
This series highlights how Snowflake excels across different data workloads through a new cloud data platform that organizations can trust and rely on as they move into the future.
Snowflake has long been the Cloud Data Warehouse. The organization has completely changed the game with unique architecture purpose-built for the cloud: allowing scalable storage and compute for data warehousing projects, all within a SQL-compliant database. The benefits of Snowflake’s modern architecture were obvious, and over the past few years, we have been hands-on in the tool as it matured and improved. As Snowflake continued to expand the capabilities of their product, the cloud data warehouse matured quickly, checking all the boxes that an enterprise could need to migrate the existing enterprise data warehouse into the cloud:
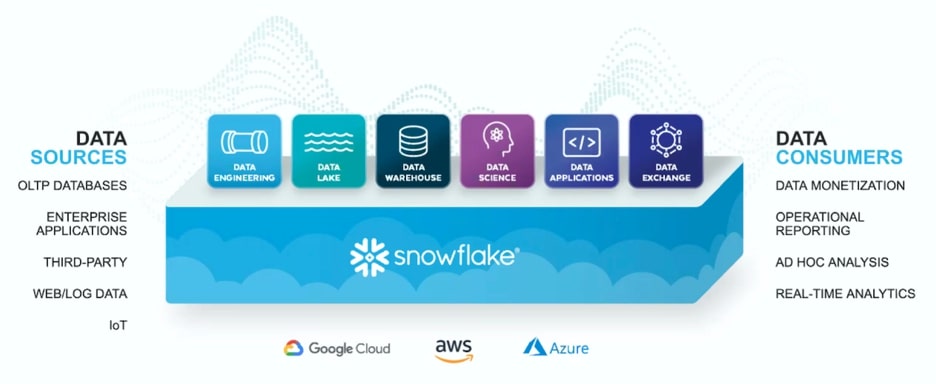
As Snowflake matured as a cloud data warehouse, another opportunity quickly became feasible—our clients weren’t looking to hide their EDW behind the reporting organization any longer. In addition to reporting the business, this data could be used to extend other applications; in some circumstances, it could even be monetized. As the doors began to open for different workloads, it became quickly apparent that Snowflake enabled so much more than just data warehousing, and similar to other major cloud providers, they realized they weren’t just selling storage and compute for data. Instead of Snowflake only providing storage and compute, those two components were the building blocks of a platform capable of solving the world’s data problems—Snowflake, the Cloud Data Platform.
The Cloud Data Platform expands Snowflake’s capabilities to enable data lake, data exchange, data applications, data science and integrated data engineering for organizations of all shapes and sizes. In considering this shift and the expanded scope, it’s important to think back to the core product that enabled this growth: the cloud data warehouse.
Snowflake as a Cloud Data Warehouse
That title is something that will feel the most familiar in this blog series, and it’s essential to remember why those words now come so naturally to us. We know and love Snowflake as a data warehouse, but why is that? The easy way to answer that question is to look back at the clients we have seen grow and optimize their businesses with the platform, and it really comes down to a few key concepts that make Snowflake a cut above the rest:
- Familiarity that comes along with Snowflake’s SQL engine
- Lack of maintenance and management for software or hardware
- Performance and speed that Snowflake enables on massive datasets, without writing indexes
- Pay for only what you use
SQL Data Warehouse
Snowflake is easy for organizations to adopt because they already have the skills to use it. When Snowflake entered the market, organizations were still fiddling around with Hadoop. Hadoop promised the ability to process data at massive scale, and it did deliver just that to organizations who were able to staff and manage it properly. The problems with Hadoop were that it took a team of PhD’s to keep the system up and running, it was wildly complex, and it was also wildly expensive. For smaller players who were wanting to unlock access to their data, a majority of Hadoop projects failed miserably.
When Snowflake entered the scene, also promising the ability to process massive amounts of data but all within a SQL database, the results were different. At its core, Snowflake has been something familiar from day one, and it has been something that organizations big and small can maintain and benefit from because of its SQL interface. Snowflake has allowed organizations to deliver real business value, in large part because of how easy it is to get a data warehouse project up and running. Plus, customers in most circumstances already have the skills.
