
This series takes you from zero to hero with the latest and greatest cloud data warehousing platform, Snowflake.
Data can be stored in many different formats. Before we can import any data into Snowflake, it must first be stored in a supported format that Snowflake can interpret. At time of writing, the full list of supported is contained in the table below:
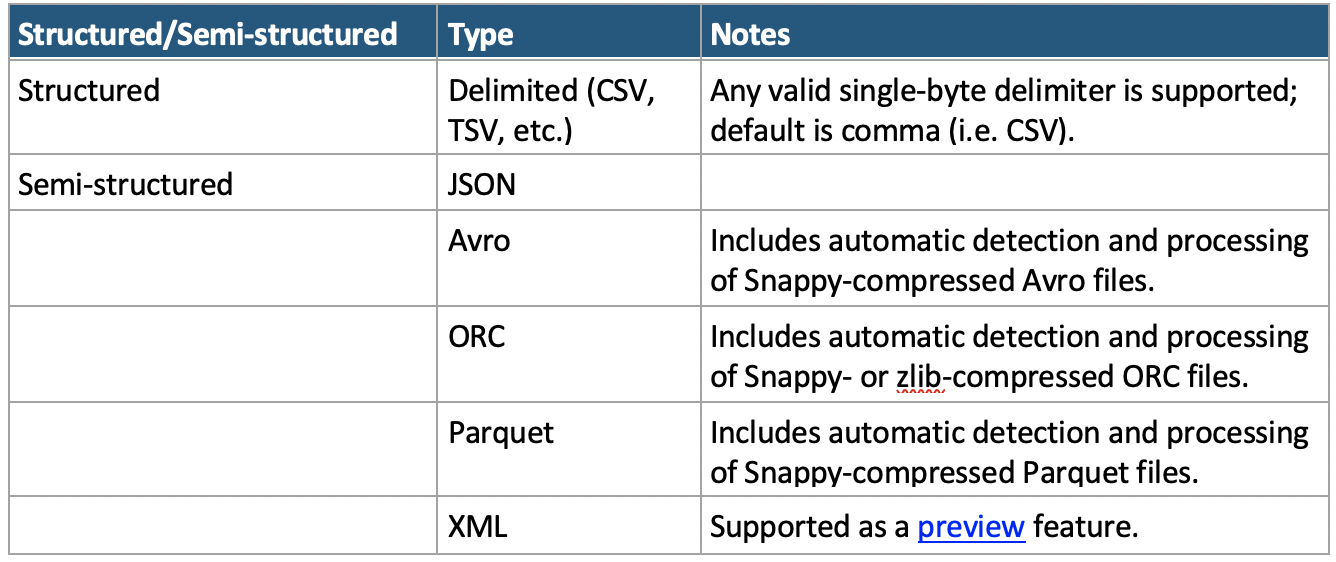
*Note: The XML preview feature link can be accessed here
An up-to-date list of supported file formats can be found in Snowflake’s documentation.
Knowing the file format is a critical requirement for Snowflake to understand how to read data that is being ingested. If the format that Snowflake is expecting does not match the format of the file, this could result in anything from a minor error in the data to a total failure to load.
A Brief Introduction to Structured Textual Data Formats
One of the most commonly used data formats is a structured approach where chosen characters are used to separate a text file into columns and rows. Files in this format are often referred to as CSV files.
Depending on the file, this can either mean Comma Separated Values (where a comma , is used to separate the columns of data) or Character Separated Values (where a different character is used to separate the columns of data).
Where Are CSV Files Often Used?
