
In the modern analytics stack, data is constantly on the move. While all data originates somewhere, it typically must go somewhere else before it becomes valuable for the data analysts/engineers/scientists. However, when working with pipelines that deal with large amounts of data, it is important to construct them to work as efficiently as possible.
A well-designed pipeline can be the difference between having your data ready and available in an hour vs. a minute. Luckily, one of Dataiku’s best features is the built-in ability to orchestrate and optimize your data pipelines. How, you may ask? Here, we’ll be exploring a couple of methods to do exactly that.
Getting Started
To start, it’s important to make sure that you are using the best computation engine for the job. Remember: the computation engine is a feature of a recipe as opposed to a full Dataiku project, so this is a feature that can be configured multiple times per project. To change computation engines, double-click on a recipe and then click on the gears next to the text under the run button. From there, you will see a list of engines available based on where the data is located. You can see in the image below that Dataiku will place a star by the computation engine that it recommends:

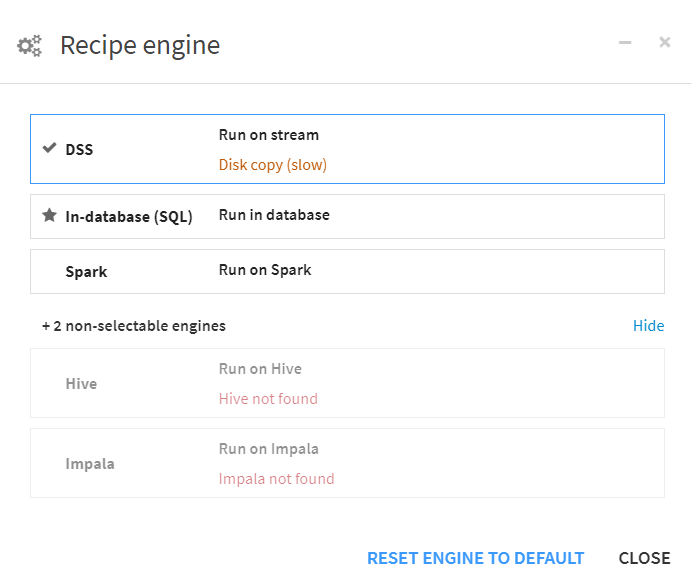
Types of Computation Engines in Dataiku
While there are several different computation engines, I’ll group them as the following:
DSS Built-in Computation Engine:
This option will always be available to you, no matter what data you are using or where it comes from. It has all reading, writing and calculations performed by your Dataiku instance. However, unless the specs on your Dataiku server are out-of-this-world, this will typically yield the slowest results. This is also the default option when constructing your Dataiku flows. Lastly, this will also bring a copy of your data into your Dataiku instance, so be mindful of the volume of data that will be processed.
Using your underlying database or other infrastructure:
Depending on the location of your data as well as your available infrastructure, you may have more options for your computation engine that can drastically increase the efficiency of your data pipeline. For example, if you are working with data that lives in a Snowflake database, you can push calculations and transformations to your Snowflake instance rather than your Dataiku server. Additionally, if you have an available instance of Apache Spark, Hive or Impala, you can also utilize these technologies for your pipelines. In almost every situation, this will yield a more efficient and quicker pipeline. However, it is important to keep external factors in mind. For example, Snowflake credit usage should be considered. Make sure to follow best practices for all technologies involved outside of Dataiku.
Note: Not every function within Dataiku can be pushed to alternate computation engines. For instance, various operations in a prepare recipe cannot be converted to SQL, so you will be unable to use your database for computation. To work around this, try to group calculations that are SQL-compatible away from SQL-incompatible operations to maximize your database usage. To see more about which recipes can utilize this capability, see the chart here.
