
This blog post is Human-Centered Content: Written by humans for humans.
Most organizations are on a quest for meaningful AI solutions, looking at different ways to implement new tools into their stack. A recurring pattern in these initiatives is the gap that quickly opens between the high promises and novel buzzwords on one hand, and the daily reality of end users on the other hand. Users with business experience and tribal knowledge prompt a request and get an output that might seem plausible to an outsider, but usually requires constant re-prompting, manual checks and reconciliation with “official” sources to become appropriate for usage. Instead of high adoption, users gradually lose their trust and treat their AI agent like a quirky intern rather than a reliable partner. It is not because the underlying models are weak, but because these solutions lack context: An “income” can mean one thing in a retail business and another thing in banking. A two-hour data lag might be perfectly acceptable for yearly aggregations, but disastrous for live traffic control.
Paris 1972: WET PAINT, Signatures and Invisible Context
Picture a bright, echoing atrium in a Parisian university in the early 1970s. On one freshly painted bench, a handwritten sign is taped: “WET PAINT.” By the next morning, the paint is dry but the ungoverned sign is still hanging. The chatter of passing-by students echoes through the space as they assess the risk of taking a seat – until someone from yesterday’s class shows up to offer first-hand testimony, effectively certifying the bench as safe.
In one of the offices opening onto that atrium, a philosopher named Jacques Derrida is working on an essay titled “Signature Event Context.” Derrida asks, “What do signatures mean once they leave their author’s hands?” A signature feels like the ultimate guarantee of presence and intention, yet it only functions because it can travel. Your inked initials appear on mortgages, birthday cards, scanned copies and court files, long after you have left the room. On a postcard it is affectionate, on a loan agreement it is binding, in a lawsuit it may become incriminating. Like the “WET PAINT” sign, the mark does not carry its meaning by itself. For Derrida, that meaning is produced by context. Who reads it, when, under which rules and institutions. We trust marks every day, but we almost never see the full context that makes them true, binding or dangerous. Our data and AI systems are full of similar marks and blind spots: They, too, need context and validation.
Data Marks in 2026: “true” Is Not the World
Imagine an AI assistant querying a customer record and encountering a stored value like approve_loan = true. To the system, it is just a convenient “true” that requires the simplest binary processing. To a dashboard, it is a dimension that rolls up into a “conversion” metric. To us, it looks like a simple fact: The loan was approved.
But in reality, it is a record that, in some system, at some time, some job or person set that field as true. In one context, this value might be from a sandbox dataset made for testing. Somewhere else, it might stem from an outdated snapshot that failed to update due to a broken pipeline. It might have been triggered by a complex automation or simply typed in by a human, and both might have gaps and errors in them. All true labels look the same – but they are marks of varying underlying realities, which in turn can expire and change over time.
This is where many production‑grade AI initiatives underdeliver. We treat stored values as if they were direct reflections of reality, instead of traces that need to be interpreted through lineage, environment, and shared business semantics. Without these foundations, the ordained “source of truth” can be degraded to “whatever table the AI agent can reach with least friction.”
The result: Frequent ad‑hoc checks, reconciliation between finance and product numbers, compliance reviews that block go‑lives, and pilots that never graduate because their behavior under real load cannot be fully trusted.
Operational Metadata: A Living Context Layer is Becoming the Key Enabler
A well-governed context layer can be the force multiplier for AI initiatives. Think of taking the train: Even for a well-travelled passenger (the agent in this case), a lot can go wrong if their only resource is a printed timetable from last year (an ungoverned data source). But an official app with live departure times and routing alternatives can save their day even in face of disruptions or strikes.
While the semantic layer standardizes the meaning of metrics, a full context layer goes further to operationalize your metadata with organizational intelligence and guardrails for AI to act on:
- A data catalog with technical metadata (schemas, freshness, quality signals), business metadata (owners, definitions, KPIs, domains), and usage metadata (who queries what, from where).
- End‑to‑end lineage, ideally to column level.
- A glossary layer enabling queries against stable concepts rather than guessing table and column names.
- Policy‑as‑code and access controls that attach to those concepts and fields: Classifications, jurisdictional constraints, purpose limitations and row/column‑level access, enforced consistently across SQL, BI tools and AI services.
- Support for unstructured and semi-structured data.