CSV files are a standard output for data analysis, processing or construction tools. Among many others, the following softwares and services all ingest and output CSV data natively:
- Data warehousing tools, such as:
- Snowjesflake
- Microsoft SQL Server
- PostgreSQL server
- Spreadsheet applications, such as:
- Microsoft Excel
- OpenOffice Calc
- Google Sheets
- Data transformation tools, such as:
- Matillion
- Alteryx
- SQL Server Integration Services
- Data visualisation tools, such as:
- Tableau
- Power BI
- Looker
- Languages, such as:
- Python
- JavaScript
- R
Comma Separated Values Files
Consider the following table of data:
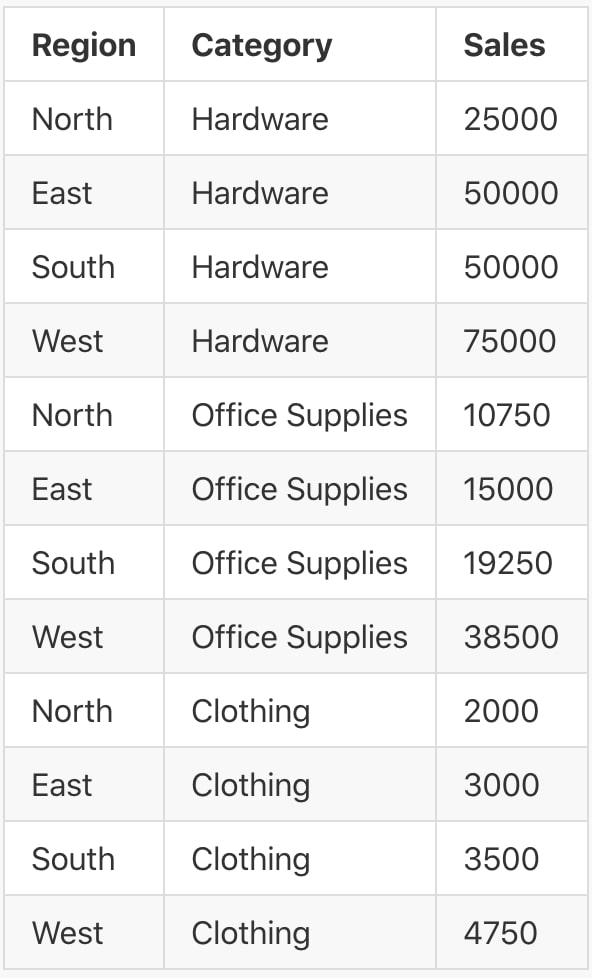
This can be stored in a Comma Separated Values structure as follows:
Region,Category,Sales North,Hardware,25000 East,Hardware,50000 South,Hardware,50000 West,Hardware,75000 North,Office Supplies,10750 East,Office Supplies,15000 South,Office Supplies,19250 West,Office Supplies,38500 North,Clothing,2000 East,Clothing,3000 South,Clothing,3500 West,Clothing,4750
We can see here that each column is separated by a comma, and each row is determined by starting a new line. This is a simple yet effective way to store data; however, there can be issues. Suppose our dataset contained another category called Transport, Logistics and Vehicles, as in the table below:
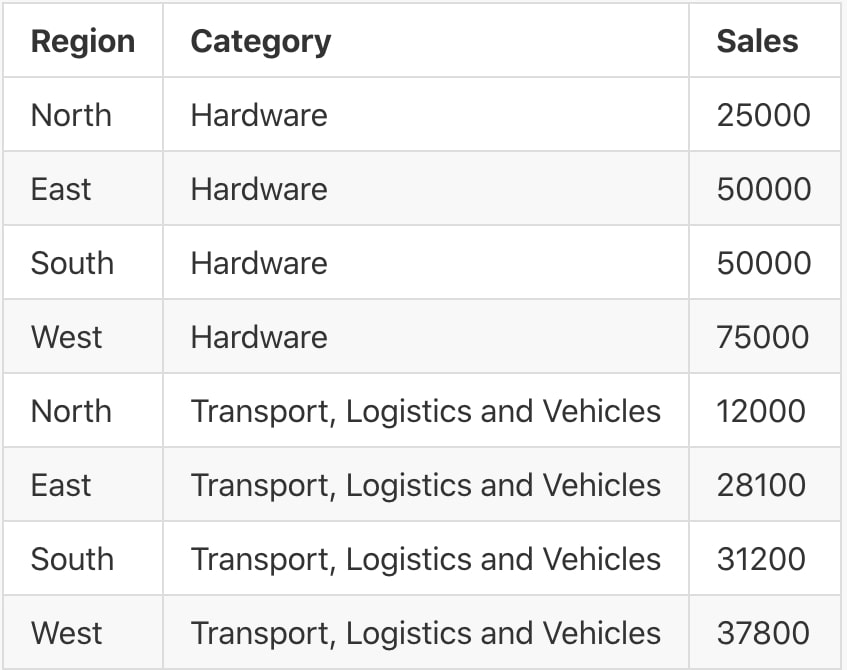
