
Today, global business operations represent the norm, rather than the exception, intensifying the volumes of data collected. Not only does this increased bandwidth of data come with a rise in the amount of sensitive data collected, but regulatory considerations begin to not-so subtly creep into the conversation. As such, organizations are first and foremost tasked with protecting that information and adhering to various data privacy compliance regulations such as GDPR, CCPA, HIPAA and more before leveraging this data in downstream services.
Complexities arise when organizations consider the nature of their international data (i.e., is it generated as part of operations occurring in that country or is it merely sales/marketing data that is coming from that country?). For example, GDPR’s “extraterritorial” condition stipulates that when goods or services are sold to customers that would be considered as natural persons in the UK, the companies collecting their personal details – either through sales or marketing initiatives – are subject to GDPR regulations irrespective of where your business is located (i.e., even if there is no UK presence).
Therefore, in order to maintain analytical utility, data pipelines must be established on the grounds of privacy-first architecture. Fortunately, leading cloud data platforms such as Snowflake and Databricks have the mechanisms in place that make this possible. That, coupled with our data masking expertise here at InterWorks, puts customers in a position to confidently view their downstream data. After all, the primary currency for data intensive organizations is the trust that data is stored and processed appropriately, and concealed where necessary. In this blog, we will discuss data masking strategies at the data engineering and data warehouse level, particularly how we carry out these strategies within Snowflake.
Data Masking Terminology
Before diving in, it is important to ensure that we’re all aligned on the specific terminology:
- Anonymization: This refers to the process of permanently and irreversibly altering data to eliminate the subject from being identified. This provides a high degree of privacy protection but lower analytical utility for granular insights. The question must be asked whether data of this nature (i.e., SSNs) is even needed for downstream applications.
- Psuedonymization: This refers to the act of replacing identifiable indicators with artificial identifiers (i.e., pseudonyms). With the right rights and access, this process is reversible, to be traced back.
- Tokenization: This is a specific form of pseudonymization where a sensitive data element is replaced by a non-sensitive equivalent, called a token, that holds no extrinsic value. “Token vaults” store the relationship between the original data and the token.
- Hashing: The process of mathematically transforming data into a fixed-length string of characters (a hash). This represents a one-way function where even a tiny change in the input results in a different hash value.
Data Masking Implemented at Scale
Our tag-based solutions are architected to support enterprise-scale data protection requirements, including cross-account data sharing scenarios where sensitive data must be appropriately masked while maintaining analytical utility.
To seamlessly ensure scalability across enterprise data estates, we recommend moving toward tag-based masking as a primary governance framework. This becomes useful as new data comes in, and you’re tasked with ensuring that you can: a) identify the sensitive data (i.e., PII data columns) and b) apply the above strategies to this data.
Tag-based masking functions as a policy-driven orchestration layer, where sensitive data is identified as it enters the ecosystem and assigned a classification tag. Then, rather than manually applying the transformations to individual tables, a single masking policy is tied to the tag itself, automatically triggering technical data masking strategies where ever that tag appears. This approach significantly reduces administrative overhead and ensures that protection remains consistent and dynamic, even as new data sources are ingested into the architecture.
Note: Snowflake employs native classification capabilities to automatically detect and categorize sensitive data within an ecosystem. All columns that are identified as containing sensitive data are assigned two categories: semantic and privacy categories. The semantic category identifies the type of personal attribute and the privacy category identifies the degree of sensitivity whereby Snowflake assigns data into one of three native categories (identifiers, quasi-identifiers or sensitive information). To classify data attributes that falls outside the native options, custom categories can be employed to cater for organization-specific sensitive data.
To secure this data at scale, Snowflake utilizes tag-based masking policies. Instead of manually applying security to individual columns or rows of data as it is entered, global masking policies associated with specific classification tags can be defined upfront. This ensures that as new sensitive data is ingested and tagged, the appropriate privacy controls are automatically applied, bridging the gap between data discovery and consistent, automated governance. You can read more on how Snowflake classifies and handles sensitive data here.
To achieve the dual-pronged objective of maintaining analytical utility and implementing privacy-first architecture, one approach that InterWorks has previously followed is creating dedicated databases for centralized pseudonymization administration. Within these databases, the appropriate roles for controlled access to masking functions was then established. How this is implemented is largely customer-dependent, with a few combinations available for consideration when ingesting both sensitive and international data.
