
This blog post is Human-Centered Content: Written by humans for humans.
Low Friction Development
As mentioned in the whitepaper on how to leverage AI to become a world-class dev team, AI has upended who is able to create solutions to business problems. Application development no longer needs to be funneled through a specific group within IT. Now, anyone from HR, finance, facilities, legal, and other departments that typically have nothing to do with computer code should feel enabled to build their own solutions.
Anyone who has practiced software development for any significant length of time may immediately cringe at that idea, because it’s relatively easy to create a working solution, but it’s much more difficult to create a secure and robust solution. It takes a lot of research, education, and hands-on experience to learn the proper ways to build software that isn’t full of holes.
Programmers surround themselves with guardrails. Agentic AI app development is no different. The problem is that people with little to no experience with writing software don’t know what they don’t know, so they can’t be the ones to put the guardrails in place.
Furthermore, unless it’s easy to deploy the apps within these guardrails, staff will take their newly found enablement to extremes and will figure out how to deploy them wherever they want, and IT security will be none the wiser. What’s worse than an insecure app? An insecure app that you don’t even know is out there leaking all over the place.
Tier-based Process
We developed a framework of Claude Code skills, template Git repositories, and an internal Claude plugin to standardize the app dev process. We decided to categorize apps into tiers based on how much security oversight they need and automatically adjust the process accordingly.
Apps built by someone for their own use are the lowest tier. As long as the app doesn’t leave their machine, essentially no oversight is needed. These are simple scripts or full apps that they will be the sole user and audience for, such as a personal to-do list or automation of some job function. They still adhere to best practices during development, but they are never really deployed anywhere, so authentication, authorization, network security, disaster recovery, etc. aren’t relevant.
Apps that are built for internal staff to use are considered tier 2. We have standardized and automated the deployment process for these apps where any exceptions need discussion and special handling. Tier 2 apps must undergo secondary code review once initial development has been completed. We’ve made the determination that AI-based code review for this purpose is adequate, as long as it is overseen by an independent developer. While this does open us up to the risk that an AI agent itself could be corrupted to inject nefarious functionality into the applications without being discovered, the risk is low enough that it’s not worth the extra overhead of requiring the human-in-the-loop to scour the code base on every app, since access will be limited anyway.
Apps that are built for our clients are considered tier 3. The deployment process for these is bespoke for each application. Unlike tier 2 apps, these tier 3 apps must be code-reviewed by a human. Additional scrutiny of the code base during code review scales with how sensitive the data and access is for each app.
Apps that are built for public consumption or multi-tenancy are considered tier 4. These are typically products that we sell or public-facing websites. Similar to tier 3, there must be a humanin- the-loop for code review where the scrutiny scales with the specifics of the app. Multi-tenancy adds another layer to ensure that client data isn’t leaked to other clients within the app itself.
Development Flow
All apps, regardless of tier, utilize a series of in-house developed skills that walk authors through project abstract, platform analysis, detailed requirements gathering, development, and multiple role-based AI code reviews. Each skill is specialized to a particular task and hands off to the next skill in the chain, so non-developer authors don’t need to know the full process before beginning.
The platform analysis phase is used to determine which platform-specific template Git repo to clone. These template repos contain focused guidance based on the best practices of that specific platform, including determining which types of automated testing are available and therefore will be required during the development phase. We did intentionally make the platform analysis decision slightly biased. It will go with whatever platform makes the most sense, but if any ol’ platform will do, we have it default to TypeScript since AI is really proficient at writing that code.
The requirements gathering phase will interview the author for all of the features that will be needed and build out a detailed product requirements document (PRD). For most apps of sufficient complexity, this skill will also build out a quick prototype as simple HTML files so the author can get an idea of how it will work and make adjustments as needed.
The development process is designed to be iterative similar to the Ralph Wiggum ideology. All iterations use a red/green test-driven development (TDD) approach to reduce hallucinations or unintended side effects. Each iteration starts with verifying the tests pass, just in case a previous iteration left it in a broken state. Then, the skill will analyze the PRD to pick which story to work on next. It writes the tests that should pass once the functionality is developed, verifies the tests actually fail (red stage), builds the functionality as simply as possible, runs the tests again to verify they now pass (green stage), and finally refactors the functionality to use best practices. Meanwhile, there’s actually a separate agent running alongside the main agent that acts as a pair programmer to catch issues early.
