
As modern applications expand in complexity, effectively managing workflows can become a significant challenge. AWS Step Functions provides a comprehensive solution for orchestrating multi-step workflows in the cloud. Whether it’s invoking Lambda functions in Task states, separating branches of execution with Parallel states or running a set of steps for each item in a dataset with Map state, AWS Step Functions provides the control structure. With its Workflow Studio and the intuitive Amazon States Language, AWS Step Functions brings simplicity to complexity.
Here are a few examples of ways you can leverage AWS Step Functions:
- Orchestrate and monitor complex business processes which require coordination of multiple services (Lambda, ECS, S3, etc.), allowing for the passing of variables between these services.
- Execute long-running tasks that may exceed the execution time limit of a single Lambda Function. The workflow can be split into smaller, manageable steps that each complete within the time limit.
- Handle execution errors and retry failed tasks. If a task within AWS Step Functions fails, it can be configured to retry the task a certain number of times before moving to the next step. This makes your workflow more resilient and reduces the likelihood of a complete failure.
- Retrieve a list of values from an API, then employ a Map state to iterate through this list, prompting an additional API call for each item.
Depending on the requirements, you can select Standard or Express Workflows. Standard Workflows are perfect for long-running (up to one year), while Express Workflows are suited for high-volume, event-processing workloads, such as IoT data ingestion, streaming data processing and dealing with a significantly larger number of APIs. This is exactly what we are going to do today using PokiAPI v2.
If you have ever played Pokémon games or watched the legendary moment when Ash met Pikachu, you might also dream of catching a variety of these charming creatures. Pokémon can be captured using devices known as Pokéballs, and their skills can be developed and enhanced through combat with other Pokémon. But today, we are going to catch them using AWS Step Functions so they can live in Snowflake where they can help develop visualizations.
The Setup
To collect Pokémon data, PokiAPI v2 is used, which is designed in alignment with RESTful principles. This API is accessible over HTTPS and returns data in JSON format. When calling the Pokémon endpoint you get only the name and the URL (including the Pokémon ID) of all Pokémon. To get more detailed information about a specific Pokémon, you need the Pokémon ID as a resource identifier in the request.
This means you will need three functions:
- First, you will require a function to extract the Pokémon IDs.
- Following this, another function will be needed to store the data in an S3 bucket.
- Finally, you’ll need a function that copies this data into a Snowflake table to complete the process.
In our example, we are using AWS Lambda Functions. Prior to utilizing these functions, they must be properly configured. This might involve extending the timeout duration (up to 15 minutes), increasing the memory allocation (up to 512 MB) and adding necessary layers for the usage of specific Python libraries (s3fs, pandas and snowflake.connector). For a detailed, step-by-step guide to adding these layers, please refer to this blog post.
1. Get Pokémon IDs
This function fetches all Pokémon URLs from the Pokémon endpoint then extracts and returns the Pokémon IDs as a JSON in a list, which will be required by the second function. It uses exponential backoff to handle rate limits or the temporary unavailability of the API. The Python code for this Lambda Function is shown below:
import pandas as pd
import requests
import time
def lambda_handler(event, context):
url = f"https://pokeapi.co/api/v2/pokemon?limit=1281"
# Make sure the response is equal 200
while True:
response = requests.get(url)
if response.status_code == 200:
pokemon_id_df = pd.DataFrame(response.json()["results"])[["url"]] # Extract thr URLs
pokemon_id_df["url"] = pokemon_id_df["url"].str.split("/").str[-2] # Extract the Pokemon ID
pokemon_id_df.rename(columns={"url": "pokemon_id"}, inplace=True) # Rename the URL column
list_of_dicts = pokemon_id_df.to_dict("records") # Transfer to a Dictionary
break
time.sleep(0.5) # Wait for some time before retrying
return list_of_dicts
2. Store Pokémon into S3
This function retrieves specific Pokémon data based on the Pokémon ID and stores it in an S3 bucket. The Pokémon ID is passed through the event caused by the call of the ufnction. Like the previous function, it uses exponential backoff to handle rate limits or temporary unavailability of the API. This function needs the right permissions to write into an S3 Bucket. For detailed configuration, you can refer to this blog post.