If this table were stored using the same structure as before, it would appear as follows:
Region,Category,Sales North,Hardware,25000 East,Hardware,50000 South,Hardware,50000 West,Hardware,75000 North,Transport, Logistics and Vehicles,12000 East,Transport, Logistics and Vehicles,28100 South,Transport, Logistics and Vehicles,31200 West,Transport, Logistics and Vehicles,37800
This creates an issue, as the comma inside the category name Transport, Logistics and Vehicles would instead indicate a new column. If this file were to be interpreted by a data reader, it would create the following table:
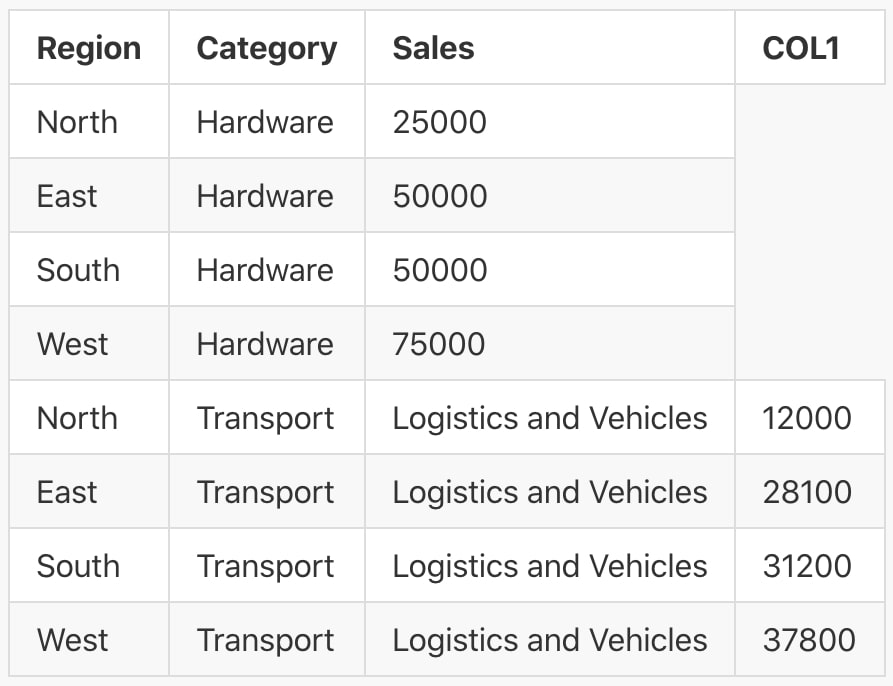
This is clearly an issue and needs to be corrected. Here are two popular approaches to address this issue:
- Use a less common character as the separator itself. The file then becomes a Character Separated Values file.
- Use another character to determine where each column begins and ends, instructing the data reader to ignore separators inside. This is referred to as a text qualifier.
Character Separated Values Files
As the comma character is regularly used in many datasets, it is prudent to consider using other characters as the field delimiter (aka column separator) instead. Popular choices for a field delimiter include pipe | , caret ^ , tilde ~ and sometimes tab. Sometimes these may have their own recognised file extension, i.e. a Tab Separated Values file.
