake.
File formats are database objects used by snowflake to ingest flat files. Consider file formats as your way of giving snowflake information about the file so it knows how to ingest those flat files in an optimal fashion. You specify the type of file along with a bunch of optional extra information such as (but not limited to) the compression type, field and record delimiters, whether to skip the header row or not etc. The full list of format options are in the documentation here.
Note that you can specify this information within a COPY INTO statement, however having a separate file format object keeps your code neater and gives you something you or colleagues can re-use elsewhere.
Snowflake supports the following file formats, the first is structured (already arranged in columns and rows) and the rest are semi-structured:
We have blogs on how to work with both structured and semi-structured data in Snowflake already, so follow those links to learn more.
Creating a File Format Object
File Formats can be created using SQL commands in the Snowsight interface. To get a head start on the command syntax, you could navigate to your database, list your schemas and select a schema to reveal the Create menu (see the schema page below in the new dark mode for Snowsight):
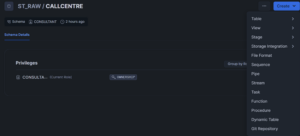
The Create menu has a File Format option which will pre-populate a window with the CREATE FILE FORMAT command:
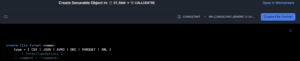
You could just as easily run this command within a worksheet and my example below shows how to create a new file format for an XML file. (We have examples of CSV file formats and JSON file formats elsewhere.)
My XML looks like this with an outer <CallCentreData> tag, then separate <Call> tags containing the information I need:
<?xml version="1.0" encoding="UTF-8"?>
<CallCenterData>
<Call>
<CallID>1</CallID>
<CustomerID>1001</CustomerID>
<AgentID>501</AgentID>
<CallDuration>180</CallDuration>
<CallResolutionStatus>Resolved</CallResolutionStatus>
</Call>
<Call>
<CallID>2</CallID>
<CustomerID>1002</CustomerID>
<AgentID>502</AgentID>
<CallDuration>240</CallDuration>
<CallResolutionStatus>Pending</CallResolutionStatus>
</Call>
I’m going to fully qualify the name of my file format by stating the database, schema and file format name. NOTE: while file formats are created within a schema, they can be used to ingest data into different databases or schemas as long as the fully qualified name is used e.g.
CREATE FILE FORMAT ST_RAW.CALLCENTRE.CALL_CENTRE_XML
TYPE = XML
COMPRESSION = NONE
--I know the file is not compressed, I could use AUTO to automatically
--detect the compression type
IGNORE_UTF8_ERRORS = FALSE
--I would like a warning if I have invalid characters
PRESERVE_SPACE = FALSE
--This will trim leading or trailing spaces
STRIP_OUTER_ELEMENT = TRUE
--I want separate rows for each <Call> tag in my data
DISABLE_SNOWFLAKE_DATA = FALSE
-- Snowflake includes additional metadata in the loading process which can
--enhance the performance of queries against the semi-structured data by
--enabling more efficient storage and retrieval. Disable this if you want
--to ensure compatibility with non-Snowflake systems
DISABLE_AUTO_CONVERT = TRUE
--I will be adding the xml to a VARIANT column so I do not want snowflake to
--detect data types and convert text to number/boolean etc
REPLACE_INVALID_CHARACTERS = FALSE
--like "ignore utf8 errors" above, I want to know about invalid characters
--on load rather than replacing them with the Unicode replacement character
SKIP_BYTE_ORDER_MARK = TRUE
--A Byte Order Mark is a character code at the beginning of a data file that
--defines the byte order and encoding form. If it exists I want to skip it
I’ve listed all the format type options in the above example (with explanations of what each option does). However, in some cases, I’m using the default option OR specifying something that would be picked up automatically. The documentation lists what the default option is in each case, and if that’s the option you want, you don’t have to explicitly type out that option.
Now I have a file format I can use it to copy data from an XML file I have stored in a stage. For XML files (as with JSON) we recommend importing the data into a VARIANT column then using a combination of PARSE_XML and LATERAL FLATTEN to transform or query the data.
