
This blog post is AI-Assisted Content: Written by humans with a helping hand.
Every organization right now feels the pressure to “do AI.” Executives want chatbots, business users want to ask questions in plain language and get instant answers, and someone in the boardroom saw a demo of natural language querying so now it’s on the roadmap. Demand is coming from all sides, and materializing any of those wins is easier said than done.
What gets lost in the hype is that almost every meaningful AI use case your organization wants to pursue sits on top of a foundation that most organizations haven’t actually built yet. That foundation is Modern Data Infrastructure (MDI). Without it, you’re not unlocking AI so much as you’re pointing a sophisticated engine at a pile of mismatched parts and hoping for the best.
I recently sat down with four InterWorks colleagues who specialize in rolling modern data infrastructure and are living this reality with clients right now to talk about what the path actually looks like. What is the foundation you need? What wins can you achieve with relative ease? Which AI capabilities are genuinely ready, and which ones still need time to bake?
What Does Your Data Stack Actually Look Like?
The starting point, before any AI conversation, is getting honest about your current data architecture. InterWorks’ Managing Director, America, Eric Shiarla frames the challenge this way:
“The question isn’t how do we add AI? It’s what does your data stack actually look like; what use cases are you actually trying to drive with it; and what’s the right mix of platforms, processes, and people to get there? We’ve seen companies do the whole ‘let’s push one vendor or the other’ thing. We’d rather take a step back and actually talk about what you’re trying to achieve.”
That framing matters because it changes the conversation from a technology selection exercise into something more grounded in outcomes. Three principles tend to hold regardless of what stack an organization ends up with:
Focus on intent instead of tech. Start with the problems you’re actually trying to solve before picking a platform. Even with strong opinions about Snowflake or Databricks, the first conversation has to be about the challenges you’re looking to tackle.
Design for scale and change. Data contracts, Medallion Data Architecture, data mesh principles — these structures keep organizations from going off the rails when team composition changes, data volumes grow, or business requirements shift.
Prioritize trust as the KPI. Data lineage, quality controls, access controls — these are how you earn the kind of trust that makes AI outputs actually usable.
You can read more about those modern data infrastructure principles in this blog post from Eric.
Problem: Multiple Sources of Truth
When organizations hit walls with AI initiatives, the culprit is rarely the AI itself. InterWorks Senior Data Architect Matt Woods explains what he sees most often:
“The biggest risk to implementing anything, whether it’s AI or analytics, is multiple sources of truth. If you’ve got multiple sources, you’re going to get different answers for the same question. Where most companies fail is not adhering to the process they’ve laid out, and making exceptions here and there. Then it goes off the rails real fast. That solid foundation is critical for everything, especially AI.”
Eric adds an important dimension to why this problem is harder to catch with AI than with traditional BI:
“When you’re in Tableau and connecting to the data, you’re pretty intimately familiar with it. You have to be in order to construct anything useful. So, you’ll be asking questions along the way and verifying your work. One of the big risks with AI is that there’s just less verification happening. People are very willing to accept answers without any sort of scrutiny.”
InterWorks Principal Consultant Chris Soule has seen this dynamic play out directly where every team runs their own ad hoc tables, analysis and reports. The result is constant confusion about what the center of truth actually is:
“Often, every team has different reports and different transformations to get to different things. As the journey toward AI begins, letting AI look at the data and answer questions, they realize that they really need to do an overhaul before anything else. That means building smart data models that actually work together and speak to the same thing.”