We can modify our example to use one of these characters as the delimiter instead:
Region|Category|Sales North|Hardware|25000 East|Hardware|50000 South|Hardware|50000 West|Hardware|75000 North|Transport, Logistics and Vehicles|12000 East|Transport, Logistics and Vehicles|28100 South|Transport, Logistics and Vehicles|31200 West|Transport, Logistics and Vehicles|37800
This solves the issue in this case; however, it is still possible that a dataset may include our chosen character. Depending on the data, it may be possible to confidently claim that the field delimiter will not be in the data, in which case no further action is needed. However, if this cannot be guaranteed then text qualifiers are still advised.
Using Text Qualifiers
Text qualifiers are a convenient way to indicate when a column of data starts and ends. For our example data, one option is to wrap each field in a set of quotation marks ” “ . It is now clear when reading the file that the category Transport, Logistics and Vehicles is a single entry, and the comma is treated as part of the data instead of as a separator:
"Region","Category","Sales" "North","Hardware","25000" "East","Hardware","50000" "South","Hardware","50000" "West","Hardware","75000" "North","Transport, Logistics and Vehicles","12000" "East","Transport, Logistics and Vehicles","28100" "South","Transport, Logistics and Vehicles","31200" "West","Transport, Logistics and Vehicles","37800"
Whilst this resolves this specific error, it does not solve the general issue as it exposes a similar flaw. Consider the following table where we have included a comments field in the data:
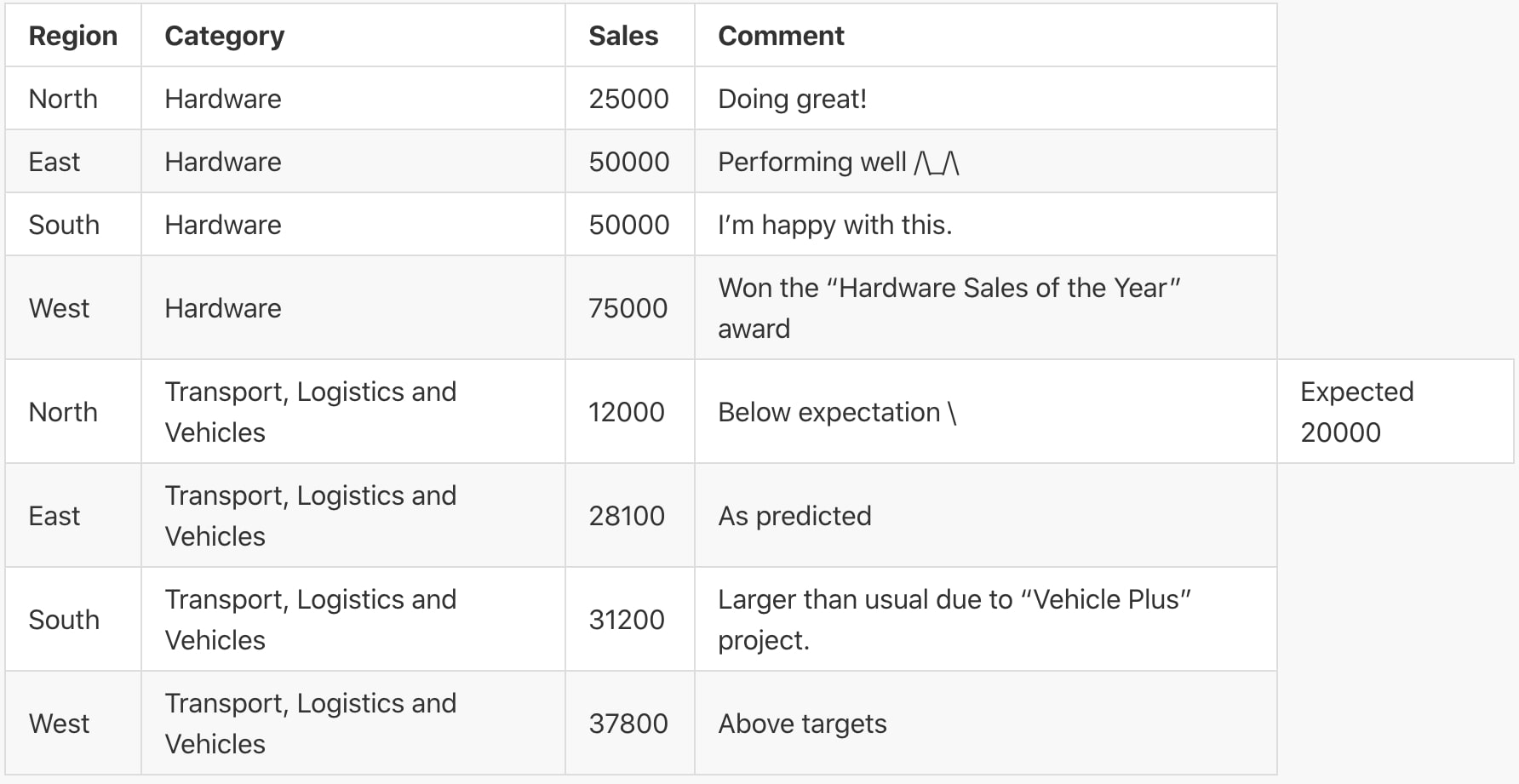
As the comments sometimes include quotes, the same character would not be reliable to indicate the start and end of each piece of data. Here are two popular approaches to address this issue:
- Modify the data to include an escape character before any occurrences of the text qualifier character in the data