- Environment and lifecycle context: Dev/stage/prod boundaries, deployment history, model and schema versions, with clear signals that AI can use to avoid training on or acting from the wrong environment.
Atlan, the Context Layer for AI, allows organizations to close the context gap that makes so many AI initiatives stall. The Context Layer operationalizes your metadata to make AI agents and tools your own: it functions as the living substrate that makes AI’s sources legible, its behavior trustworthy, and its context continuously improving.” The context layer operationalizes your metadata to make AI agents and tools your own: It functions as an operational map and as the substrate that makes AI’s sources legible and its behavior safe in a complex stack. Data can be tracked to its source, its freshness can be verified and the essence of competing assets differentiated.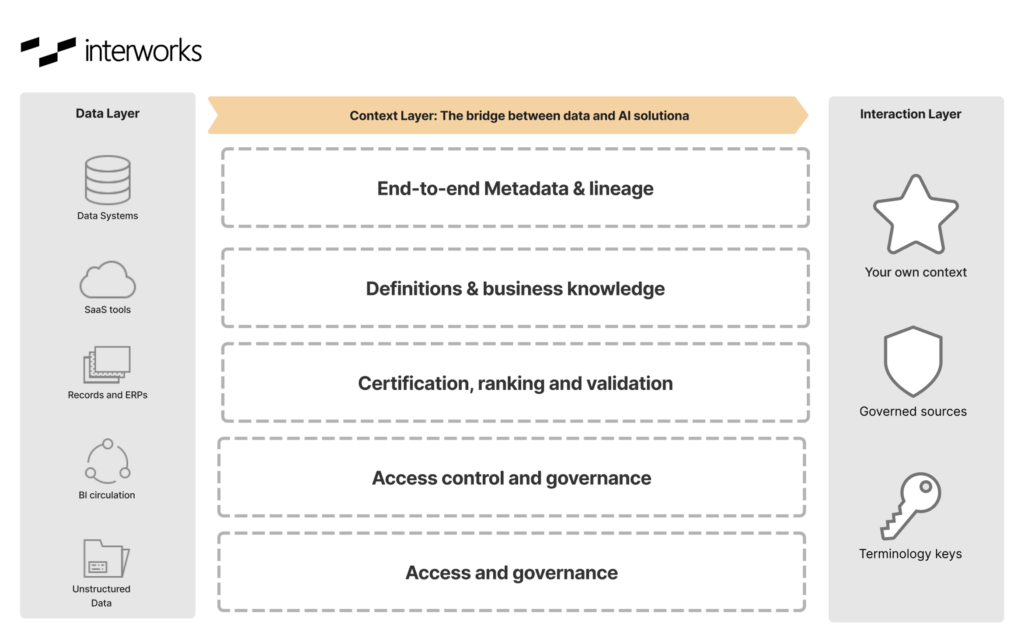
Governance as an AI Booster
Once the context layer is in place, governance stops being a reluctant permission slip and becomes a booster. When a conversational interface is connected to the warehouse, the generated queries will hit governed metrics, certified data products and the right environment by default. It becomes feasible to build agents that choose tools and datasets based on catalog metadata (“only use gold‑tier, in‑region sources for this workflow”), instead of hard‑coding table names into prompts. You can push a change to a core definition and see, via lineage, which models, dashboards and AI workflows will be affected before you ship.
Transport Derrida into a governed, context‑rich data ecosystem and his examples change shape. “WET PAINT” signs come with timestamps and auto‑stale after 24 hours. Signatures are backed by authentication and authorization workflows, audit trails and non‑repudiation guarantees. The marks are still there, but they live inside a fabric that constantly refreshes and checks their meaning against reality.
The recurring pattern is that real-world AI solutions that materialize beyond the impressive demo are those that can be safely embed in workflows, products and decisions. The differentiator here is the Context Layer: the Enterprise Data Graph, semantic models, lineage, policies and environment signals — all working together, continuously updated, serving every AI agent from a single source of truth. This is the piece many teams didn’t know they needed, and the one that decides whether production AI quietly disappoints or becomes a true game changer.
Creating a good context layer the covers your full stack requires the right tools, expertise and strategy. Reach out to InterWorks to learn more about the governance and metadata best practices to customize your AI experience to your organization.