Single Snowflake Account x Single Region
Here, all privacy-sensitive ingestion and analytics run inside one Snowflake account but are cleanly separated into specialized databases. Source data (including full PII data) is landed as an exact copy in a restricted raw database, such as DATA_LAKE_PII, that only a tightly controlled set of roles can see.
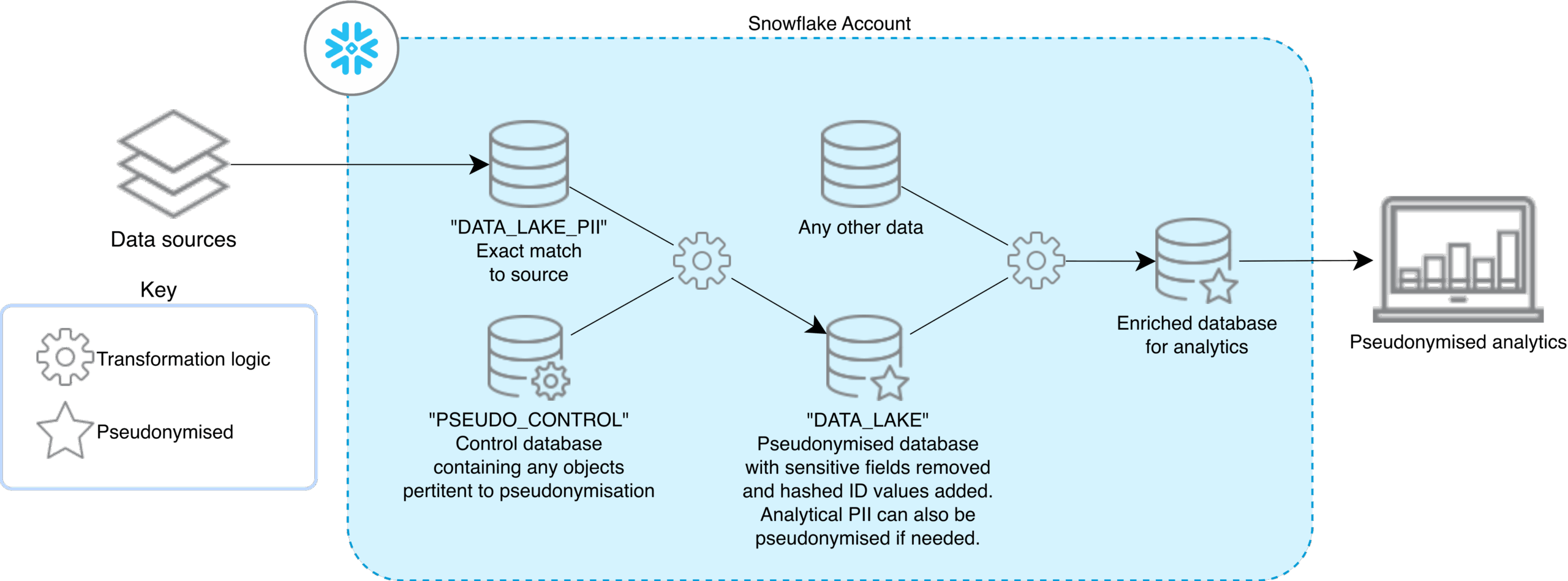
A dedicated control database (e.g., PSEUDO_CONTROL) holds the pseudonymization transformation logic, mapping objects and any supporting reference data or governance rules. Using that logic, sensitive fields and identifiers are transformed out into a pseudonymized analytics database (DATA_LAKE), where schemas expose only privacy-safe attributes and hashed or tokenized keys. This DATA_LAKE layer is the first environment visible to non-privileged engineers and can be complemented with data quality checks and cataloguing options to make data discoverable and trustworthy.
Finally, a primed database that is enriched for analytical reporting and modeling is set up downstream, feeding directly into the BI suite. The result is a single-account design that keeps sensitive data strongly isolated while still delivering rich, pseudonymized analytics within one regional Snowflake footprint.
Multiple Snowflake Accounts x Single Region
In this scenario, privacy-sensitive processing is split across two tightly coupled accounts: a PII account and a pseudonymized account, connected via Snowflake’s secure data sharing. In the PII account, raw source data lands in a DATA_LAKE database that is an exact match to upstream systems, with full PIIs present but access restricted to a small set of privileged roles.