- Modify the data to repeat entries of the text qualifier character and instruct the data reader to treat double entries as data
Escape Characters
Data can be modified to use escape characters. When an escape character is interpreted by a data reader, the next character is treated as another entry in the data instead of a special character. In our example, we can use a backslash \ to identify valid occurrences of the quote mark in our two comments. Since backslash is our escape character, we can use it to escape itself and thus enter a valid backslash in the comment Performing well /\_/\ :
"Region"|"Category"|"Sales"|"Comment" "North"|"Hardware"|"25000"|"Doing great!" "East"|"Hardware"|"50000"|"Performing well /\\_/\\" "South"|"Hardware"|"50000"|"I'm happy with this." "West"|"Hardware"|"75000"|"Won the \"Hardware Sales of the Year\" award" "North"|"Transport, Logistics and Vehicles"|"12000"|"Below expectation | Expected 20000" "East"|"Transport, Logistics and Vehicles"|"28100"|"As predicted" "South"|"Transport, Logistics and Vehicles"|"31200"|"Larger than usual due to \"Vehicle Plus\" project." "West"|"Transport, Logistics and Vehicles"|"37800"|"Above targets"
Repeating Text Qualifiers
Instead of using a specific escape character, another option is to repeat the text qualifier. With this approach, the text qualifier is being treated as its own escape character:
"Region"|"Category"|"Sales"|"Comment" "North"|"Hardware"|"25000"|"Doing great!" "East"|"Hardware"|"50000"|"Performing well /\_/\" "South"|"Hardware"|"50000"|"I'm happy with this." "West"|"Hardware"|"75000"|"Won the ""Hardware Sales of the Year"" award" "North"|"Transport, Logistics and Vehicles"|"12000"|"Below expectation | Expected 20000" "East"|"Transport, Logistics and Vehicles"|"28100"|"As predicted" "South"|"Transport, Logistics and Vehicles"|"31200"|"Larger than usual due to ""Vehicle Plus"" project." "West"|"Transport, Logistics and Vehicles"|"37800"|"Above targets"
How Does Snowflake Load Structured Data?
