
Data workflows are like hiking boots — good-fitting ones can take you anywhere. Ill-fitting ones spawn misery.
As you document the existing workflows in discovery meetings, these details will influence your software selections — the tools for the data workflows. The amount and type of work necessary to achieve the desired results will be affected by your choices. Ask your consulting partner to evaluate your options and explain the trade-offs for each selection.
Early in this post series, I mentioned that cloud platforms provide a compelling alternative to on-premises systems. I’m bullish on best-of-breed cloud solutions for four reasons:
- Lower up-front cost
- Reduced risk
- Excellent security
- Better tools
Why Cloud (SaaS) Solutions Are Better
The development of the application programming interface (API) has been the fundamental reason cloud-based data and BI software are easier to deploy. APIs are pre-engineered maps of data sources that reduce the time and expense required to extract data from data sources and into your database. Nearly all significant vendors supply APIs for their products. If they don’t, there are open-source communities that build them. APIs make developing your extract and load steps in your ETL process easier to complete.
API cloud solutions are indispensable. They reduce the time needed to harden data workflows. Our practice at InterWorks has evolved to the point that most of our new BI projects are cloud solutions. Why? Because they are much easier to deploy. Cloud platforms attract API development. The consulting hours required to develop solutions are lower, and the security offered by the vendors is better than what you can deploy and maintain on your own. Best practice now means deploying with SaaS tools on vetted cloud platforms like Amazon Web Services, Microsoft Azure or Google Cloud.
Modern analytical data software supports both cloud-based and on-premises data sources. In some situations, you may find a specialized software that is more cost-effective or easier to deploy. You may end up with more than one ELT tool because you might have a data workflow challenge better addressed with an alternative to your primary ELT tool. Cloud platforms facilitate this situational plug-and-play.
This API-driven universe is why best-of-breed solutions are more accessible than ever to deploy and why legacy solutions don’t offer the value they once did. In most cases, integrating data in legacy on-premises systems is more expensive and time-consuming than in the cloud. Modern API-driven systems reduce complexity and save time.
Vendor Selection, Licensing and Data Workflow
Your selection process should balance cost, performance and time to solution. Licensing is never the total price. Consider deployment time, training time, the product’s user community and the fit of the application to your need. You may find more than one tool helps you achieve the best mix of speed, performance and economy. The summary workflow that follows provides a picture of:
- An overview of the BI workflow
- Flow from data sources to data stored through the ELT processes
- Cold storage (data is not cleaned or performance-tuned)
- Hot storage (performance-tuned and cleaned data)
- The consumption layer, dashboards or search, where most people interact with the data
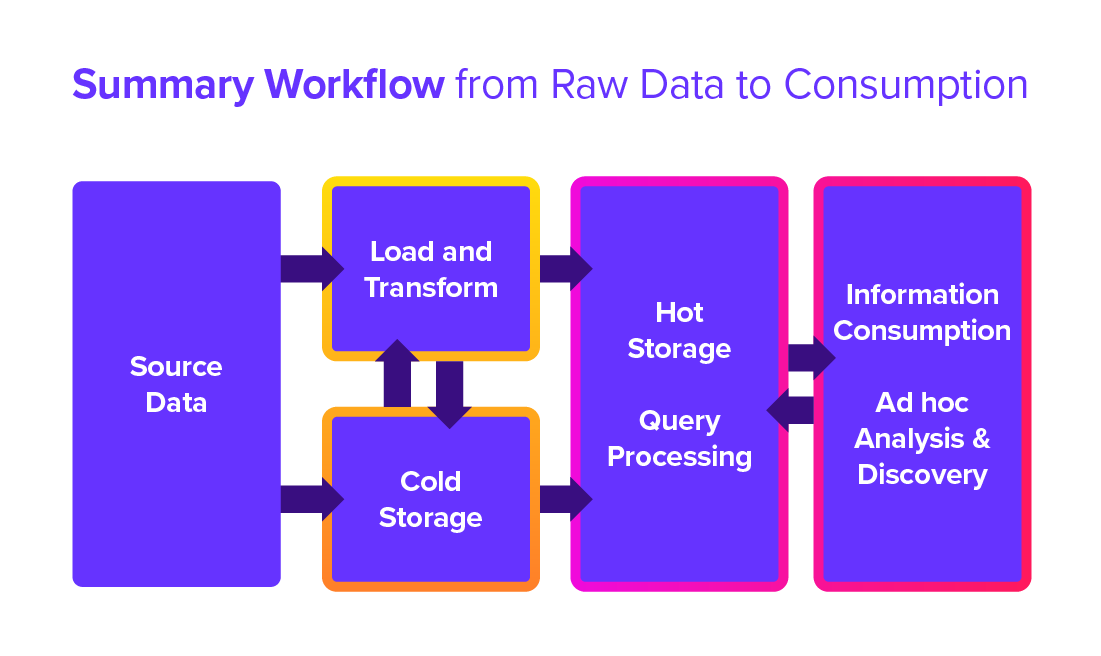
Figure 1.5.1 Data Workflow Summary
- Source Data is extracted and moved to a database. The data may go directly into “Cold Storage” or through “Load and Transform” processes.