The following is the Python code for this Lambda Function. Remember to replace <your-s3-bucket> with the name of your S3 Bucket.
import requests
import s3fs
import time
fs = s3fs.S3FileSystem()
def lambda_handler(event, context):
pokemon_id = list(event.values())[0] # Extract the Pokemon ID from the event
url = f"https://pokeapi.co/api/v2/pokemon/{pokemon_id}" # Create the URL
# Store the Pokemon data as a json file into S3
while True: # Make sure the response is equal 200
response = requests.get(url)
if response.status_code == 200:
with fs.open(f's3://<your-s3-bucket>/pokemon/{pokemon_id}.json', 'w') as file:
file.write(response.text)
break
time.sleep(0.5) # wait for some time before retrying
return 0 # Return nothing
3. Copy Pokémon into Snowflake
This function loads the Pokémon data from S3 into a Snowflake table after it is created and purges the data from S3. This function uses an external stage (POKEMON_STAGE) to retrieve data from the S3 Bucket. For detailed configuration, you can refer to this blog post.
It is important to note that, when you have a lot of data, going with a small Snowflake warehouse might lead to executing times longer than 15 minutes, which is the maximum timeout of the Lambda Function.
Please note that we do not recommend storing your credentials directly in the code in a real-world scenario and suggest leveraging environment variables and/or key vaults. For more information, please check this blog post.
Below, you’ll find the Python code associated with this Lambda Function:
import snowflake.connector
import time
import json
# Connect to Snowflake
conn = snowflake.connector.connect(
user = "XXXX",
password = "XXXX",
account = "XXXX",
database = "XXXX",
schema = "XXXX",
warehouse = "XXXX"
)
cur = conn.cursor()
def lambda_handler(event, context):
cur.execute("CREATE OR REPLACE TABLE POKEMON(RAW_POKEMON VARIANT)") # Create a RAW table
sql_query = """
COPY INTO POKEMON
FROM @POKEMON_STAGE
FILE_FORMAT = ( TYPE = 'JSON' )
PURGE = TRUE;
"""
cur.execute(sql_query) # Copy into Snowflake
return 0 # Return nothing
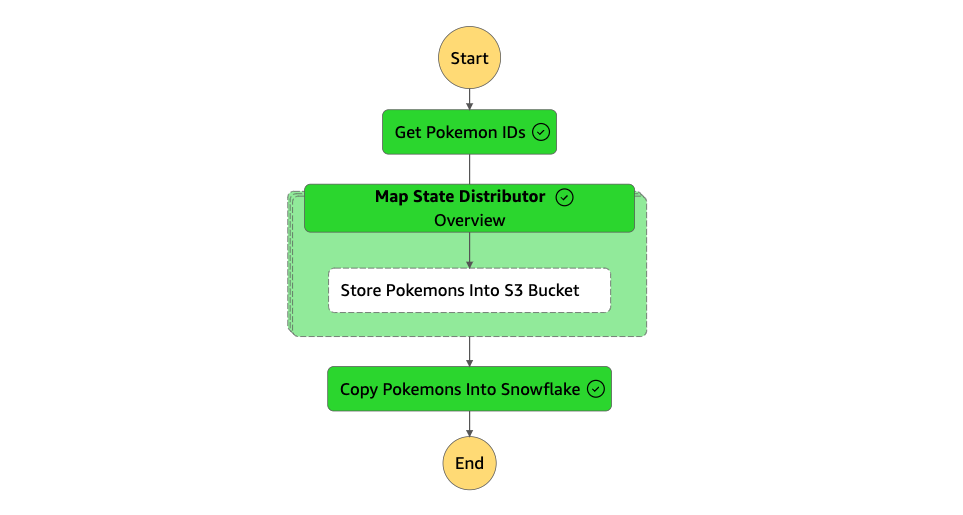
4. Orchestrate with AWS Step Functions
While it’s possible to orchestrate functions locally, there are two key challenges to consider. First, your API calls will be processed sequentially, which may not be ideal for efficiency. Second, if you’re dealing with a significantly larger number of API calls than in our example, it can become difficult to track your workflow locally with one execution. This is where AWS Step Functions come into play. Plus, with AWS Step Functions, you can easily establish a schedule using AWS EventBridge and configure notifications to receive emails or Slack messages about the workflow through AWS Simple Notification Service.
Our Step Function needs an IAM role with two policies: AWSLambdaRole and AWSStepFunctionsFullAccess to orchestrate one Map and three Task states:
- Initially, it executes a Task with the first Lambda Function to retrieve Pokémon IDs.
- Following that, it deploys a Map state in a distributed mode to execute a task with the second Lambda Function. This creates a hierarchical structure with one state machine nested within another, in which each iteration of the Map state acts as a separate workflow execution, enabling high concurrency and a limitless transition rate. Each of these independent workflow executions preserves its unique execution history, separate from the parent workflow’s history. Notably, this framework is adept at processing inputs also from large-scale Amazon S3 data resources.
