
This blog post is Human-Centered Content: Written by humans for humans.
The use of the AI tools is no longer a novelty in data analysis. In fact, every data platform and BI tool vendor is trying hard to bring more and more AI functionality in their products. On the other end of the spectrum are the general-purpose AI applications themselves — Microsoft Copilot, OpenAI ChatGPT, Anthropic Claude or Google Gemini — all are trying to lure people by promising capabilities to analyze data with a minimal toolchain. But then why aren’t the users only using the new AI apps to perform all the data analysis they want to? Where is that promise of the universal AI data analysis application falling short? And are there tools available to realize this utopian vision?
A simple answer to the above questions is that data analysts could theoretically use only the general AI tools to perform the analysis they are after, but there are two big hurdles: Access to the data systems and trust in the answers that AI would return. Anthropic has, in fact, published a lengthy article on how they perform data analysis using Claude and the reader would agree that there are a few steps and processes involved before Claude can really analyze the data, reliably.
Truth is, like Anthropic says, it is possible to perform the data analysis with AI-first tools like AI agents, provided we understand some of the nuances in how we expect to analyze the data.
Levels of Insights
Not every question requires the same kind of effort to answer. Traditionally, a centralized data platform and the BI and analytics apps connected to the platform serve a large segment of data consumers with the insights that they require. But developing standardized analytics has a lot of steps involved. Not only data engineering and data modeling, but also the domain expertise to verify the data and validate the KPIs are necessary before the analytics product can be published to its audience. The rigor involved in this process is necessary to make the data pipelines fault tolerant, and the analysis trustworthy.
But sometimes this rigor itself becomes the hindrance when insights are required quickly or needed on the data that is not catered by the data platform. The value of an individual quick insight could be minuscule compared to the (development) cost and effort involved to bring these insights to its users. And yet the cumulative value of multiple instances of such insights that were not implemented, could translate to significant lost opportunities at the organizational level.
The level of the analytical insights can be classified in the following manner.
- Quick insights: Factual questions that can be answered without any data modeling, or derived questions based on an already available analytics product. Usually, only a person or group of people are interested in it. Quick insights have temporal significance and may lose their value if the insight is not available this very moment. For example, a question about the total number of customers in the CRM system.
- Compound insights: Questions that can be answered by referring to or combining data from more than one data source. Such insights still do not require complicated data modeling, and analysts or business users can quickly build/create them in their tool of choice. Again, relevant only to a person or group of people who were interested in it. The temporal value of the compound insights could vary. Sometimes, they might only be relevant for a short amount of time, or someone might create them in effort to answer repetitive questions. For example, total business leads that were generated through a specific marketing channel. Note that the data about marketing channel attribution and information about the leads could be coming from two different data sources.
- Conformed insights: The insights that require significant data modeling efforts and must be validated before distribution. Organizational KPIs are good examples of conformed insights. Such KPIs might be used in strategic decision making across departments and levels and therefore the data required for these KPIs and the method and logic to calculate the KPIs themselves must be rigorously validated. Conformed insights are generally distributed and pertinent to large audience. They are hard to change without significant deliberation and remain relevant over a long period of time.
Only the conformed insights have been focal point of the organizational data strategy in pre-AI era. A data platform that acts as a single, centralized source of truth has been required to perform the necessary data engineering (to obtain the data from the data sources, to curate and maintain it) and data modeling is valuable but a high maintenance resource and may or may not cater to the compound and quick insights. Many efforts towards “self-service analytics” based on such a central data platform are only partially successful due to various factors, principal of them being the availability of data outside of the data platform and lack of governed and modeled data, when the data is available.
Opportunities and Gaps with AI Tools
AI tools can help fill these gaps in analytics, especially for quick and compound insights. Modern LLMs and AI agents/chatbots built on these LLMs can answer even complex questions based on the data, if the data is made available to them. This eliminates the need for data cleansing or modeling and is independent of the skillset of the user. This could be the biggest advantage of using AI agents or chatbots that have access to the data. AI tools can also combine the insights gained from the data with other information like business processes to provide strategic insights that otherwise cannot be gained only through data.