The architecture decision that often comes out of that situation is Medallion Data Architecture combined with Kimball methodology to build star schemas with proper joins — clean, validated, joined-up data at the top layers before asking AI to reason over any of it. Medallion Data Architecture is also platform-agnostic, which is part of why it’s become such a common pattern. You can learn more about Medallion Data Architecture in this post from InterWorks’ Senior Data Architect Mike Oldroyd. Here’s a snapshot:
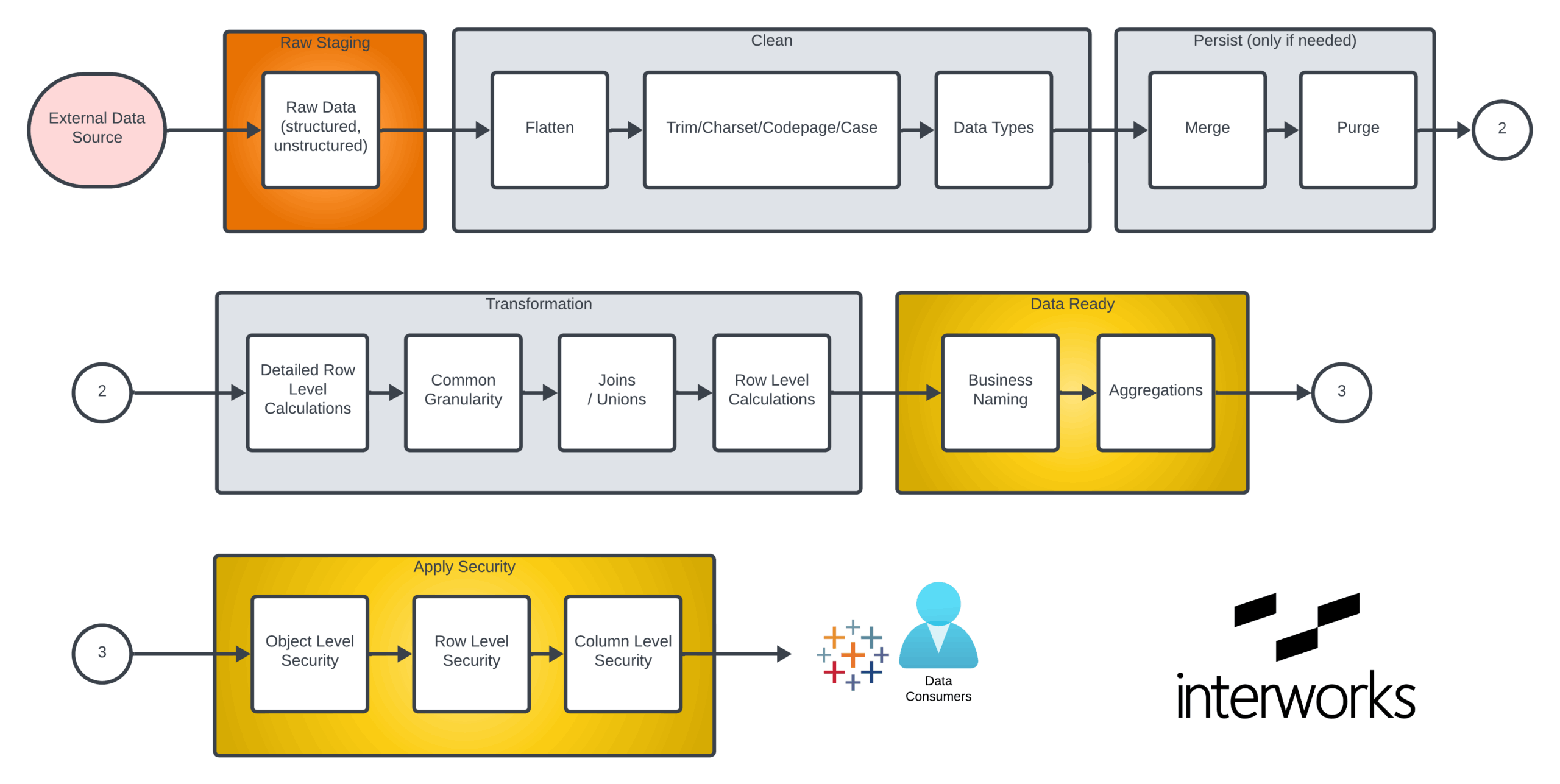
But there’s more to the equation if organizations really want to sustain success. Matt Woods points out that architecture alone isn’t enough:
“A lot of it is just process. Different groups want to pull data from different layers of the Medallion Data Architecture. The key is to ensure you’re pulling from gold for everything as there aren’t going to be two different versions of the same gold metrics because somebody wanted to pull silver data and create their own flavor on it. Automated controls to enforce that as part of the process is a huge deal.”
3 Layers of Unlock: What Modern Data Infrastructure Provides
One useful way to think about modern data infrastructure is as a set of stacked layers of capability. None of these are strictly linear, but each level of maturity opens up things that weren’t accessible before.
Layer One: Process-Level Wins (Available Right Now)
Before anyone buys a new platform or signs a new contract, there are substantial gains available just from cleaning up data processes and giving the right people the right tools.
Chris has a perspective here that might be categorized as an “unpopular opinion,” but it’s one that resonates with what he’s seen in practice:
“Businesses are attracted to what AI can do for end users a lot of the time, and there’s some value there. But if they just focus on what it can do for the end user, it’s really shallow. The better use case is: I have really smart people, engineers, doing the hard stuff every day. If I put these tools in their hands, what can they unlock, and how much more efficient can they be? It’s not about making those people work less. There’s tons of evidence now that when you give these tools to engineers, they end up working more, or at minimum more efficiently, because they’re so charged up with what they can do. I myself went through this.”