- Think of Cold Storage as a holding area in your database for raw data extracted from the source systems and services that create or collect data. Cold storage is unimproved data that may contain errors and omissions.
- Load and Transform denote the data transformation steps required to correct errors, complete missing data, improve formatting and restructure the data to facilitate access and understanding. Query Processing is the activity generated when information consumers use dashboards or search for data. It also includes the processes used to refresh dashboards.
- Data in Hot Storage is for analytical processing. It is optimized to support the type of query loads that your end users require to ensure speed and understandability.
- The Information Consumption environment is where most users interact with the data. They will view the data through dashboards. Suppose your dashboard tool is too expensive to deploy or too complicated for your end users to master. In that case, add a search-based query tool for Ad doc analysis & discovery. At this point, the data becomes actionable information.
The cold and hot data storage database is vital to your data environment. You must stress-test the database to ensure query performance handles your current and future needs. Fortunately, cloud-based databases can scale infinitely. The critical consideration is whether the velocity and variety of your data workloads can be managed with enough flexibility and at a reasonable cost.
There are more than 385 databases available today because the world includes many different workflows that require optimized data processing to improve speed and efficiency. Focus on general-purpose databases that provide the following characteristics:
- Cloud-based
- Cross-platform (Amazon Web Services, Microsoft Azure, Google Cloud Platform)
- High scalability for performance
- Separate computing (query processing) and storage for billing
- Provide metadata for managing cost and performance
All of these are essential considerations for vendor selection. Let’s break each of these down in more detail.
Cloud-Based
Suppose you have one or two team members with good SQL skills and are familiar with legacy databases like Oracle or SQL Server. In that case, that is an excellent place to start — SQL compliance. Cloud-based systems are better for most companies today. Cloud databases have much in common with legacy on-premises solutions (SQL-based or SQL-friendly). Still, cloud-based databases provide better scalability. Dramatically lower up-front cost. More flexible cost containment and improved manageability.
If your database is a cloud service, you preclude the need for a capital budget to buy hardware and reduce the need for dedicated staff to maintain the hardware. It is also unlikely that your team has better talent or knowledge of best practices for maintenance, performance-tuning and security than Amazon, Microsoft or Google.
A cloud-based data warehouse is a better value when compared to a legacy-style, on-premises database. Spin up a database on one of the major public cloud providers in minutes versus days or weeks for an on-premises system. Test different cloud databases with little to no cost during your initial proof-of-concept sprint.
Unless your entire team resides in one building and you come to the same office daily, there is no good reason to avoid moving your data to the cloud.
Cross Platform
Selecting a cloud database that can run on all three leading platforms (Amazon, Microsoft and Google) gives you leverage in price negotiations. You avoid single vendor lock-in. This flexibility also allows you to use different cloud vendors for different parts of your business. For example, a cross-platform cloud database will simplify future data integration if you acquire other companies.
High Scalability
Your data needs will never shrink. You want to provide computing capacity by individual workload because this will allow you to allocate resources and cost most efficiently. Pay close attention to how the cloud database vendor bills for query compute time. Suppose you need more flexibility to provision by individual workload. You may pay more than you should for capacity if your database vendor doesn’t support fine control over query processing (compute) costs.
Missteps like this are akin to buying a legacy on-premises database, where you must spend more money on hardware and software to ensure you can handle future growth.
Storage and Compute layers
The storage layer refers to the space the cloud vendor must provide to store the data you want to keep. The compute layer refers to the processing power you must provision from the cloud vendor to meet your query speed requirements. You must pay for greater capacity if you require faster speeds for many concurrent queries. You buy speed by specifying the number of server cores applied to your workloads.
Separating Storage and Compute
Your cloud database must support separate billing for storage capacity and query compute speed. This billing arrangement provides the most granular control over how you can provision and pay for these services.
Storage costs are trivial. Compute expenses can be very high. You need to understand what triggers them and how to manage those activities. Seek vendors with billing systems that allow you to provision server cores by individual query workloads. Billing by the specific query will save you money, especially if most of your response times do not require the fastest possible response times.
Provide Demand Usage Data
The cloud database should provide metadata on system usage, separating storage, compute volume and cost. Fees should be partitioned to provide clear visibility of their origins. Several cloud database providers can meet some or all these requirements.
Conclusion
If your team is new to cloud-based services, be patient. It will take a few months for them to develop enough knowledge of the cloud systems and your data workflows to build the best mix for balancing cost and performance. While your team is learning how to use your cloud database and how the vendor implements the billing details, the consulting partner you hire will fill in these knowledge gaps. They will know the best practices for getting the required performance at the lowest possible cost.
Next week, Part II will focus on defining and delivering a practical proof-of-concept project.