By catering to quick and compound insights, AI tools can also help accelerate development of conformed insights. In fact, the development cycle can be fully pivoted to start from AI assisted quick and compound insights that can help build new or maintain/improve existing conformed insights. For example, total sales in the last quarter or best-selling product in the last quarter are simple or compound insights as they only require pulling data from specific data objects. But revenue growth YoY is an example of a conformed insight as the business must decide what the definition of “revenue” is, where does a financial year starts and ends, what all products and services to include in the calculation etc.
The trust factor that the conformed insights provide cannot be overlooked. AI assisted insights may not always be able to provide the level of trust that manually validated data and insights provide1. AI agents can also be wasteful. For repetitive insights coming from different users, AI agents might be rebuilding the same context and redoing the same calculations thereby leading to token overuse. Therefore, the data and analytics teams must pay attention to the data usage and should be proactive in converting repetitive insights into models.
Data governance and security aspects do not diminish while making the data available to the AI tools for gaining insights. Different users have different access to the data and while building AI assisted data strategy, it must be made sure that the level of data access is not overridden.
One more crucial thing to understand. Whether the data is rigorously modeled or made available to an AI tool, it does not eliminate the need to extract it from the data source first. The only respite with the AI data tools is that this data may not have to be loaded in the data platform or modeled immediately before using it. Data engineering therefore can be minimized but cannot be fully eliminated even with the use of AI data tools.
AI First Data Strategy
To leverage the power of the AI agents and to accelerate the insights gained from the existing data, the following things should be achieved.
- Data should be made available first to the AI tools and then to the traditional BI and analytics tools with minimal data engineering and modeling efforts.
- The process should be pivoted to give precedence to the AI tools to allow them to perform primary and spot data analysis.
AI first data strategy does not mean less importance to the central data warehouse. As explained before, the value of the robust data pipelines and conformed insights is irreplaceable. The AI assisted data strategy only provides the necessary buffer and acceleration in the analytics development to bridge the gaps in the analytics.
It’s natural to raise questions over the reliability, trustworthiness and unambiguity of calculated insights, especially that of quick and compound insights. Just because an AI tool has assumed access to a data source doesn’t mean that it could provide the same answer to the same question or it wouldn’t confuse or misunderstand about the context of a question. For example, answer to a seemingly trivial question like, “How many orders were shipped in last month?” could be difficult to provide if we dive deeper:
- <Orders> — Does this mean explicit sales orders? Does it include subscriptions where there isn’t an explicit order? Does it include intracompany transfers? Does it include free gifts?
- <Shipped> — Does this include orders that were part shipped? Does it include orders that were shipped then returned?
- <in last month> — Does this mean in the whole of the prior month? The prior financial period? In the last 30 days? Since the same day of the month, last month?
- <by who?> — From this depot? By the entire company worldwide?
Devil is always in the details and as the above example proves, it could soon lead to ambiguity and untrustworthy answers, if there is no additional context. But simply because AI tools are directly connected to the data sources, and no significant data engineering is being performed, doesn’t mean that the context doesn’t need to be provided. Thankfully, all current AI tools provide some concept like “workspace” or “project” where additional context or prior information can be provided, and ambiguity can be reduced or removed. Google recently released Open Knowledge Format, which could become instrumental in creating and providing initial context for the analysis.
