
This series highlights how Snowflake excels across different data workloads through a new cloud data platform that organizations can trust and rely on as they move into the future.
Data lake is one of the terms in our field that has changed a lot over the years. When I think about data lake as a workload that organizations run, my first thought goes back to the Hadoop days. Hadoop promised that processing true big data in its raw form was possible and optimal for organizations who wanted to unlock insights with all of their data in one place. If you were in the industry to witness the meteoric rise and fall of Hadoop, you know how the rest of that story goes. Hadoop was difficult to maintain, required knowledge of unfamiliar programming languages, expensive to do right and cumbersome to access. With Hadoop being the data lake de facto at the time, many organizations still have a bad taste in their mouth from failed projects that didn’t really provide any value to the business. The challenges that data-lake technology produced led to the data lake being underutilized and an unrealized value of the organization’s data.
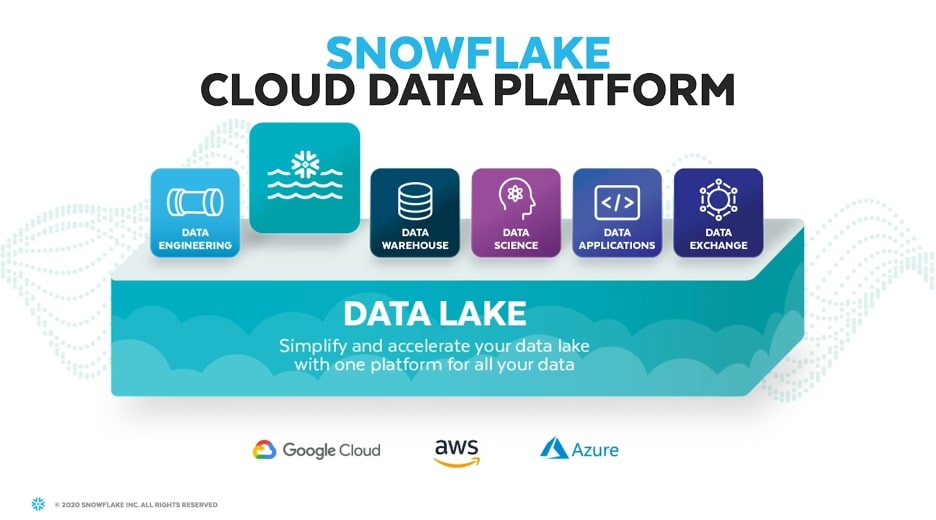
Snowflake the Modern Data Lake
With Snowflakes features and architecture, the data-lake landscape has changed. Snowflake’s data platform offers a true cloud solution that allows all of an organization’s data activity to live under a single source of truth. Snowflake approaches the historic problems associated with the data lake by bringing together the best components of the data warehouse and the data lake. Providing users with a single source of truth that can handle semi-structured and structured data allows organizations to be flexible and store all their data in one place. Using Snowflake’s virtual warehouses for compute allows organizations to unlock fast insights from their data lake, providing businesses the opportunity to fully realize the value of their data.
Unlike Hadoop, Snowflake was built with a few architectural concepts in mind that align perfectly with the goals of the data lake. Snowflake is a platform that was built from the ground up to take advantage of the cheap storage available in the cloud, provide the on-demand compute power necessary to power big data and offer the ability to store semi-structured and structured data in one place. The data lake existed to aggregate and store all the data an organization generates—Snowflake’s unique architecture fits that requirement perfectly, all behind a SQL interface that’s familiar to engineers and database administrators.
Built for the Cloud
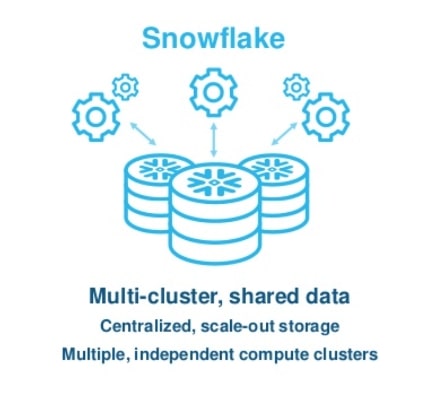
When looking at Snowflake for data-lake workloads, it’s important to remember the reason that Snowflake can perform better in this situation. At its core, Snowflake utilizes a multi-clustered, shared-data architecture. This architecture allows Snowflake to scale compute on demand, while democratizing access to shared datasets across the organization. When you think about the data lake, this is useful for two reasons:
- Entire organizations can query a data lake in pure SQL with different Snowflake compute clusters.
- Compute clusters are not dependent on data being stored in Snowflake; Snowflake can augment existing cloud data lakes purely as a query engine.
Snowflake unlocks deployment patterns that complement the data-lake paradigm in a way that is efficient, performant and friendly to analytics.
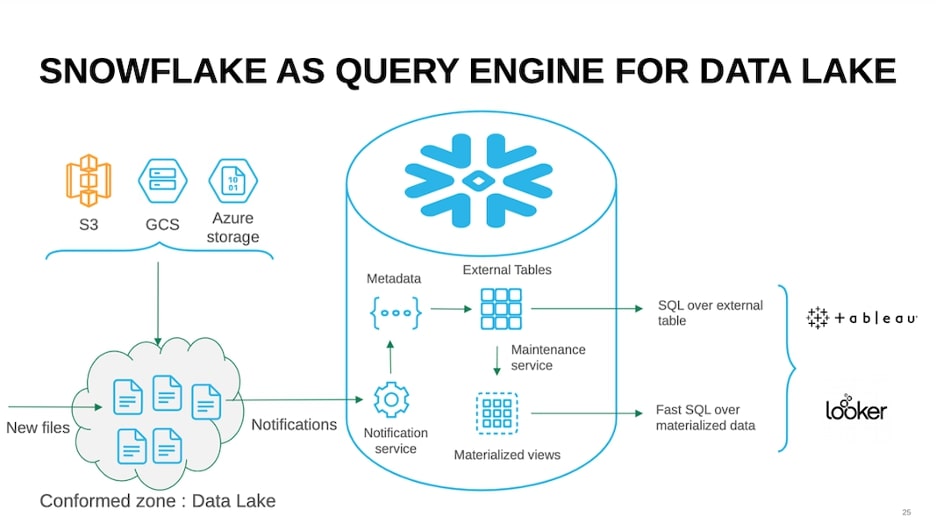
The Next Frontier
Looking at Snowflake’s history as a data warehouse and the features that come along with it, it is easy to see what makes Snowflake best in class. A winning formula comprised of unmatched performance, cloud-focused architecture, ease of use and intuitive pricing have all set the stage for where Snowflake can go next. Snowflake’s guiding principles position it to be the best-in-class data-lake solution for organizations looking to harness the power of the cloud. The power of Snowflake’s architecture isn’t unique to the data warehouse; it really is the catalyst to creating a data platform that organizations can rely on and move into the future with.
I hope that you’ve enjoyed this blog and you find some insights from our perspective on how Snowflake enables the modern data lake. Please feel free to message me or reach out if you have any questions. I would love to continue the conversation. If you haven’t had the chance yet, go check out the other posts in this series that dive into the other aspects of the data platform: data exchange, data science and integrated data engineering. Come back next week as we dig into data applications in the next post!