
This is a blog series about our new storage solution: the Discovery Series from DataGravity. It covers why we selected the solution. We'll continue through our initial journey from selection to standardization, deployment and testing.

DataGravity – Discovery – Where It Started for InterWorks?
In my role at InterWorks I help with technology direction, and given that, I receive a ton of attention from technology vendors eager to show me why their solutions are better. I source some new technologies, attend conferences, receive inbound calls and have talked with nearly everyone in the storage space. To be honest, I wasn’t really looking for anything new — we are extremely happy with our current storage offerings.
Even as new technologies on the marketplace may have a small advantage here or there, there hasn’t been anything different enough to cause us to dive in. The conversations usually lead to “this all looks great, here’s what I like, here’s where I see some need for improvement, but at the end of the day, I don’t have a need for what you are selling”.
Until I looked into DataGravity. So, why DataGravity?
Speed and Capacity
Technically, the solution is well rooted and designed by industry proven storage engineers. The company was founded by Paula Long and John Joseph, two industry professionals with a long history in the EqualLogic product line. The current solution ships with a computing enclosure containing dual controllers and flash storage, and a storage enclosure with NL SAS storage. The storage enclosure connects via SAS, additional enclosures can be added to the chain, plus more flash storage can be added into the computing enclosure.
They deliver an expected balance of capacity and performance, and that’s one of the first requirements of any storage solution. More will come on specific benchmarking later in the series.
Reliability
I mentioned above the dual controller setup, and it’s definitely not traditional – rather than active/active, or active/passive, we need to think of things as active/intelligence in this solution.
The array provides deep analytics capabilities into the data, and the secondary controller’s primary function is to process the analytics data. In case of a failure of the primary controller, the analytics data processing halts, and will get caught up on once the primary controller is back online. The array is protected with RAID, naturally.
Many people have asked about hot spares – and the answer to that is yes and no. There are no dedicated hot spares, but out of the box you have a pool of unallocated storage. If you have a failure in your primary or intelligence storage pools, an unallocated disk will be assigned to rebuild the RAID set. If all of your unallocated pool is assigned, then you’ll still be covered by the RAID policy, and a rebuild will happen once the disk is replaced. A couple of quick views from the System Health page are below so you can see the 2U computing enclosure with flash storage & 10Gb, and 4U storage enclosure with SAS connectivity.

Discovery Series Front View
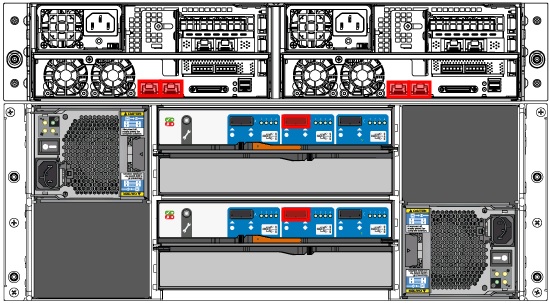
Discovery Series Rear View
Protection
Everyone does the equivalent of snapshotting – though called many things, they capture the state of your data at a point in time. There are three main differentiators with the discovery series, in their discovery points (snapshots).
- Storage – They store the discovery points in the intelligence pool – away from the primary pool, on a different RAID set, on a different set of disks. Browsing and searching on the discovery points won’t affect production storage.
- Quiescence – Most vendors provide some form of consistent application snapshotting. On busy VMware environments, the stun effect of a VMware snapshot is oftentimes unacceptable during production. DataGravity has built something special into this operation that minimizes the impact on the virtual machines. The VMware snapshots are nearly instant!
- Scheduling – Extremely flexible in terms of schedule, plus retention period based on that schedule. No more simple hourly, or daily, with a fixed retention period. Look at the available options below, and consider something malicious – user mass deletion, variant of crypto locker, etc. you can define a special snapshot based on change rate, along with flexible time windows.