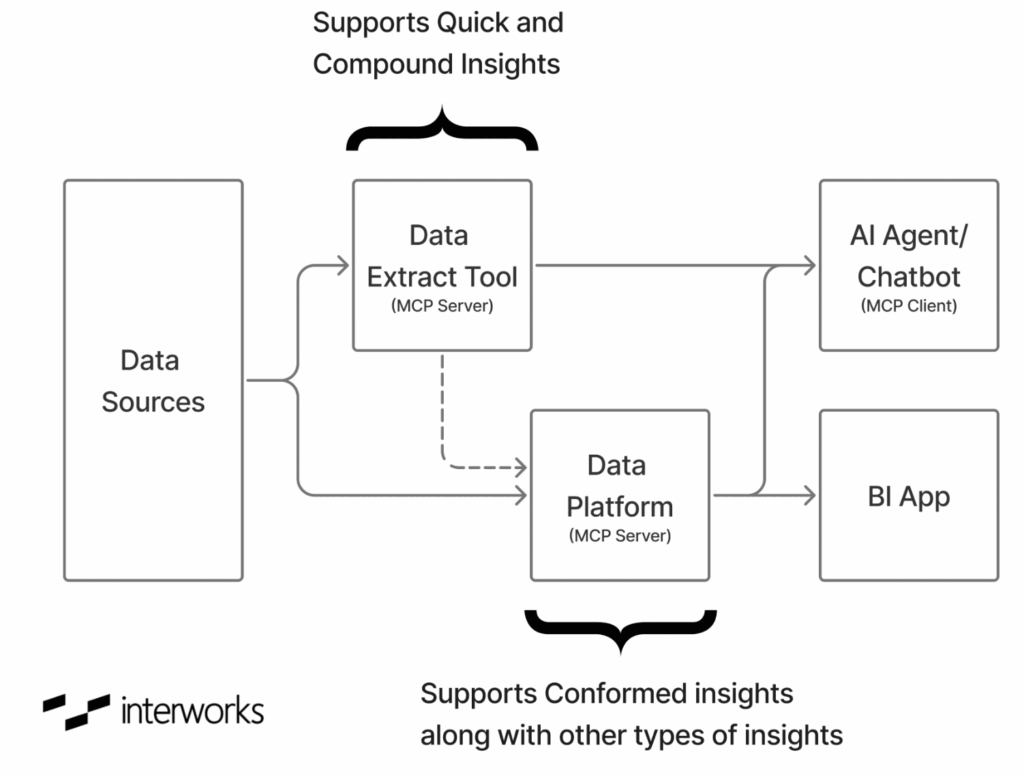
Now, data availability to the AI apps remains a crucial problem. Anthropic tried to solve the connectivity problem for the AI tools by introducing and open sourcing the Model Context Protocol (MCP). Although some major operational data systems have started supporting MCP (example: Salesforce), not every system supports it yet. But the data products vendors are coming forward. Data integration software vendors like CData, Peliqan or Skyvia have launched or added MCP interfaces on top of their existing products. These vendors had already solved data extraction, so making this data available to the AI agents and chatbots was only the next logical step.
CData Connect AI
CData Connect AI is a noteworthy tool in this space. CData is a long-standing player in the data integration software space. With their virtual SQL connectivity, they have enabled some big names in data tools space. With their Connect AI platform, they have demonstrated vision in the data integration space powering the AI apps.
Connect AI is a data virtualization tool with more than 350 data connectors including the generic data connectors for CSV/JSON files, and for HTTP and REST APIs, that has been redesigned with a solid focus on making data available to the AI agents/chatbots. Not only does it provide direct integrations through MCP to all leading AI agent/chatbots today (ChatGPT, Claude, Microsoft Copilot Studio and Google Gemini), but also to BI and reporting tools, ETL/ELT tools as well as data platforms and dev tools (JDBS, ODBC drivers and Python, Node.js libraries for example).
What makes it powerful is that it allows the data engineers to organize data in workspaces and derived views and can even project the data as if it’s on a virtual SQL Server, so that data from multiple sources could look like coming from a homogenous data asset organized as familiar database-schema-tables/view structure. When an AI tool will use the MCP server to find out about the available data sources, it can see both the direct as well as derived data sources and can easily query them.
Behind the scenes, Connect AI will federate the queries to the underlying data sources, get the results, combine them and present them to the querying client tool. User governance is also deeply embedded in the tool. Administrators can decide different access and authentication models for the underlying data sources. For some data sources, it could be generic service principals, but for other data sources that support it, it could be pass-through individual user authentication, only allowing the users to access the data they are permitted to access. SSO and SCIM features can make the authentication and access experience even more seamless.
Such a powerful data integration tool can help designing an AI first data analysis approach.
A Sample Data Platform
What would a hybrid data platform that uses the AI first data analysis principle explained above look like?