SQL Pipeline Optimization
When building a flow in Dataiku, every recipe will output a dataset. If you are an analyst performing ad-hoc transformations to explore your data, then this is ideal. However, if the end goal is to create the most efficient pipeline as possible, then this will result in unnecessary reading and writing to datasets. Within a Dataiku flow, multiple consecutive SQL recipes or SQL-compatible visual recipes can be configured to skip the writing of intermediate datasets by using the experimental “SQL Pipeline” feature. A similar feature exists for Apache Spark; however, we will be focusing on SQL pipelines for now. By enabling this feature, multiple consecutive recipes that utilize the same SQL computation engine will skip the intermediate reading and writing of datasets. Rather, your initial dataset will go in, and your final dataset will be written with nothing left in between. Enabling this feature is easy.
Enabling the SQL Pipeline
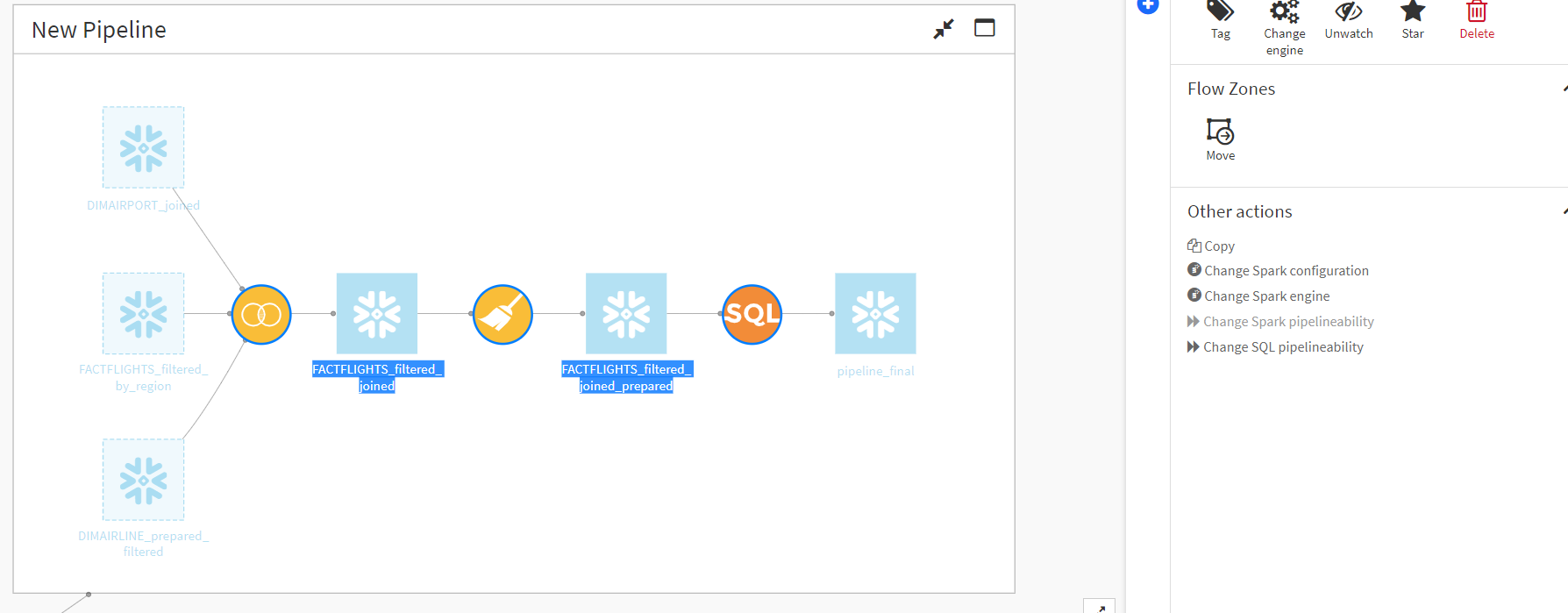
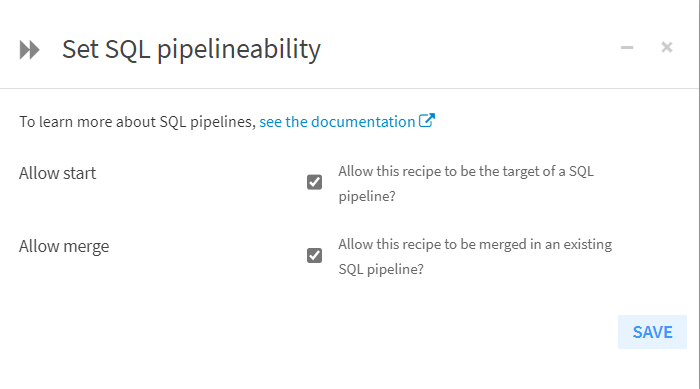
1. Select each recipe that will be a part of your pipeline by holding “ctrl” and selecting each one individually in your workflow view. Within the “Actions” section of the pane that opens to the right, under “Other Actions,” there is an option to “Change SQL pipelineability.” Within this menu, tick the boxes to allow those recipes to be part of a SQL pipeline:
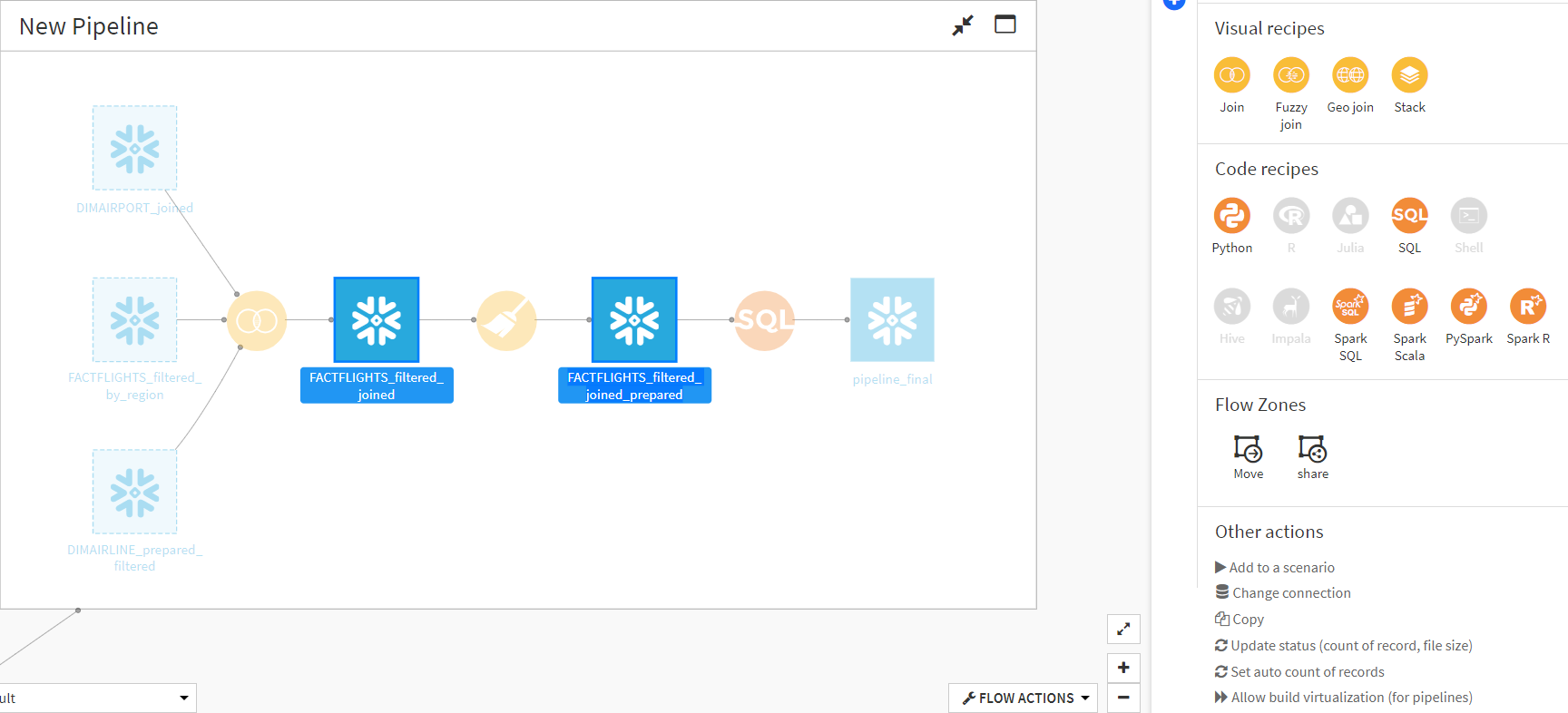
2. Despite not being built by the SQL pipeline, the intermediate datasets will still appear in the flow. Select all intermediate datasets. Like the previous step, under “Other actions,” there’s an option to “Allow build virtualization (for pipelines).” Make sure this is selected for all intermediate datasets:
Testing it Out
To dive into these different methods, I’ve constructed a single Dataiku workflow that performs the same data transformations using three methods: using the DSS computation engine, pushing calculations to Snowflake, and using the SQL Pipeline feature with Snowflake. Pictured below is the full flow:
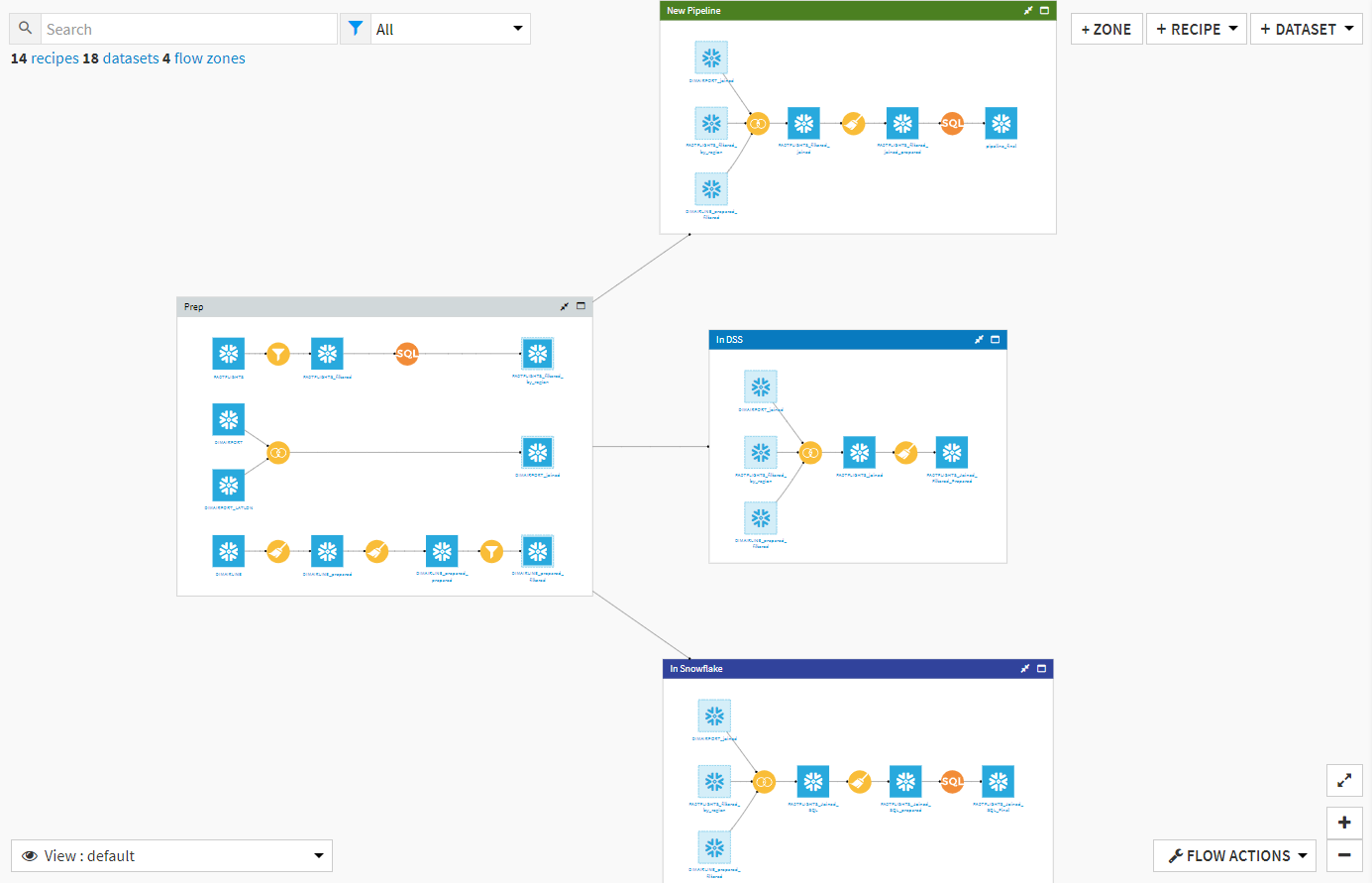
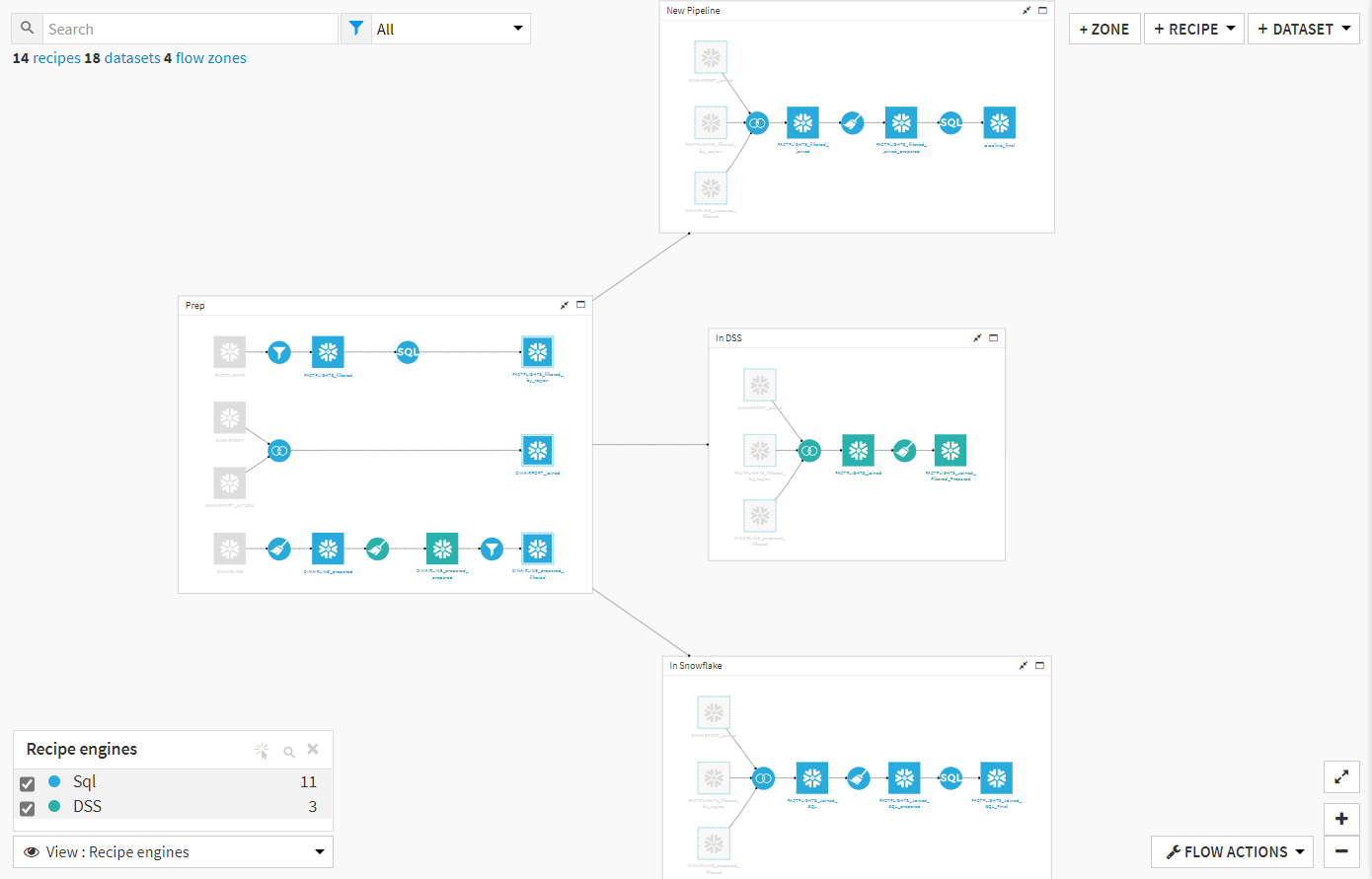
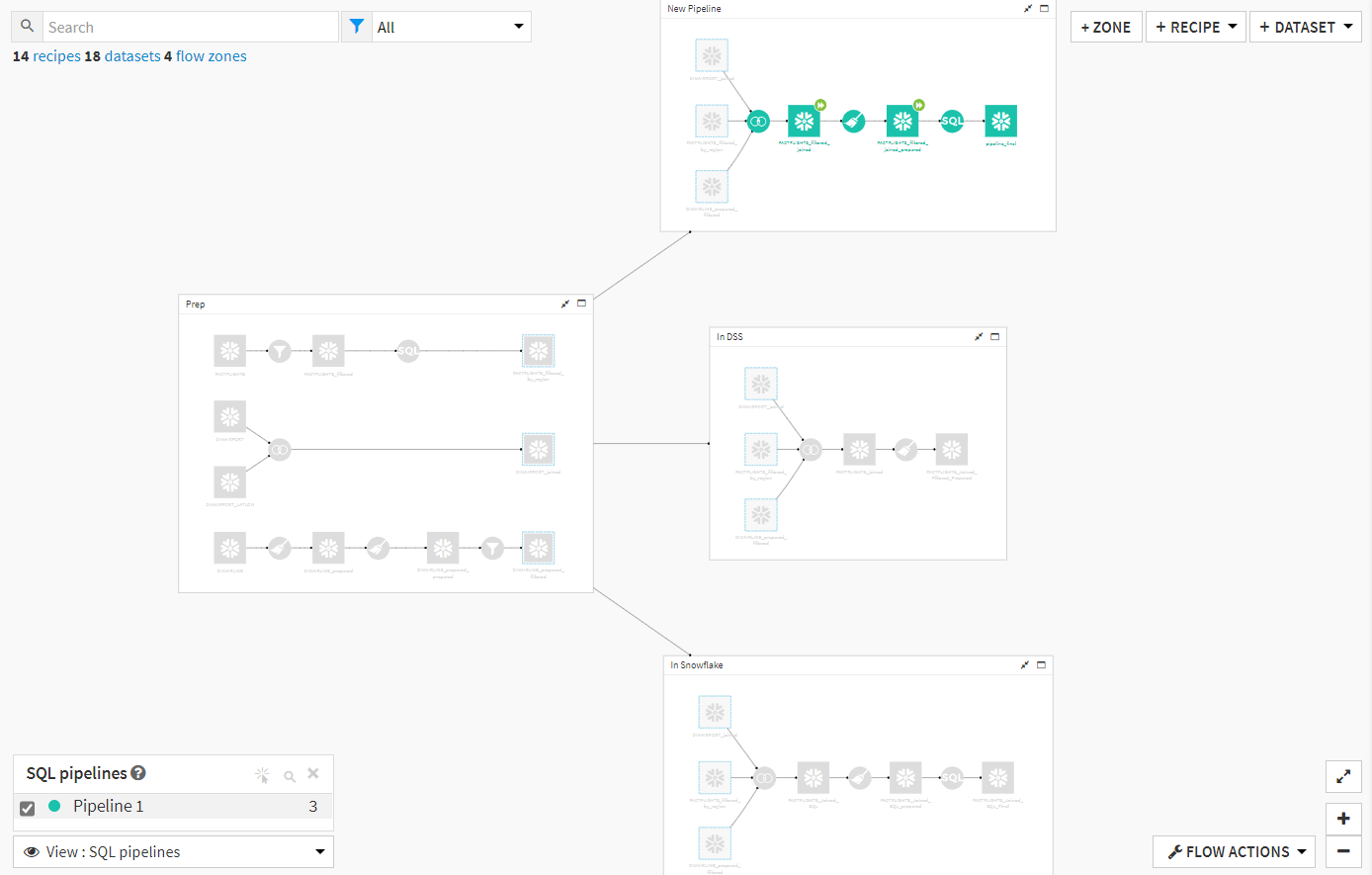
This experiment utilizes FAA data tracking flights from all over the US across many years. In the section labeled “Prep,” I have filtered down the full FAA dataset to a specific set of airlines that took off in a specific group of states in the US. Then, the data is joined and cleaned using the discussed computation engines. At the end of the flow, the datasets are just shy of 3 million rows long. By using different views of the Dataiku flow, we can