Built for the Cloud
Another area in which we have grown accustomed to Snowflake’s approach to data warehousing is their cloud-first architecture. Snowflake was the very first data warehouse built with the benefits of the cloud in mind from the outset. Snowflake’s most notable tenet of their architecture is the separation of storage and compute: a multi-cluster, shared data approach. This strategy allows infinite scalability for data storage and compute resources to transform, report and load that data. This separation means organizations can run ETL and reports at the same time without competing for resources. A cloud-enabled scale-out of any workload across an organization is in Snowflake’s DNA:
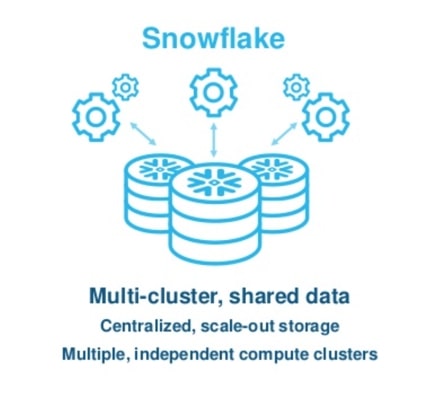
When thinking about Snowflake’s cloud architecture, I would be remiss not to mention the cloud-agnostic aspect of Snowflake. Customers being able to seamlessly deploy onto AWS, Azure or GCP and receive the same end-user experience is a concept that will completely change the way cloud software solutions are created from here on out. Customers now have more options than ever which regions to deploy in, and they can distribute their warehouse workloads all over the world. At the same time, these complex workloads are serviced with a platform that is transparent to the user. A Snowflake user never has to run software updates or provision hardware. From day one, I have described it as a platform where you literally just run your queries and it works.
Unmatched Performance
Snowflake has always stood out as an extremely fast analytic database. In the world of analytics, performance is the one thing that cannot be sacrificed. Whether it’s Tableau or any other data analytics solution, if you’re running queries live to the database, it is unacceptable to have a query take any longer than 15 seconds (in my opinion). Snowflake has been delivering unmatched performance over the years thanks to a few key features. The query engine and storage method that Snowflake uses automatically partitions and stores data in relevant chunks alongside some metadata about what each chunk contains. This allows the query engine to quickly scan terabytes of data and select exactly what it needs in seconds instead of minutes, resulting in extremely fast performance without the need to manually write indexes or partition tables.
Snowflake’s virtual warehouses act as a compute engine that allows for on-demand scaling upward and outward to handle those larger queries and high concurrency workloads. When memory becomes an issue and your queries are taking longer than expected, you can resize your virtual warehouse to accommodate them at the click of a button. Once the query is complete, you can size it right back to where it was and continue on as usual. With this upward scalability, you can always have the right tools for the job, and you’ll never have to worry about large datasets slowing down your query. Snowflake was built with large datasets in mind.
On the other end of the spectrum, for high-concurrency workloads, we can also allow these virtual warehouses to spin out and create additional nodes. If you have a dashboard with dozens (or hundreds) of users being serviced by a virtual warehouse, you can provision that warehouse to add additional resources to service the high volume of queries and ensure our users don’t get stuck in a queue. Snowflake was built with heavy organizational usage in mind.
A slew of other features exists in Snowflake that all contribute to this goal – an extremely performant data warehouse that is fast in real life, not just in your benchmarking tests or tech demos.
Intuitive Pricing
Snowflake has always been the most intuitively priced data warehouse product on the market. I’m sure a majority of the readers here can remember the old school pricing model of a data warehouse project. The line items quickly added up. Between hardware, licensing and setup costs, a project could easily exceed six figures. Not only were they expensive, but the pricing models were also confusing … and that statement applies even to other cloud data warehouses.
Snowflake simplified this equation down to two costs. You pay for each credit of compute your virtual warehouses use, and you pay for each compressed terabyte of data you store. These two things couldn’t be simpler to unpack. You run a query? You are going to use credits. You load data into a table? That data is now in your Snowflake account and will be a part of your storage bill. Aside from how basic the actual costs are, they took it a step further by making compute credits easy to right-size. With features like query caching and warehouse auto-suspend, we’ve seen a theme where customers constantly get more for less from their Snowflake investment, and they only ever pay for what they use.
The Next Frontier
Looking at Snowflake’s history as a data warehouse and the features that come along with it, it is easy to see what makes Snowflake best in class. A winning formula comprised of unmatched performance, cloud-focused architecture, ease of use, and intuitive pricing have all set the stage for where Snowflake can go next. Snowflake has won the cloud data warehouse battle—for years now, competitors have been chasing features that Snowflake launched with, and they can’t catch up. These themes that set Snowflake apart as a data warehouse will, without a doubt, be the pillars upon which they expand the data platform to new areas. The power of Snowflake’s architecture isn’t unique to the data warehouse; it really is the catalyst to creating a data platform that organizations can rely on and move into the future with.
I hope you’ve enjoyed this blog and can find some insights from our perspective on why Snowflake plans to expand into other areas of the data landscape. Please feel free to message me, or reach out if you have any questions. I would love to continue the conversation!
Keep an eye out for the upcoming posts in this series that will dive into the other aspects of the data platform: data lake, data exchange, data applications, data science, and integrated data engineering.