
A first look at Alteryx Designer Cloud powered by Trifacta.
As an Alteryx (Designer) user like me, you have probably heard of Alteryx Designer Cloud powered by Trifacta. If you want to know more about Alteryx Designer Cloud and how it compares to the traditional desktop variant of Alteryx Designer, this blog is just for you!
When Alteryx bought Trifacta earlier this year, many were wondering if this meant the end of an in-house developed cloud edition of the familiar Alteryx Designer. Did they buy Trifacta so they could use their technology in Alteryx’s future cloud offerings, or was the plan to rebrand Trifacta and bring it into the Alteryx universe?
It seems the latter is true and Trifacta has been rebranded as Alteryx Designer Cloud powered by Trifacta. Within the product itself, there is no sight of anything Alteryx at the moment. The UI is different and does not resemble Alteryx Designer. Terminology is different, too. If you are used to Alteryx Designer, do not expect to just transfer those skills straight to Trifacta, though the hope is that we will see more “Alteryx” in the product (and not only branding wise) when time goes on.
All of this does not mean that Trifacta or Alteryx Designer Cloud powered by Trifacta is currently a bad product. On the contrary, it seems a pretty good data wrangling and preparation tool.
Just a quick heads-up, when I mention Trifacta, I mean Alteryx Designer Cloud by Trifacta. Where you read Alteryx, I mean Alteryx Designer.
If It’s Not Alteryx Designer in the Cloud, Then What Is It?
Trifacta is a data wrangling, preparation and orchestration tool in the cloud. It connects to a multitude of different data sources, which are also preferably in the cloud. Local files can be uploaded but are limited to 1 GB; so if it’s bigger, you have to drop it into an S3 bucket (or SFTP) at the moment. Also, a lot of other connections are “Early Preview” right now:
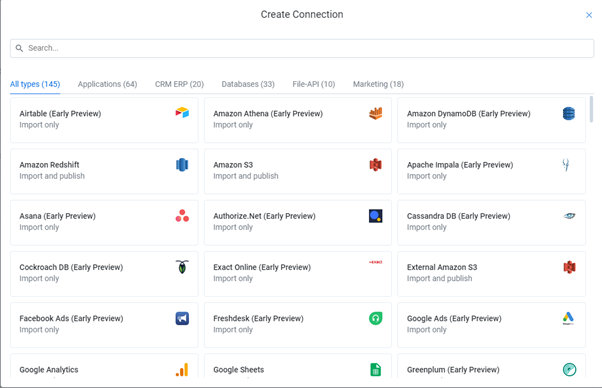
While in Alteryx, you just drop an Input on the Connect In-DB tool in your flow to kick things off. In Trifacta, you have to set up connections up front. From these connections, you can fill your library with data sets. The library is also the place to drag and drop CSV files (as long as it’s less than 1 GB). Now you can start building a flow, which is the loose equivalent of an Alteryx workflow.
Recipes and Data
A flow starts with one or more data sets and ends with one or more outputs. In between, there are recipes. Unions and joins are also visible and can be made within the flow or within a recipe, but within the recipes is where the magic happens. A recipe itself is perhaps best compared to a container or a single strand of tools in an Alteryx workflow.
If you are familiar with Dataiku, you know about recipes. Trifacta works very similarly. Transformations (wrangling) happen inside the recipe, and just like a real-world recipe to make a dish, there are multiple steps to get to that final product. The steps are similar to individual tools in Alteryx as they all do one thing, such as group by (which seems equivalent to the summarise tool in Alteryx), pivoting and unpivoting (similar to the crosstab and transpose tool), dynamic renaming and single or multirow formulas.
In a simple transformation and clean up job, a single recipe is enough. Formulas, pivots, sorting and ordering can all happen in this single recipe. Even if you join two data sources, you might only still need one recipe. However, sometimes you need more than one recipe to get to the output – just like when you make a fancy dinner with multiple recipes.
