
This series highlights how Snowflake excels across different data workloads through a new cloud data platform that organizations can trust and rely on as they move into the future.
When you think of data science (for the purposes of this blog, this will encompass all machine learning and AI activities), you may think of specific aspects. I would make a wager that most people think specifically about model building.
The Data Science Process
Data science is more than just building an accurate model. More than anything, data science is a process that involves several discrete, iterative steps:
- Exploratory data analysis (visualizations)
- Pre-processing such as creating dummy variables, centering and scaling, imputation, etc.
- Model training and tuning
- Model promotion, monitoring and updating
- Enabling access to the model
These high-level activities do not capture all the tedious tasks involved with developing and deploying models, but they provide a guidepost for the things you should consider when choosing a stack to support analytics at your organization.
Data Science with Snowflake
Data science is one of the six pillars of analytics enabled by Snowflake’s cloud data platform. So it may surprise you to find out that Snowflake doesn’t offer any specific model-building capabilities, but it doesn’t need to. There are plenty of well-designed open source and proprietary tools proven to do that job well. Snowflake’s job as a data platform is to make the data science process easier.
If you’re an analytics professional, you’ve probably spent time working around the roadblocks to the data science process presented by other data warehouses.
Pre-processing tasks like feature engineering are best done in-database. In a traditional data warehouse, this means you are competing against other queries for existing, static compute resources. You could try bringing the data in-memory if your warehouse makes it easy to collect, but then you are at the mercy of the hardware on your local desktop. With Snowflake, your data science team will have access to independent compute clusters that scale up and down near-instantaneously, so pre-processing can always be done in-database without the hassle and I/O bottleneck of local data.
When it comes time to train models, you will likely want to utilize Spark to run the algorithms on the full dataset in-memory to avoid complicated samples. Managing data movement to Spark can be a frustrating task for a data scientist who will likely have a mathematical background, not necessarily computer science. Snowflake comes with a native Spark connector that easily moves data into Spark from Snowflake.
Models are generally built using raw data so as not to introduce errors into the final product. Traditionally, data warehouses do not contain the data from your applications, databases and streaming sources in a raw form because storage is limited. With Snowflake, we recommend designing your data platform using the ELT paradigm as both a data lake and an enterprise data warehouse because Snowflake utilizes cheap, scalable, secure cloud storage. This way, your analysts can access the data they need in the format they desire without needing to leave the Snowflake platform.
Finally, every data scientist wants their data to be used. With built-in connectors and data sharing, it is easy to get the results of your analysis back into Snowflake and in the hands of users.
The InterWorks Cloud Analytics Stack
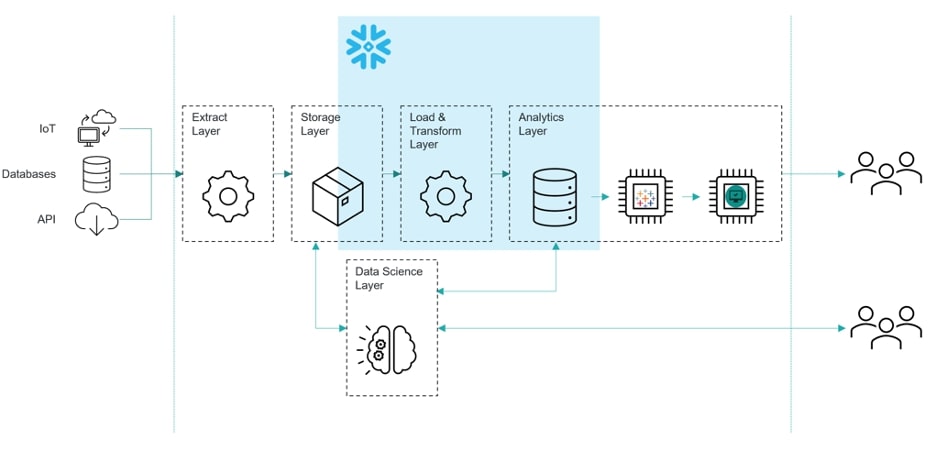
InterWorks recommends a loosely coupled stack with best-in-class technologies that have a narrow scope. Snowflake is the best cloud data platform, and it allows you to choose an analytics tool that will plug right into your data. With out-of-the-box connectors built and maintained by Snowflake, you can easily use open-source technologies like pandas and Jupyter Notebooks for Python or dplyr and RStudio for R.
If you want a fully supported platform that was built from the ground up to support all aspects of the data science process, we highly recommend Dataiku.
The Power of a Platform as a Service
A cloud data platform as a service provides scalability and integration to bring together all the back-of-house data operations onto a common platform to provide a consistent analytic experience. With the six pillars, Snowflake aligns database admins, devops engineers, developers and data scientists. App builders and data scientists immediately took to cloud-based architecture because it provided them the flexibility and infrastructure as code they required, and now Snowflake has packaged that into an enterprise product that can be managed easily.
The power of Snowflake’s architecture isn’t unique to the data warehouse. With the Snowflake data platform, data scientists are able to use the platform of their choice to do the job they were hired to do instead of fighting against the constraints of legacy architecture.