- Finally, it performs a task through the third Lambda Function to copy the JSON files into Snowflake.
See the definition of the Step Function in Amazon States Language below. Remember to replace the ARN of your Lambda Functions and the name of your S3 Bucket.
{
"StartAt": "Get Pokemon Urls",
"States": {
"Get Pokemon Urls": {
"Type": "Task",
"Resource": "ARN of Get Pokémon IDs Lambda Function",
"Next": "MapStateDistributor"
},
"MapStateDistributor": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "Store Pokemon Into S3 Bucket",
"States": {
"Store Pokemon Into S3 Bucket": {
"Type": "Task",
"Resource": "Your S3 Bucket",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "ARN of Store Pokémon Into S3 Lambda Function"
},
"End": true
}
}
},
"Next": "Copy Pokemon Into Snowflake"
},
"Copy Pokemon Into Snowflake": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "ARN of Copy Pokémon Into Snowflake Lambda Function"
},
"End": true
}
}
}
The next image shows a successful run of the Step Function:
Bonus
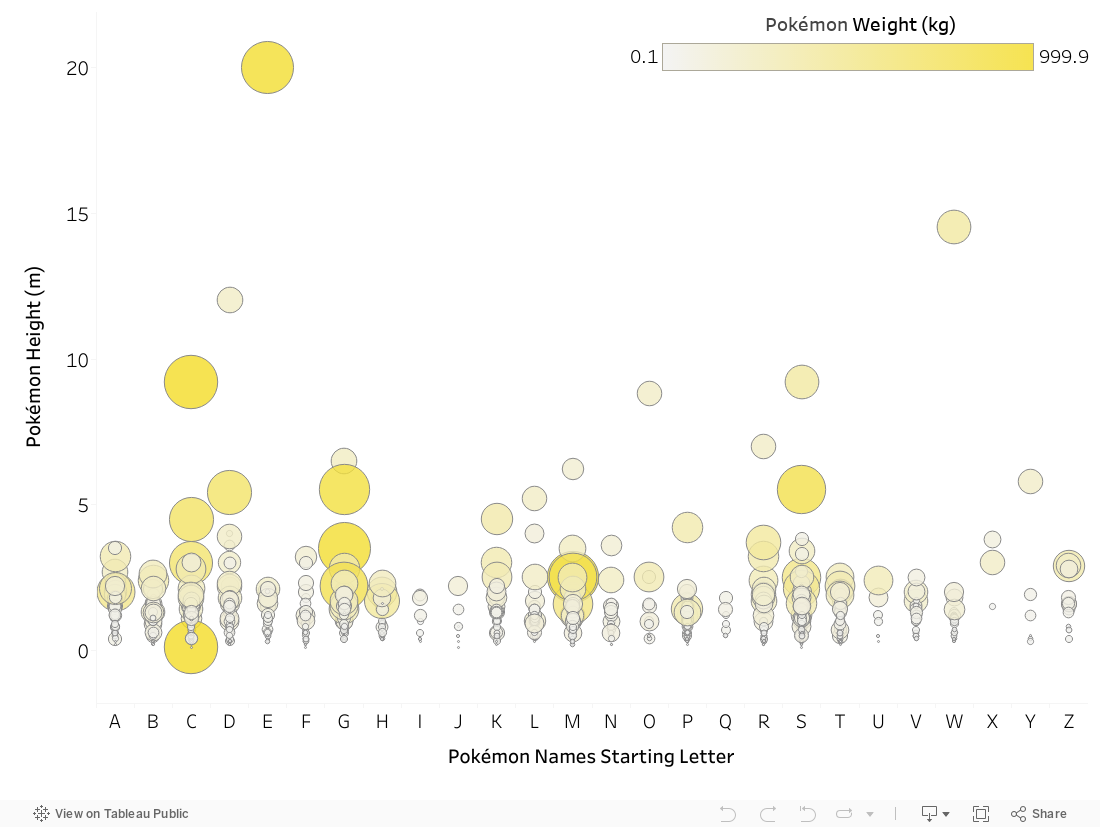
Once the Step Function has been executed successfully, you can begin wrangling the JSON data in Snowflake to generate visualizations. Here is an example of a Tableau dashboard that displays the height and weight of each Pokémon. Can you identify the tallest Pokémon? Hover over the highest bubble to discover the answer.
Wrap Up
Step Functions provide a robust solution for handling complex workflows. Using PokiAPI v2 as an example, we’ve shown how numerous RESTful API calls can represent such a complex workflow containing multiple Lambda Functions, which then can be easily managed using a Step Function.
Do you have any other data to catch? Reach out and let’s catch it together.