The above is a brief introduction to structured data. Specific file formats can be far more nuanced than this, and Snowflake is fully equipped to read these file formats. Before I highlight the key file format options that relate to the approaches that we have discussed, I would like to note that the full and up-to-date list of file format options can be found in Snowflake’s CSV documentation.
Let’s look at an example file to load into Snowflake. Consider the following CSV file:
"Region"|"Category"|"Sales"|"Comment" "North"|"Hardware"|"25000"|"Doing great!" "East"|"Hardware"|"50000"|"Performing well /\_/\" "South"|"Hardware"|"50000"|"I'm happy with this." "West"|"Hardware"|"75000"|"Won the ""Hardware Sales of the Year"" award" "North"|"Transport, Logistics and Vehicles"|"12000"|"Below expectation | Expected 20000" "East"|"Transport, Logistics and Vehicles"|"28100"|"As predicted" "South"|"Transport, Logistics and Vehicles"|"31200"|"Larger than usual due to ""Vehicle Plus"" project." "West"|"Transport, Logistics and Vehicles"|"37800"|"Above targets"
This file uses a pipe | as the field delimiter, new lines for the row delimiter and quotes “ as the text qualifier, escaping itself. The file also contains the field headers in the first row. This means there are several different elements that Snowflake must be aware of if it is to interpret the data correctly. Fortunately, Snowflake is prepared for this.
We begin by building out the basic building blocks of a file format creation statement. It is also good practice to always enter a comment:
CREATE OR REPLACE FILE FORMAT MY_CSV_FORMAT
TYPE = 'CSV'
COMMENT = 'Demonstration file format for CSV with default settings'
;
Record_Delimiter
This option defines the character that Snowflake will use to separate rows of data. By default, the new line character is used. As the file we intend to load also uses the new line character, no changes need to be made on this front.
Field_Delimiter
This option defines the character that Snowflake will use as the field delimiter. As mentioned before, this is usually a pipe | , comma , , caret ^ or tilde ~ . Snowflake’s default setting is a comma.
The file we are loading uses pipes | instead of commas, so we must inform Snowflake of this aspect of the file format in our definition statement:
CREATE OR REPLACE FILE FORMAT MY_CSV_FORMAT
TYPE = 'CSV'
FIELD_DELIMITER = '|'
COMMENT = 'Demonstration file format for CSV with FIELD_DELIMITER'
;
Field_Optionally_Enclosed_By
This option defines the text qualifier character. By default, Snowflake does not use this setting, leaving the entry NULL. If no escape character is set using the ESCAPE option below, Snowflake will treat the text qualifier as its own escape character.
The file we are loading uses quotes “ as the text qualifier, so again we must inform Snowflake of this:
CREATE OR REPLACE FILE FORMAT MY_CSV_FORMAT
TYPE = 'CSV'
FIELD_DELIMITER = '|'
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
COMMENT = 'Demonstration file format for CSV almost complete'
;
Escape
This optional setting determines the escape character to be used, overriding the default setting to treat the text qualifier as its own escape character. Our file uses the text qualifier character (quotes ” ) as the escape character as well; therefore, no changes need to be made and Snowflake will follow this by default.
Skip_Header
The file we intend to load includes the field headers in the first row. To avoid loading these in again, Snowflake needs to skip this row. The SKIP_HEADER option allows the user to define the number of rows that should be skipped when ingesting the file. This defaults to 0, with no rows skipped. Skipping the first row is equivalent to saying that we are skipping one row, so the value must be changed to 1:
CREATE OR REPLACE FILE FORMAT MY_CSV_FORMAT
TYPE = 'CSV'
FIELD_DELIMITER = '|'
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
SKIP_HEADER = 1
COMMENT = 'Demonstration file format for CSV with SKIP_HEADER now included'
;
Example Snowflake File Format and How to Use It
With the information above, the file can be loaded using the following file format definition. To repeat, we do not configure the RECORD_DELIMITER or ESCAPE options as we are using the default values. Again, it is also good practice to always enter a comment:
CREATE OR REPLACE FILE FORMAT MY_CSV_FORMAT
TYPE = 'CSV'
FIELD_DELIMITER = '|'
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
SKIP_HEADER = 1
COMMENT = 'Demonstration file format for CSV'
;
How to Load Data Using This Format
For example, assume we have a namespace called DEMO_DB.DEMO_SCHEMA, in which the data is staged in DEMO_STAGE and being loaded into DEMO_TABLE. We can inform Snowflake of the file format to load or unload our data in two ways. Both of the following approaches will achieve the same result and load the data into the table.