Optionally, a DATA_LAKE_CLEAN layer can be employed, which applies light preparation such as deduplication and type casting still within the PII boundary. From there, transformation logic produces a DATA_LAKE_HASHED database where sensitive fields are removed and identifiers are hashed (with the hashed layer then being exposed to the second Snowflake account, the pseudonymized account).
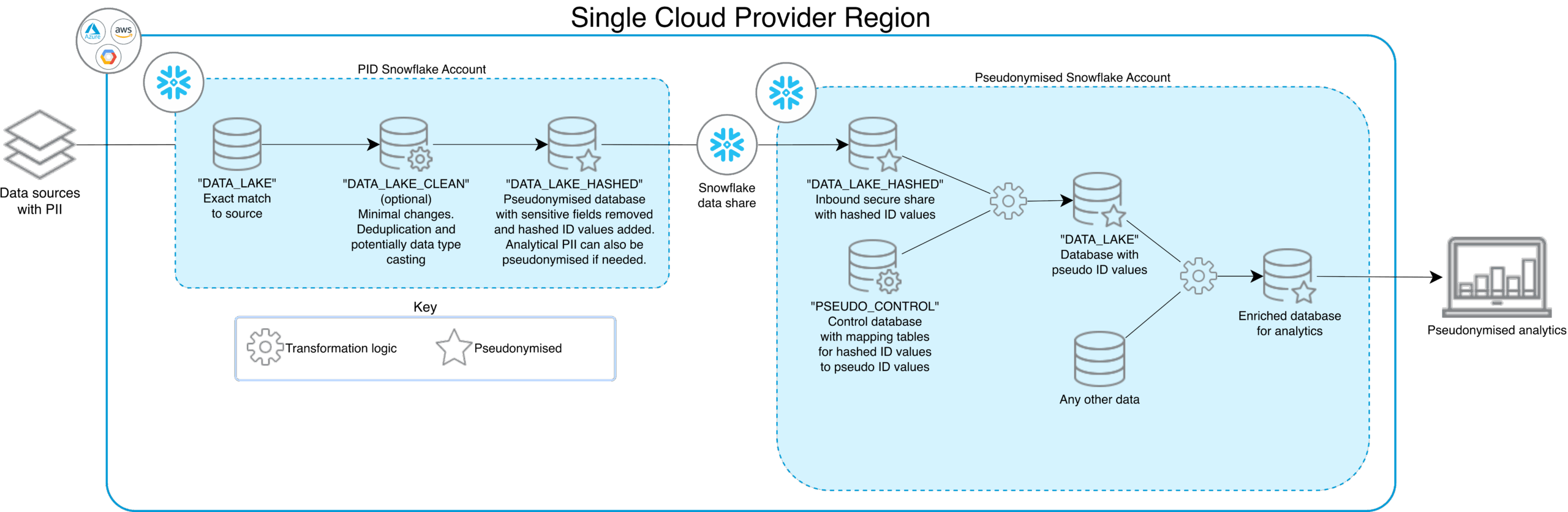
In the pseudonymized account, that share feeds into DATA_LAKE_HASHED and onward into a DATA_LAKE database that becomes the main analytics store: Schemas are composed of shared tables and any other non‑PII sources, and they represent the first environment visible to regular engineers.
A dedicated PSEUDO_CONTROL database in the pseudonymized account holds mapping tables and controls the relationship between hashed IDs and pseudo IDs, keeping re‑identification capabilities isolated from day‑to‑day analytics (similar to our first approach within the same account). This design raises the security bar by placing raw PIIs in their own account while still keeping everything within a single cloud region and preserving rich analytical utility over pseudonymized data.
Multiple Snowflake Accounts x Multiple Region
In this instance, the privacy‑first pattern extends across geographies by combining account‑level separation of PII with Snowflake’s cross‑region data replication capabilities. Instead of zero‑copy cloning within a single region, you replicate one or more primary databases (and their shares) from a source PII or pseudonymized account into secondary accounts in other regions. You then expose those replicated objects to local consumers in downstream analytics applications.
This is evidenced in our diagram where Region A hosts the sensitive information in a raw data format (DATA_LAKE_PII) and a pseudonymized format (DATA_LAKE). The pseudonymized database is then replicated into the Snowflake account in Region B, where the eventual analytics will be consumed.