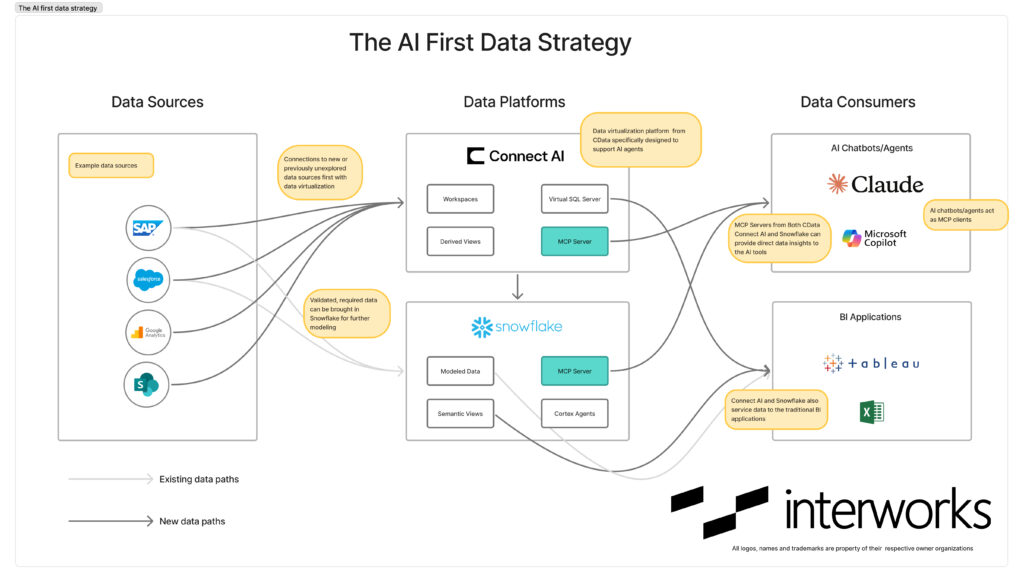
An example data platform using CData Connect AI for data virtualization as well as Snowflake as a data warehouse could use the cascaded analytics development approach with the following ruleset:
- All new data sources should first be connected to CData Connect AI and should be made available to the preferred AI agent. CData Connect AI acts as MCP server and any compatible MCP AI client/chatbot can be used.
- All permitted users should be onboarded onto CData Connect AI platform, preferably using SSO to take advantage of the per-user authentication and user specific data serving wherever possible.
- Workspace feature in CData Connect AI should be used to organize data sources and data assets according to use cases, departments or functions.
- It might also be a good idea to create shared projects or workspaces in the AI tool so that additional context about the insights can be provided and the knowledge-base of the business concepts would be common for everyone.
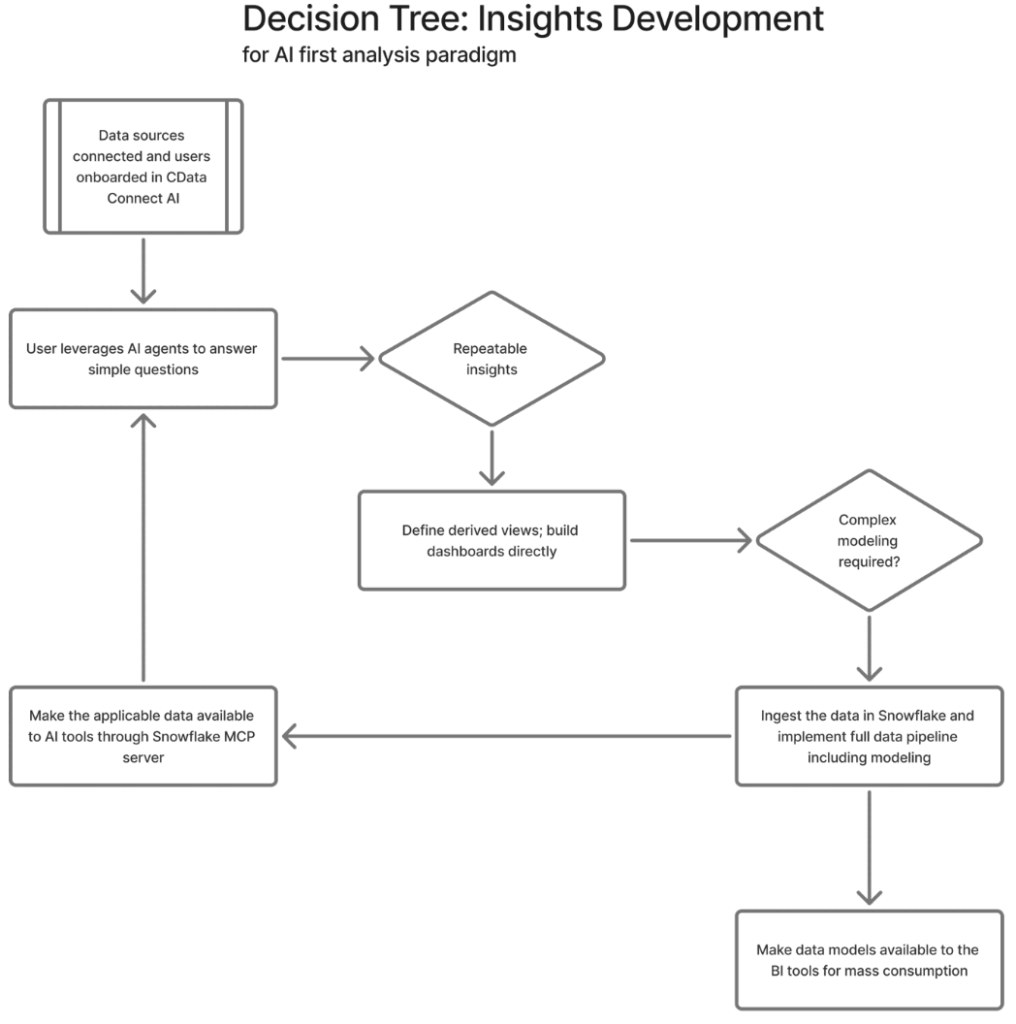
- For repetitive query/prompt patterns, derived views should be defined that predefine the query. Jobs should be created to pre-cache the regularly queried data.
- The workspaces and the derived views could also be made available to the BI tools to allow building analytics assets directly on top of the live data.
- Whenever a need is identified for a concrete data pipeline and conformed insights, the data can be ingested in Snowflake to perform formal data modeling.
- Snowflake also provides features of semantic views and Snowflake’s own MCP server serving those semantic views. The preferred AI agent should also be connected to the Snowflake’s MCP server2 to provide insights on validated and conformed data. Snowflake MCP server also supports (rather only supports) OAuth authentication per user.
