
Python is quickly becoming the first programming language exposed to non-tech folks. While working on my data pipeline, I found a perfect example of how you can use Python to bring external data into your reporting environment – especially when the host of this data doesn’t have an out-of-the-box database connector.

Above: What I think the Python logo should have been.
If you read my last blog post introducing Matillion, then you have a high-level understanding of what I want my data pipeline to do to analyze my running performance. While building out my data collection processes, I ran across something that I thought could be very beneficial for those looking to bring external data into their internal reporting environment. In this post, I am going to show you guys how to use Python, REST APIs and AWS services to automate external data collection.
If you guys want to follow along and build this out in your own reporting environment, you will need the following:
- AWS account with access to S3 and Lambda
- General Python knowledge (or excellent “Google-fu”)
- A Target REST API
- ETL tool with S3 Connector
- A database capable of parsing semi-structured data (I will use Snowflake)
Serve Up Fresh Data on a Consistent Basis
By far my favorite thing about the way technology is trending is that it gives you limitless opportunity to be lazy and look smart. What do I mean by that? In this project, I wrote a Python script that grabs data from Dark Sky’s weather API and uploads it to S3.
I loaded that script into an AWS Lambda function, so I never have to manually run that script. This function runs whenever I tell it to, whether that’s a text message trigger or an AWS IoT button. By putting in some work on the front end to write the script and build the function’s triggers, I can literally collect real-time data after I run with the push of a button. That’s efficiency, and you can do it, too.
The Script
The first requirement is to write a Python script that collects the data you want. There is basically an infinite number of REST APIs serving up semi-structured data, so your script will look different depending on what you want to collect. The core requirements will largely remain the same: You want to hit an API, write a file and then upload that file to S3.
There are a handful of Python modules that make this process flow smoothly. You will almost always be using the requests, Boto and JSON modules. Below is my script for pulling data from the Dark Sky API:
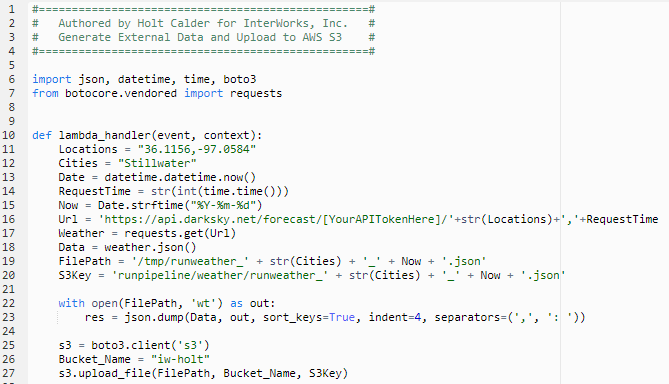
While the script is fairly straightforward, there a few things to be aware of:
- Importing external libraries can be a little bit weird. Lambda comes packaged with Boto3, but if you want to use additional libraries, you will have create a Deployment Package (documentation here). For known libraries that you can’t seem to get to work right away, it can take some Google-fu to figure out how to pull them out of botocore (e.g. importing requests above).
- Lambda utilizes a lambda_handler to execute your commands. You can define this however you like, but it is important to note that the handler must be defined as: “[File Name].[Function to Execute]. For example, my function is named “lambda_handler” and my file name is “lambda_function” – so I specify my Lambda Handler in the AWS Console like this:

- Lambda spins up a server for your code to execute on in extremely low time intervals. This means that the file system is a little bit different. Notice in my FilePath variable that I am writing files to the tmp directory. As soon as the function concludes, the file is lost forever along with the machine.
Lambda
So, now that you know more about what goes into the script piece, let’s get to the fun stuff: Lambda functions. When you log in to the AWS Console and navigate to the Lambda dashboard, you will have a list of functions that are already created in your environment, if there are any. From here, we can either edit the existing functions or create a new one:

When I begin creating a new function, I have a few options: I can author from scratch, configure a function from a blueprint or access published Lambda functions through the Serverless Application Repository.
For this example, I will author the function from scratch. It is important when creating a Lambda function to ensure the role assigned to it has the correct permissions for what you want it to accomplish (e.g. granting this function access to S3). Also, here you can select what kind of code you want to deploy in the Lambda function.
After specifying my Lambda function’s name, runtime and access rights, I can get into the actual configuration:
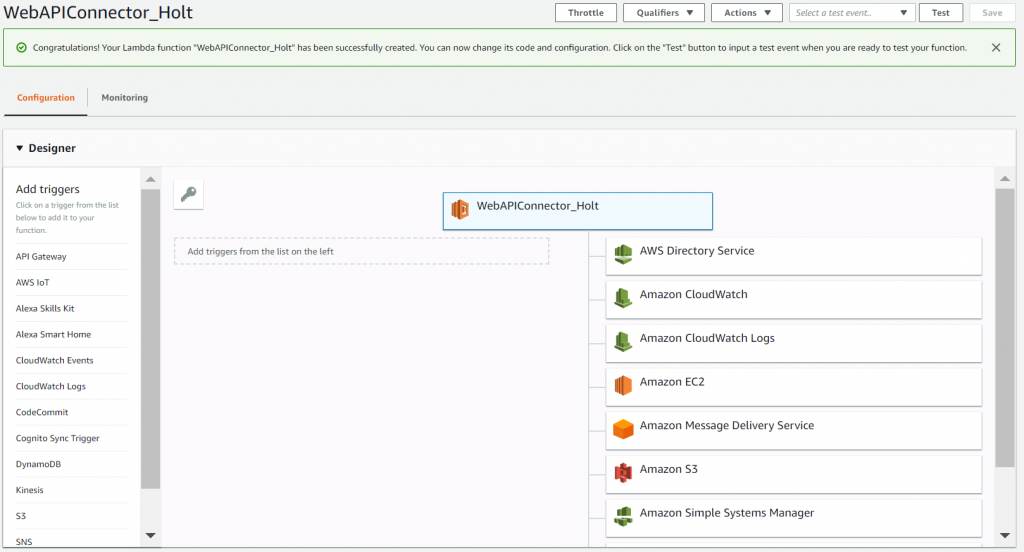
Above is the diagram of what my Lambda function can interact with. On the right are all the AWS services that the role connected to my function has access to. On the left are the various triggers I can configure to kick off my Lambda function. The triggers are arguably the most valuable piece of Lambda. Based on different activity within my environment, I can configure my code to run immediately, making the process of collecting data completely hands-off.
For my collection process, I purchased an AWS IoT button that I will use to trigger my Lambda function. This will work as a physical button to collect data, which is kind of cheesy but makes sense for my use case. At the beginning of my runs from now on, I will click the button and snatch all the weather data from Stillwater for that point in time.
After selecting my trigger, I can scroll below and put my Python code in the IDE. From here, we are almost finished with the function. All we need to do now is specify a Timeout setting that allows our code enough time to execute, sit back and reap the rewards of our hard work.
Why Should You Care?
While you may not be interested in collecting weather data referencing a specific point in time, the process I just walked you through can be used to collect data from almost any API with Lambda. Thanks to AWS Services, we can customize the collection of data and trigger that process however we want.
This makes significant impact for businesses wanting to utilize data from services that does not come packaged with a Database Connector. You can create your own connector and retain ownership of that data in your own warehouse, which is a perk within itself.
Now that we’ve got a clean collection process, we are staged and ready to move on to the next piece of my pipeline: ETL with Matillion to Snowflake. (Tableau dashboard coming soon)
If you have any questions about how to use Python and Lambda to beef up your reporting environment, please feel free to reach out to me directly or on LinkedIn!