
In today’s tech landscape, the rapid increase of data and the migration of systems to the cloud has significantly diversified the range of data loading and processing tools available. For a data engineer, it’s like being in a room full of different instruments, each with its own sound. They need to find a way to make them all work together to create a harmonious tune.
Constantly switching between tools can be time-consuming and expensive, especially when the number of tools increases with the business growth. This job gets harder and different teams might get good at using different tools, which creates divisions or “silos” within the company.
This is where Matillion comes into play. Matillion is designed to be easy to learn, yet it offers a broad range of capabilities. This means it can significantly cut down on the number of other tools a data engineer needs to utilize to meet business needs. The advantage of Matillion is that instead of needing to master multiple tools, a data engineer can focus on one tool. This can save time, reduce costs and make the entire data management process more efficient.
How Can Matillion Increase Productivity in the Cloud?
Matillion has just launched the Data Productivity Cloud, which is a cloud-based product delivered as a service with no need to manage any virtual machines or staging space and it is available purely through a web browser. Data Productivity Cloud provides capabilities of both data loading and data transformation in one place. This powerful platform accommodates unlimited users, projects and environments and offers unlimited scalability powered by Matillion-managed or user-managed agents.
Data Productivity Cloud offers intuitive access control capability. You can grant permissions to projects by assigning users to one of three distinct roles: read-only, user or admin. This flexibility encourages effective collaboration, allowing team members to share resources and work together efficiently via Git, which is a significant feature enabling efficient version control and collaborative teamwork.
In a transformative move away from traditional VPN-based access, Data Productivity Cloud simplifies your operations. It provides robust security measures, including the option to configure Multi-Factor Authentication, thereby strengthening the protection of your valuable data.
All that comes with a granular consumption plan, crafted with a value-based approach, ensuring optimal utilization.
What Does the Data Productivity Cloud Look Like?
We at InterWorks were privileged to be among the first data enthusiasts to preview and collaborate with Matillion for some final fine-tuning for Data Productivity Cloud. It left a lasting impression on us, not only due to its intuitive interface and resemblance to METL but, more importantly, because of its enhanced capabilities.
Let’s first take a look at what it looks like:
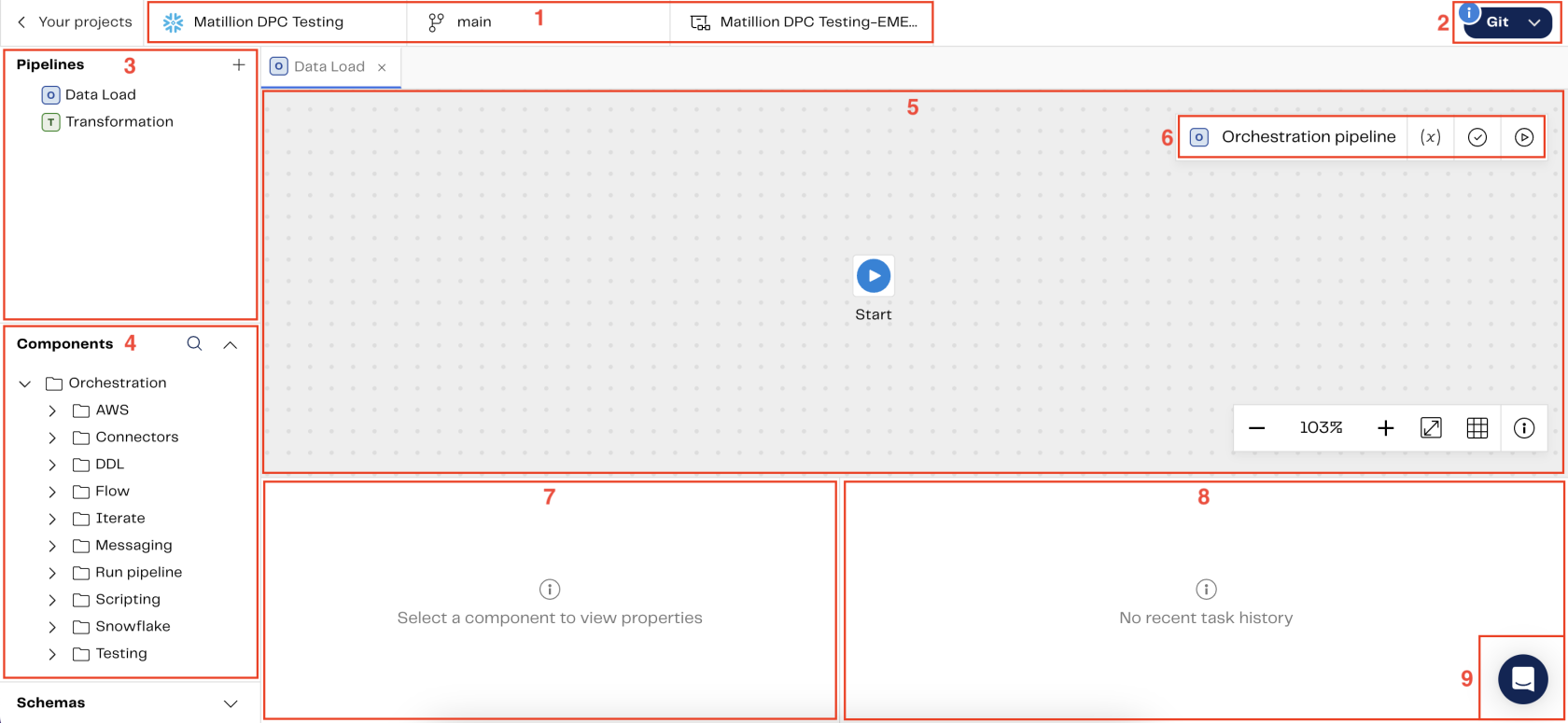
The majority of Data Productivity Cloud features can be accessed using the following system features:
Our Impressions with Data Productivity Cloud
Data Productivity Cloud can load data from multiple sources and perform data transformations all in one single place. We’re excited to share some insights from our testing phase and offer you a peek into some of its capabilities.