confirm that one branch uses the DSS engine and two use the Snowflake engine. We can also confirm that one of the branches using Snowflake is a SQL pipeline:
I’ve created a scenario that runs all three sections of the flow in succession, and we can look at the time needed to finish these jobs as a comparison point:
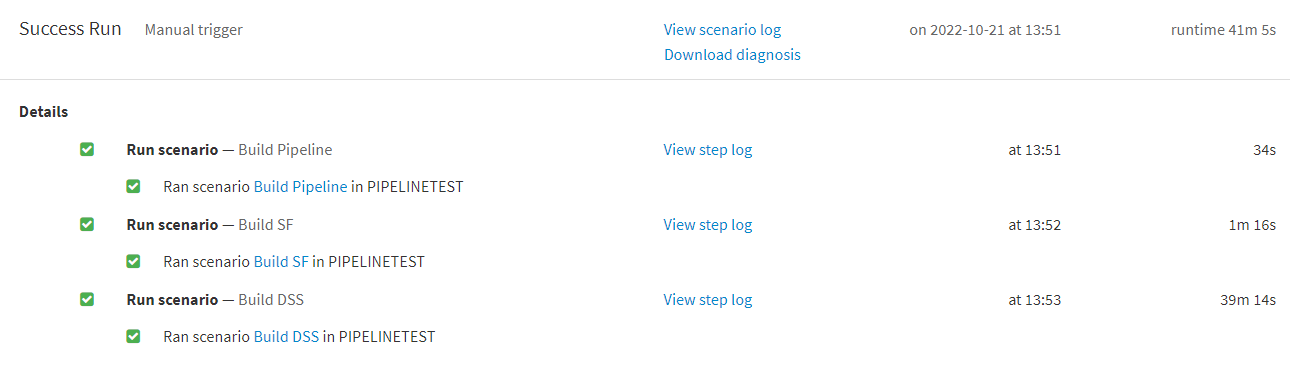
Looking at the runtime for each branch, we can see that using only the built in DSS engine results in significantly longer runtimes. If we were to scale this to enterprise-level pipelines that handle larger quantities of data, then we could potentially see flows that take hours to run.
Consider this: let’s say your BI department seeks out to build dashboards in Tableau that reflect the most recent data, and these dashboards are dependent on data sources built via Dataiku flows. Looking at the result of this experiment, we know that if the Dataiku flow were not optimized, then those dashboards would not be updated as often as requested.
We’re Here to Help
If you are interested in Dataiku or have recently purchased it, you should know that InterWorks can help with adoption and enablement with trainings and workshops, among other offerings as well. If you’d like to know more, then feel free to contact us! You can also try out a 14-day free trial of Dataiku here.