This design inverts the data engineering process and allows to put in more efforts into the development of conformed insights, while making the wider data available to anyone who wants to (and of course, is permitted to) access and analyze it. The power of AI agents/chatbots can facilitate quick and compound insights and the traditional BI tools as well as AI agents/chatbots remain available for accessing and analyzing conformed insights.
Note: Although per-user authentication is available in both CData Connect AI and Snowflake and is highly recommended to use it, it is not necessary to use it. If the blanket data access is acceptable, only a single user is required to be created for the data access in CData Connect AI. Similarly, a single service principal could be created in Snowflake that represents access for all users. However, password-less access in Snowflake is tricky due to OAuth 2.0 standard.
Also note: A similar data platform can also be built using Databricks. CData Connect AI can make the data available to both Snowflake and Databricks, although through different means. Databricks support is available as a direct integration, whereas Snowflake must rely on the Connect AI Python library to fetch the data, if no ETL tool is to be used.
A couple of things to keep in mind: The quality of the insights depends upon the quality of the data in the data source, and no AI can elevate the quality of the data. Data sanity is an irreplaceable principle. Secondly, it cannot be stressed enough that AI first data analysis doesn’t mean end of data engineering or modeling. Wherever the rigor of validation and conformance is necessary, it cannot and shouldn’t be avoided.
InterWorks partners with leading data platform vendors like Snowflake and Databricks and with visionary data integration tool vendors like CData so that we can provide you the best possible version of your data platform. Talk to us if you want to bring your AI first analysis vision into reality.