In some organizations, the engineering teams adopt tools like Cursor and Windsurf for setting up folder architecture scaffolding, writing documentation and accelerating the more repetitive parts of development work. The gains are meaningful and immediate — not because the AI replaced anyone, but because it compressed the time between idea and implementation.
Chris also points to a more subtle but equally valuable application: using LLMs to scan communication streams across Slack, Teams and email to surface where attention is most needed:
“It’s become very popular because you can tell it what’s important to you. It’s superior to the built-in native features that attempted to do the same thing.”
For more complex data operations, AI is also proving valuable in the middle of pipelines rather than at the front end. Chris describes one solution he built for a client receiving CSVs from over 250 different organizations, all in slightly different formats with slightly different field names:
“I was thinking about a solution inside of Snowflake: using Cortex and Cortex-Complete to specify mapping tables, have it look at the CSVs, auto-create mapping tables, and have a human in the loop verify that the definition is correct before feeding it back into the ingestion cycle. Instead of a human doing this across 250 clients, you let AI read through the files and propose the mappings while the human validates. That’s a real operational unlock.”
Matt echoes the value of AI embedded in the development process more broadly:
“Being able to leverage AI in the middle of the dev process and really helping create a solid foundation while you’re also using it is a big part of the story. The more visible front-end AI features get a lot of attention, but it’s the middle-of-the-organization tools that are producing the real traction right now.”
Layer Two: Platform-Level Features (When You’re on the Right Stack)
Once the data architecture is solid and teams are on platforms like Snowflake or Databricks, a second tier of capability opens up: features that exist today and are making teams meaningfully more productive.
Matt has been watching this closely with clients:
“Both Snowflake’s Semantic Autopilot and Databricks’ Genie are able to create semantic and metric views from existing Tableau and Power BI workbooks. For organizations that have spent years building out Tableau dashboards, this is particularly valuable as that prior work can actually inform the development of the semantic layer in a significant way. Significant hands-on work still needs to be done to add business context, complex logic and governance, but these tools can cut much of the grunt work out of the process. We expect both to mature very quickly.”
Both platforms also analyze query history to help define which queries are being used for analytics and what they mean. Matt describes the workflow:
“Both platforms will go through your query history and work from that to help define what queries are actually being used for analytics and what they mean. You definitely have to have a human in the loop when developing the semantic layer; but once you have a solid one built off of solid single source of truth, then you leverage any of the tools that can talk with that — whether it’s Sigma or any AI agent — and you’re going to get much better quality information out of your AI.”
Where AI is currently delivering the clearest traction, according to Matt, is around trending and comparative analysis:
“We’re seeing clients leverage AI tools combined with their existing data to generate good general information, particularly around things like trending and comparative analysis. Generating consistent, specific metrics out of AI-based solutions often requires a solid semantic layer and SSOT, but trending and comparing different products, services or regions can be effective for most companies that have a decent data foundation.”
Global Director of Product Ben Bausili adds an important nuance about what a semantic layer actually needs to support AI well, and it’s more than most people expect:
“There definitely needs to be even more added to the data than we’d expect from BI reporting. The semantic layer is one part of it, but it isn’t enough on its own. There are also the prompts you put into the agents, the skills if you’re connecting to something like Claude. This includes all the context around how these people think about the world, how do they use the data and how they want it presented to them. All of that has to be developed and maintained, as well.”
Layer Three: The Aspirational Tier (Prep for What’s Coming)
This is where most of the marketing hype lives: natural language querying that lets any business user ask their data questions in layman’s terms and get accurate, trusted answers. It’s a genuinely compelling vision. It’s also not entirely ready. Chris gives an honest assessment:
“Querying data with natural language is still not 100% trusted. There are still too many variables. I spoke with a team that was testing capabilities between Databricks and Snowflake, and they mentioned that in Databricks they tested a model where they had labeled specific joins to answer certain questions. They were able to get the natural language querying to ignore the joins they specified. That’s a problem. AI and NLQ will need maintenance, tuning and intermediate validation to remain ‘close enough’ for the majority of use cases.”
Matt echoes similar thoughts:
“NLQ is cool. Everyone wants to do it. But realistically, everyone already has reports in front of them showing those metrics. It’s a nice trick, but it’s getting less traction than the middle-of-the-organization tools. It’s not magic. When you get down to key KPIs for businesses where accuracy is critical, it gets a lot harder.”