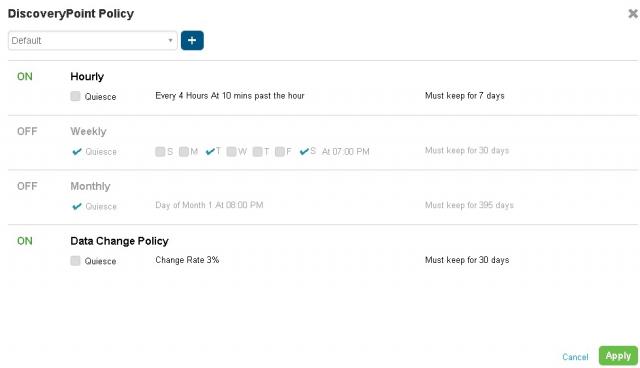
Discovery Series DiscoveryPoint Policy Configuration
Protocols
Out of the box without anything special supporting iSCSI, NFS, and CIFS/SMB without additional licensing or appliances. Sure, you can say it’s missing Fibre Channel or FCoE, but there’s enough here to provide a solid option for connectivity. One mention is with the current release, you gain a deeper insight into your VMware volumes utilizing the array’s Datastore type – which is a volume presented to VMware over NFS. Utilizing this will permit you to see the virtual machines, and more specific information on a virtual machine level.
Support
From day 1, as soon as they ship, they are offering top notch local support, with 24/7 availability, and same day parts availability.
I’m going to say that again so it isn’t missed by the folks that just scan these articles:
From day 1 they are offering top notch local support, with 24/7 availability, and same day parts availability.
What other recent storage company has been able to do that? They’ve really got their customers’ needs in mind. No need to buy spare parts kits.
Analytics / Insight <- This is the really amazing part!
This is the game changer here, and what ultimately sold me on my support of the solution. Everything mentioned above is very acceptable, but it wouldn’t be enough to get my support of embracing a new technology. Looking into the VMware data store to provide information on the virtual machines has been done before utilizing APIs and references, but who has dissected the data as it is being read/written? They do, and it provides a ton of useful insight.
More important than that, think of user data. That’s the key with the Discovery series. Consider these questions:
- Who is taking up the most storage?
- Who has accessed this file?
- Who all has worked on this document (collaboration)?
- Where is this file or content?
- When was this content changed?
- What is taking up my storage (server or document type)?
- Where’s my dormant data?
When you consider that this is part of the total solution, it’s pretty amazing what is going on here. You’ve got it all covered.
Another very interesting metric: Most Active Users. If someone is dumping data into the system and filling up shares, if they start doing a mass delete, or if they start to just consume & possibly copy off the data – that’s all covered too.
Compliance and Legal Issues
Take that even a step further, think compliance and possible legal issues. There are regulations changing all around, no longer are we just concerned with HIPPA, SOX, PCI DSS, FISMA, etc. standards, there are penalties, fairly severe too for loss of PII (personally identifiable information). There are tags defined in the system for:
- credit card numbers
- social security numbers
- email addresses
- and others
The array will report on that data and let you drill in to see the files to confirm things. You can see who owns, has accessed them, worked on them.
This is the amazing thing that DataGravity built into the Discovery series, without additional licensing fees. Seems crazy, right? Again, this was the game changer for me, no more is this just an IT function of speed and capacity, this works into your legal and compliance departments, helping to protect the company’s data from the ground up.
More to Come
Expect more content to come out in the coming weeks, as I go through some of the topics in more detail, and generally will go through our architecture, migration, and testing processes. If you’d like any further information on the solution, please don’t hesitate to reach out! We’d love to answer any questions you have, and it doesn’t matter where you’re located – we’re all over the place too!
If you haven’t yet, be sure to check out our other posts within this series:
- Introduction – Why Data Gravity?
- Acquisition / Cabling – Initial Impressions
- Preparations / Network Architecture
- Initial Configuration