Here’s the SQL code for creating the table and copying the data from my xml file into that table using my file format:
CREATE TABLE ST_RAW.CALLCENTRE.CALL_LOGS_XML (
CALL_DATA VARIANT
);
COPY INTO ST_RAW.CALLCENTRE.CALL_LOGS_XML
FROM @ST_RAW.CALLCENTRE.ST_CALLCENTRE_STAGE
FILES = ('call_centre.xml')
FILE_FORMAT = ( FORMAT_NAME = 'CALL_CENTRE_XML' );
Because of the options I chose in my file format object, I’ve been able to successfully import my .xml file into a table with a row for each call like this:
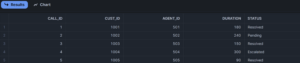
To transform that data into separate columns, I could use GET() and XMLGET() like so:
SELECT
GET(XMLGET(CALL_DATA, 'CallID'), '$')::NUMBER AS call_id,
GET(XMLGET(CALL_DATA, 'CustomerID'), '$')::NUMBER AS cust_id,
GET(XMLGET(CALL_DATA, 'AgentID'), '$')::NUMBER AS agent_id,
GET(XMLGET(CALL_DATA, 'CallDuration'), '$')::NUMBER AS duration,
GET(XMLGET(CALL_DATA, 'CallResolutionStatus'), '$')::TEXT AS status
FROM
ST_RAW.CALLCENTRE.CALL_LOGS_XML
;
How to Find Existing File Formats
Rather than creating a new file format every time you need one, you could find existing formats across the databases you have access to and see if they’re suitable using a few commands:
- SHOW FILE FORMATS;
- This will show all formats in your currently active database
- SHOW FILE FORMATS IN ACCOUNT;
- This will show all formats in your snowflake environment
- Once you’ve found a potentially suitable file format you can list out the option settings using “DESCRIBE FILE FORMAT <name of file format>;”
File Formats Within the Add Data Feature
If you simply want to add data from a single flat file to Snowflake, the add data feature is very straightforward:
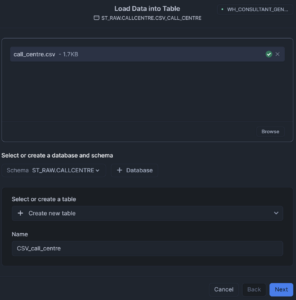
Select “Load data into a table,” browse to your file and specify the database, schema and existing table (or create a new table as I am here):
On clicking “Next,” you’re prompted to specify the File Format using drop down menus for the format type options (click “View options” to see the list):
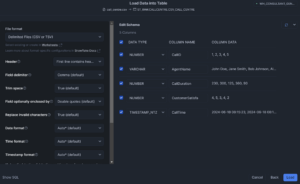
These are the same options available using the SQL command, just set up as drop down menus.
What’s helpful in this window is the “Edit Schema” section which shows how your data will be loaded according to those options. Change the settings and the column data will update.
In this case, the default settings are correct and if I change them, you’ll see Snowflake tells me I’ve got something wrong:
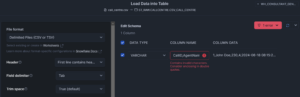
If I revert back to the defaults and click “Load,” my data is successfully loaded.
This method creates a temporary file format object for the one time ingestion. If we click the “show SQL” text, you can see it builds and references that temporary object:
CREATE TABLE "ST_RAW"."CALLCENTRE"."CSV_CALL_CENTRE"
( c1 VARCHAR , c2 VARCHAR , c3 VARCHAR , c4 VARCHAR , c5 VARCHAR );
CREATE TEMP FILE FORMAT "ST_RAW"."CALLCENTRE"."temp_file_format_2024-06-20T08:16:11.277Z"
TYPE=CSV
SKIP_HEADER=0
FIELD_DELIMITER=','
TRIM_SPACE=FALSE
FIELD_OPTIONALLY_ENCLOSED_BY=NONE
REPLACE_INVALID_CHARACTERS=TRUE
DATE_FORMAT=AUTO
TIME_FORMAT=AUTO
TIMESTAMP_FORMAT=AUTO;
COPY INTO "ST_RAW"."CALLCENTRE"."CSV_CALL_CENTRE"
FROM (SELECT $1, $2, $3, $4, $5
FROM '@"ST_RAW"."CALLCENTRE"."__snowflake_temp_import_files__"')
FILES = ('2024-06-20T08:15:58.243Z/call_centre.csv')
FILE_FORMAT = '"ST_RAW"."CALLCENTRE"."temp_file_format_2024-06-20T08:16:11.277Z"'
ON_ERROR=ABORT_STATEMENT
I hope this has been a useful introduction to File Format objects in Snowflake. Here is the link again to Snowflake’s own documentation on the subject.