One meaningful step Snowflake has taken is allowing verified queries to be added to the semantic layer for the most common questions. When someone asks one of those, the system uses pre-validated SQL rather than generating something from scratch. Chris does highlight one key limitation:
“It adds more verification to the process; but you’re still dealing with a chatbot, so people are going to ask tons of questions you did not plan for. That’s when it has to default to reasoning from what it knows about columns, tables, descriptions and how things join together to construct the query itself.”
Eric emphasizes why this honest assessment is actually a service to clients:
“From the InterWorks perspective, our job is being able to share what is practically working today, and what still requires more time to bake. This is key to our credibility ensuring that clients aren’t wasting time on proofs of concept that aren’t ready yet.”
None of this means NLQ or agentic AI are vaporware. Matt points to one client in the medical field who illustrates exactly what it looks like when the aspirational tier is approached correctly:
“They’re about a year into their Databricks implementation. They spent that time building a solid single source of truth and a sustainable platform, and they’re only now getting to the point where they’re ready to leverage the platform to optimize their billing, coding and even pricing. That’s something that traditionally would have been a full machine learning effort. It took them a year, but they did it right. Now they’re approaching it with agentic AI instead of having to go in and do a bunch of machine learning directly. Again, it’s not magic, but they actually built the foundation.”
The broader point: Companies with solid data foundations are getting more early traction with AI tools, and they’re ready to move when capabilities mature rather than scrambling to catch up.
Don’t Sleep on the AI Cost Optimization Angle
One dimension that often surprises organizations is how quickly AI usage costs can escalate. Eric puts it in perspective:
“Organizations thought Snowflake or Databricks compute costs were high, just wait until all your developers have access to AI models and are consuming credits on long, context-heavy conversations.”
Chris offers a concrete example of cost-conscious AI usage from his own work:
“I was going to use AI to crawl our Git repository and check for rule violations on every merge request, basically like a linter, but I realized how many tokens that would burn. Instead, I used AI to build a Python script that checks all the different rules of the medallion architecture at each layer and makes sure the models being developed don’t violate them. The Python script does the checking. Only the flagged issues go back to the AI for focused review. Then I built a feedback loop for any false positives found during human-in-the-loop review to feed back to the model and improve the script over time. You can really save money by being conscious of how you’re spending your tokens and whether AI is actually the right tool for each specific task.”
Matt summarizes the principle:
“Getting smarter about it is what everyone needs to do. Having AI in the right hands is very important, not in everyone’s hands indiscriminately.”
Ben adds a governance angle that extends the cost conversation into data quality:
“The danger of self-service is always that people produce a lot of ungoverned content that may not be high quality. We saw that with Tableau. People produced a ton of dashboards, and it became a governance problem. AI is allowing people to produce even more things, even faster. I’m all for empowering people, but companies need to find a balance between enabling end users and empowering engineers to do work that’s sustainable and scalable.”
MDI and AI: The Bridge Worth Building
The promise of AI for data and analytics is tangible, but so is the temptation to reach for it before the underlying conditions are in place. Eric frames the opportunity:
“You have to think about the 80% of companies that sit between large enterprises and startups. These are organizations that, over the next 10 years, need to take advantage of these approaches and technologies. They’re going to need help walking through getting this set up the right way and ensuring there are controls over it over time so they can trust it. That’s true not only when it’s first implemented, but over the course of a year or two years as models drift and data changes.”
Matt closes with the point that often gets missed when organizations are chasing the marquee AI features:
“To me, the most interesting part is when you set out to do a thing with a specific goal in mind, but the value turns out to be somewhere you didn’t expect, like actually empowering data engineers and unlocking clarity they didn’t have before. It’s finding value where clients didn’t expect it, but it’s still just as valuable.”
The organizations that will get the most durable return from AI are the ones that take the time to ask what they’re actually trying to achieve, build the data architecture to support it, enforce the processes that keep that architecture coherent over time and put the right tools in the hands of the people best positioned to use them. Modern data infrastructure isn’t the thing that delays the good stuff; it’s what makes the good stuff actually work.
You can go do all the AI things, and some of them will produce results even on a messy foundation. But the ones that really matter — the ones that change how your business operates and that your organization can actually trust — those require keeping your house in order first through paradigms like modern data infrastructure.
Need Help with Data Architecture and AI? We Got You!
If you’re ready to start discussing concepts like modern data infrastructure or are curious about how to set up your data architecture for specific AI use cases, our team would love to help! Reach out today to start the conversation.