Writing documentation has become an afterthought for an entirely different reason than in the past. We don’t wait until the end and then explicitly have to remind ourselves to write documentation that matches what was built. The build skill is designed to write comprehensive documentation and relevant API endpoints as it goes. Not only does it write documentation for end users, but it also writes separate technical documentation for maintainers for the architecture of the app and how to use the API.
When the PRD has been fully implemented, the next skill will spawn multiple subagents to perform code review as different personas. These personas include obvious things, such as senior developer, SecOps, and QA engineer, but also include dedicated personas for accessibility compliance, user experience, legal, and others. These personas catch the vast majority of issues, which nearly always require a few more iterations of the development process to address before running another round of code review.
We’ve found that this level of code review tends to prioritize finding ANY issue over giving an all clear, which means it would get ever more nitpicky as major issues have been resolved and would result in an endless loop of identifying new issues. It would eventually get so nitpicky that the issues being identified were actually false positives that would counter-productively break functionality if they were addressed. We had to end up tracking previous runs and telling it that subsequent runs should only focus on issues with how previous fixes were implemented, and any other unrelated but critical issues that may have been missed during previous reviews.
Once the code review skill is satisfied, the next skill walks the author through deploying the app based on tier. For most tiers, this means involving a secondary person to perform their own code review. After the secondary code review, it would either take care of automatically deploying the app to the appropriate environment or providing the contacts to deploy the app manually when the deployment environment has more custom needs.
Tier 2 Deployment Solution
We created a solution to make deploying apps as easy and frictionless as possible. This mainly applies to tier 2 apps, since tier 1 apps aren’t really deployed anywhere and tiers 3 and 4 are bespoke for each app. Tier 2 apps are majority of solutions that staff are expected to build anyway.
We decided to standardize on Railway for hosting as it’s already very low friction to deploy to. Cost also scales nicely with usage.
We also needed to make authentication as easy as possible across all platforms so that each author didn’t try to build their own system with their own vulnerabilities. We landed on Cloudflare Zero Trust. This puts authentication before the user ever reaches the application and means that the applications don’t need to do anything with users unless they need specific user-based authorization/permissions, and even then, they can just pull the user information from the JWT that Cloudflare already sends in the request.
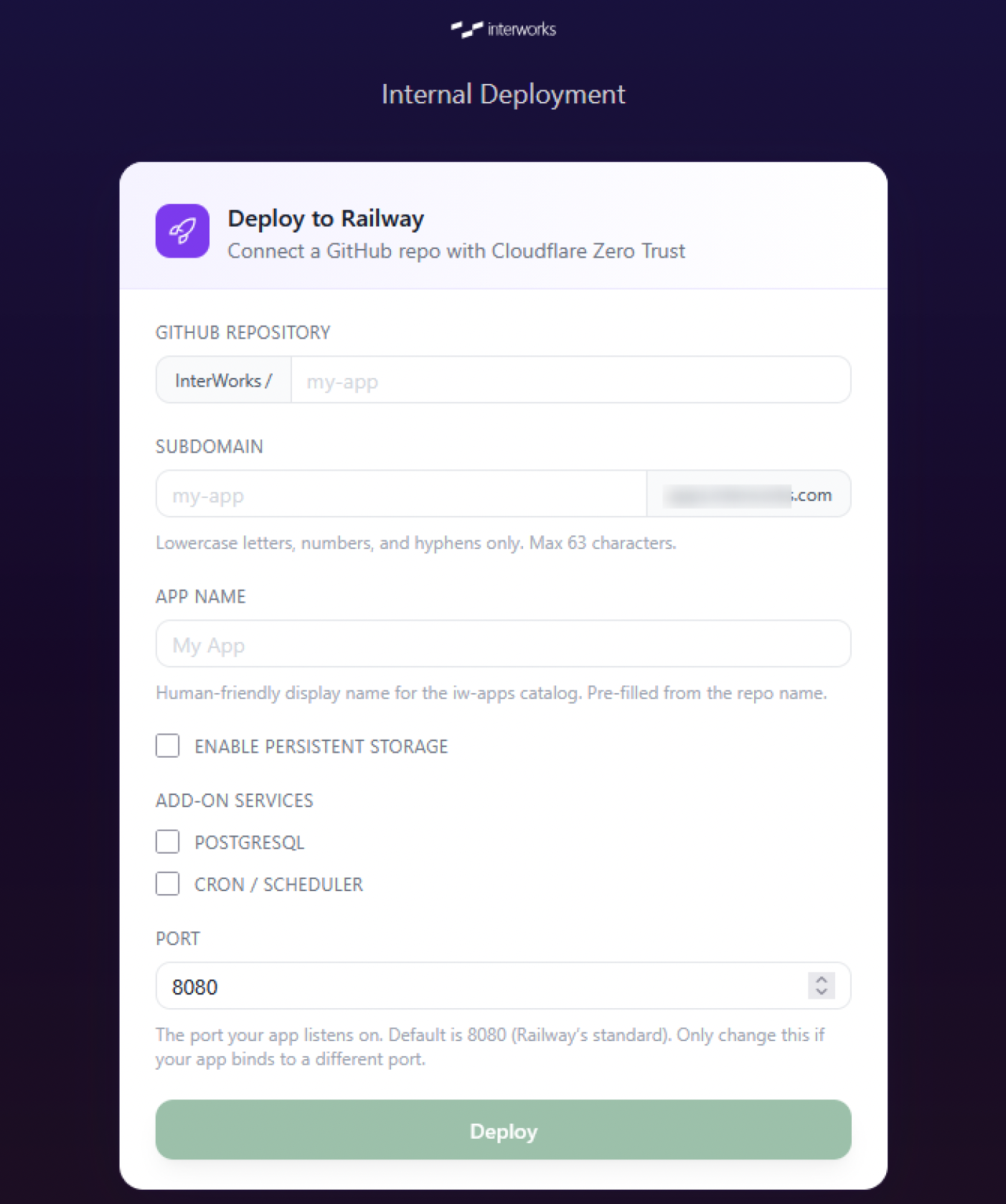