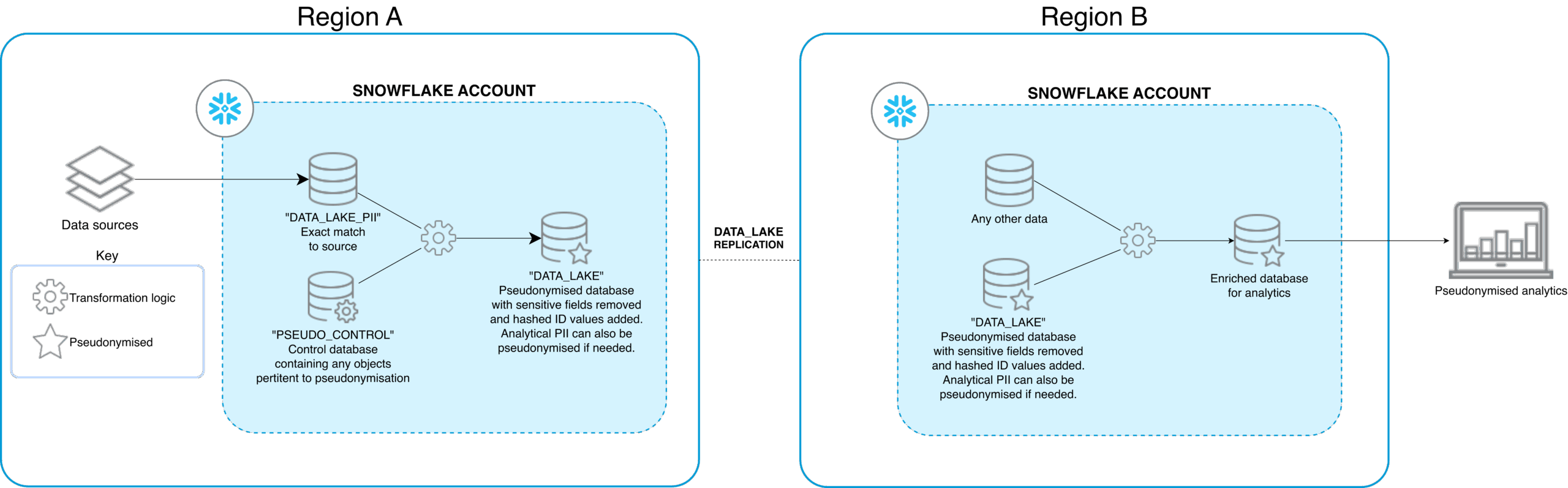
This replication is done at the database or replication‑group level, which means you physically store the data twice and pay for both the storage footprint and the compute required to refresh the replicas, in contrast to same‑region direct shares where storage is not duplicated. From a privacy and regulatory standpoint, this design lets you keep raw PII constrained to specific regional accounts while still pushing pseudonymized or minimized datasets closer to downstream teams and workloads, as long as you validate that cross‑border transfers are allowed for the data in scope.
This architecture is essential for organizations that need to maintain a strict data security posture whilst still requiring a centralized analytics repository. The underlying message of this written piece rings true here as these privacy-preserving designs act as strategic enablers that allow teams to achieve analytical utility with pseudonymized data. The result is a pattern that preserves the logical split between PII and analytics but adds an explicit trade‑off between regional proximity and the extra cost and governance considerations introduced by replication.
InterWorks Is Your Data Governance and Privacy Partner
As data privacy regulations continue to tighten and organizations expand their global footprint, the capability to preserve analytical utility while enforcing rigorous data protection holds heavier weight. Whether your architecture calls for a single-account setup with cleanly separated databases, a multi-account design leveraging Snowflake’s secure data sharing or a fully distributed multi-region topology with cross-border replication, it is important for data architecture designs to consider data privacy upfront.
At InterWorks, we’ve helped organizations across industries design and implement these exact patterns, from tag-based masking frameworks and pseudonymization control databases to enterprise-scale governance models that keep sensitive data isolated without sacrificing analytics. If you’re navigating the complexities of PII protection across Snowflake accounts or regions and want to ensure your data platform is both compliant and capable, we’d love to help. Reach out to our team to get started.