Option 1: Insert the file format details directly into the COPY INTO statement:
COPY INTO DEMO_DB.DEMO_SCHEMA.DEMO_TABLE FROM @DEMO_DB.DEMO_SCHEMA.DEMO_STAGE FILE_FORMAT = ( TYPE = 'CSV' FIELD_DELIMITER = '|' FIELD_OPTIONALLY_ENCLOSED_BY = '"' SKIP_HEADER = 1 ) ;
Option 2: Define the file format first using CREATE FILE FORMAT, then use it in the COPY INTO statement:
-- Create the file format
CREATE OR REPLACE FILE FORMAT DEMO_DB.DEMO_SCHEMA.MY_CSV_FORMAT
TYPE = 'CSV'
FIELD_DELIMITER = '|'
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
SKIP_HEADER = 1
COMMENT = 'Demonstration file format for CSV'
;
-- Use a previously defined file format
COPY INTO DEMO_DB.DEMO_SCHEMA.DEMO_TABLE
FROM @DEMO_DB.DEMO_SCHEMA.DEMO_STAGE
FILE_FORMAT = DEMO_DB.DEMO_SCHEMA.MY_CSV_FORMAT
;
Using either of these statements allows us to load the data into the table as shown below:
SELECT * FROM DEMO_DB.DEMO_SCHEMA.DEMO_TABLE
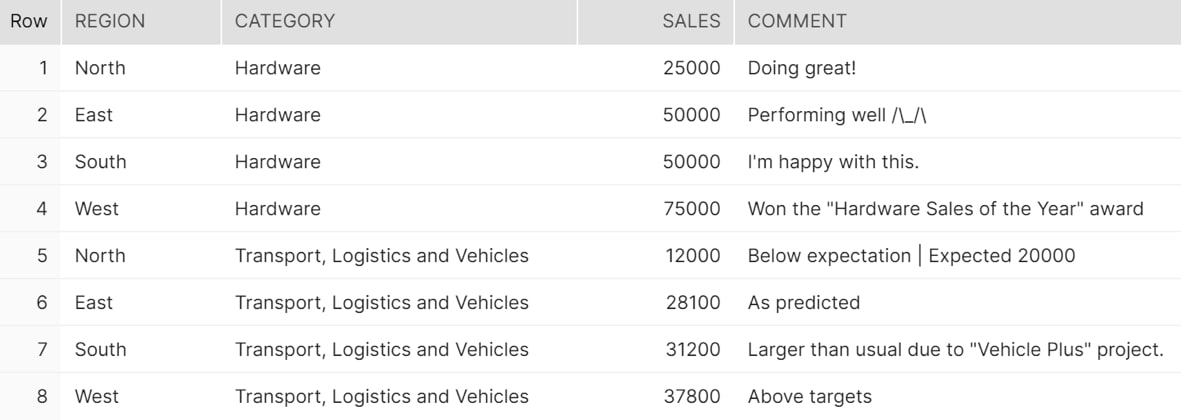
Above: The final table in Snowflake
Summary
Character Separated Values files are a common method of storing textual data, and Snowflake is fully equipped to handle this through the use of File Formats. Using the steps above, it is possible to load CSV data into a Snowflake table. Once the data is loaded, we can achieve a great deal of things using the smorgasbord of functionality which Snowflake has to offer. We will be visiting a wide range of functionality in future blogs, so stay tuned for more!