Next, we reserved a specific subdomain for these apps to live. Each app will get its own nested subdomain. This makes it easier for users to remember URLs and makes it simpler for IT to identify which apps are tier 2 just by knowing their URLs.
With these decisions in place, the next step was to automate them in a way staff could trigger on their own. This was actually the first app that was “dogfooded” by the agentic AI app dev process. To be honest, it was a really strange experience to build this app because it was like the cliché of building the plane in flight, Inception-style.
The internal deployment app accepts just a few questions for the GitHub repository under our company’s organization, whether it needs persistent storage, whether it needs a database, whether it needs a schedule/cron, and which network port the app will listen on within Railway. Once submitted, the internal deployment app handles provisioning the app awaiting deployment in Railway with the specified optional services, provisioning a Zero Trust tunnel between Cloudflare and Railway, adding a DNS entry, and registering the newly deployed app with our internal app catalog for discovery purposes.
As a side note, our internal app catalog can also function as a centralized utility to manage rolebased permissions over an API instead of every app needing to manage that for themselves.
The Experience from Start to Finish
For the TL;DR crowd, here’s what the overall process is like for a non-developer:
- Have a eureka moment that results in an idea for some app you want to build.
- Run a specific Claude skill to start the process, where it interviews you about the high level features the app needs. This decides for you which platform to build in, saves a project abstract, and tells you what skill to run next.
- Run the next skill to dive deep in the requirements and see a prototype. When satisfied, Claude will tell the author which skill to run next to start development.
- Run the build skill repeatedly to implement feature by feature in a red/green test-driven approach. When the PRD has been fully implemented, Claude will tell the author which skill to run for code review.
- Run the code review skill to perform a multiple role AI-based code review and rerun the build skill as needed to fix any issues found. When all issues have been addressed, Claude will hand off to the next skill.
- Run the deployment skill. This may require a secondary code review, and will either handle deployment for the author, or give them contact information for whom to contact to deploy it.
- At this point, the app should be ready to use and share.
Conclusion
We’ve seen this process go from idea to deployed app within less than a day for non-developers on admittedly basic apps. While Claude could knock out the same basic apps much quicker without these guardrails, the apps deployed using this process are much more robust and live up to our high standards without needing an experienced developer to guide the process.
If you would like help designing a process for your own organization, let us know. We would love to partner with you to come up with something that meets your own needs.