In our test run, we opted for the infrastructure entirely managed by Matillion. Remarkably, we didn’t need to provide computing power or allocate any extra staging space. Instead, we utilized Snowflake storage integrations and Snowflake-managed staging offered by Data Productivity Cloud, which greatly eased our overhead and simplified the process. Our trial involved three data sources within a single orchestration pipeline and a single transformation pipeline. The process was as straightforward as it sounds!
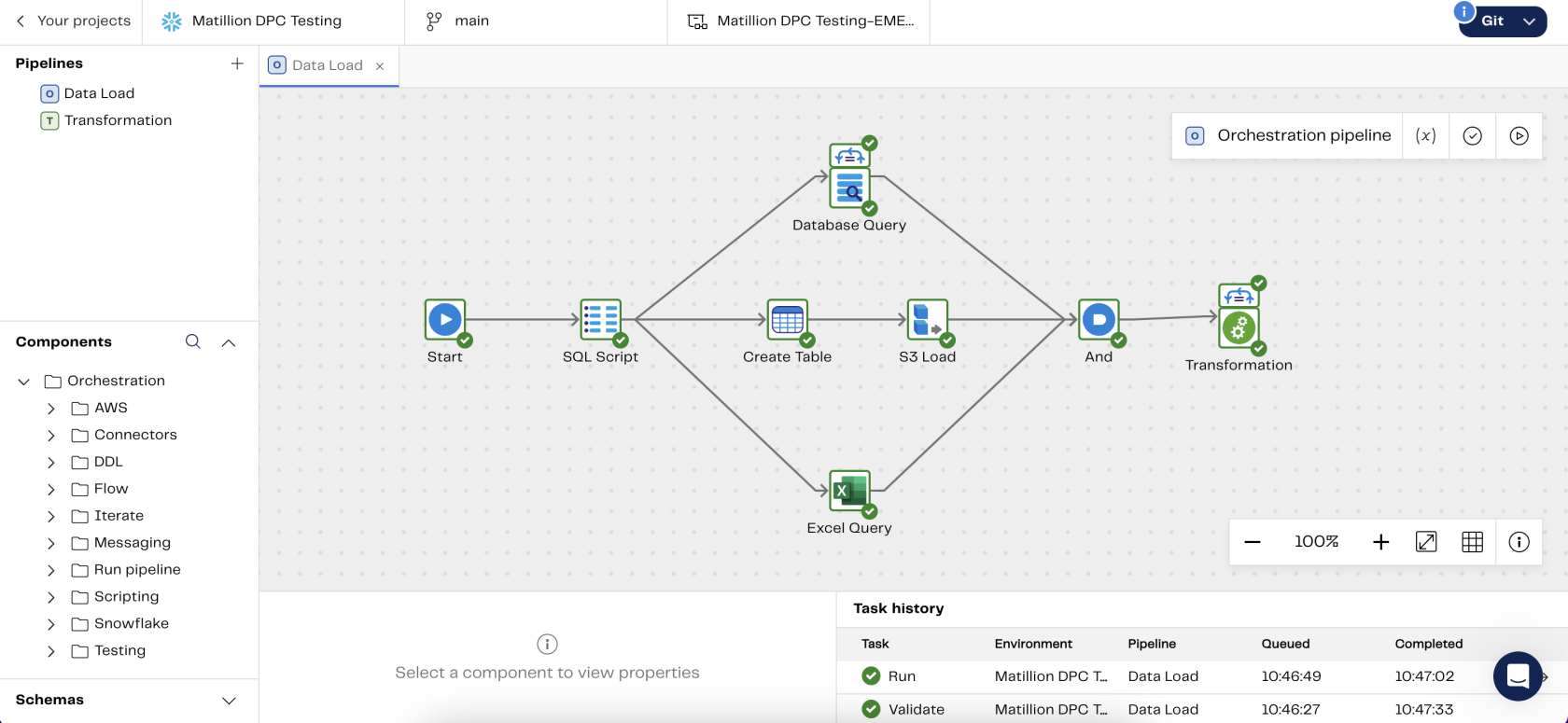
The subsequent image will demonstrate our data load orchestration pipeline:
- Database Query: This component is using an iterator to extract tables from a PostgreSQL database and stage them into a Snowflake Internal Stage before loading them into Snowflake tables. The use of an Internal Stage is an advantageous feature of the Data Productivity Cloud, simplifying the process of pipeline development and eliminating any barriers to the immediate start of development.
- S3 Load: We utilized this component to retrieve data from an S3 bucket and write it into a previously created Snowflake table. The authentication to the S3 bucket is happening through a Snowflake Storage Integration.
- Excel Query: We also employed an Excel query component to extract data from an Excel file residing in an S3 bucket. This component stages the data also in a Snowflake Internal Stage.
For the purposes of this demonstration, we are employing a set of straightforward transformations which consist of the following components: Table Input, Join, Distinct, Rename, Filter and Write Table.
The best part? In addition to handling all these data loads concurrently, this platform truly offers a remarkable user experience.
Wrap Up
Our simple yet not-so-hello-world test shows the Data Productivity Cloud’s ease in managing multiple data sources and performing transformations right from a single pipeline through a web browser. With unlimited scalability, a pipeline can handle even the most complex business requirements.
With Data Productivity Cloud, you can streamline and combine your processes, have a ready-to-use scalable infrastructure and bolster team collaboration.
Need help starting building your pipelines? Reach out and let’s talk data.