In this example, I’m using multiple recipes:
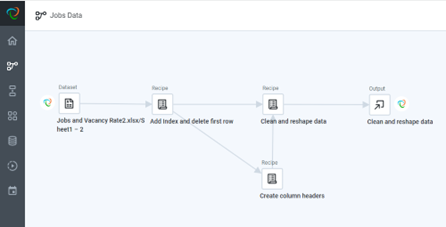
In my first recipe, “Add index and delete first row,” I start off with a bit of pre-cleaning and add an index to my data to keep everything in the right order later on. I then split my data into two recipes – the first one, “Create column headers,” is to clean up my “multiple header rows.” The second recipe, “Clean and reshape data,” does a fair few transformations to get the actual data in the right shape, but halfway through the steps “receives” the header data to union back into the main data. This union is visible in the flow itself, but it is also a step in the “Clean and reshape data” recipe.
In this screenshot, you can see the recipe editor:
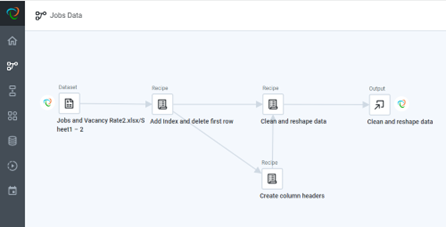
On the right-hand side are the steps and on the left-hand side is a sample of the data. You can see intermediate data samples after every step.
Output Sources
After all the recipes are done and your data is in the shape you like, it can be output to several (cloud) databases, an S3 bucket or a CSV file for later download. Interestingly, there does not seem to be a way of connecting it up directly to Alteryx even when you output it as CSV file. This is because Trifacta uses the TFS protocol of storing the CSV files and Alteryx cannot connect to this protocol without using a third-party tool with a command-line batch file to run and download it.
Scheduling and Orchestration
What turns Trifacta into a fully fledged ETL and data pipeline orchestration tool is the ability to not only schedule your flows, but combine the execution of many flows via a plan. A plan in Trifacta enables you to plan the executing of flows and define the sequence in which they need to run. Plans are also built visually. Each step is a flow or task configured to run based on conditions you define, such as the success or failure of a previous task. Flows can also run in parallel, and you can add additional tasks such as sending messages to Slack when (parts of) a plan has been executed (un)successfully, deleting temporary files or even sending a HTTP request.
The Good
- Trifacta is cloud native and therefore highly scalable since it runs on the compute of the cloud data warehouse and is not dependent on local databases.
- Better path to deploy and productionalise the tool. Since Trifacta is a cloud-native tool, rolling it out is straightforward compared to Alteryx, which needs local installations and a separate server tool (Alteryx Gallery) to productionalize the (work) flows.
- Intelligent transformation predictions and suggestions, such as automatically creating the logic to parse out parts of a string based on your selection. For example, by clicking the zip or post code element of an address string, Trifacta will suggest the parsing logic for the whole column.
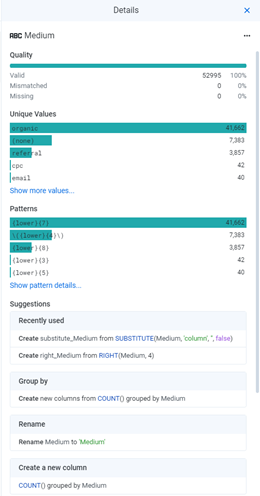
- Insightful data summaries in recipes, giving a quick overview on data hygiene, unique values and data patterns:
- Scheduling and plans enable you to easily and fully automate your data pipelines and turn Trifacta in a full-fledged ETL/ELT tool.
- Straightforward, no coding and visual – see data along every step of all the recipes.
- Custom-SQL-like option for non-db data connections, such as Google Analytics, Jira and Facebook/Instagram/LinkedIn ads.
The Bad
- Not as visual as Alteryx. Steps inside a recipe are shown as a list of items and not a flow.
- If you are familiar with Alteryx, you should not assume that Cloud works the same. You might struggle to find the equivalent of Alteryx tools in your recipe configuration straight away.
- Some transformations are overly convoluted. You cannot simply change a decimal to integer; it needs a formula, and working with dates can be painful if you do not use the right order. Trifacta tends to convert dates to integers when doing data calculations.
The Ugly
- Lack of geospatial functions. Trifacta does not recognise geographical fields or coordinates.
- There seems to be a lack of configurability with some data sources and connections. I ran into issues where Trifacta made assumptions about the data that where not correct, which I could not change in the connection or fix downstream.
- Community is small and not very active – you struggle to find answers.
The Bottom Line
As you might have noticed, Trifacta is definitely not the same as a cloud version of Alteryx. It’s a completely different tool, which can give you the same results but in a different way. As such, it doesn’t make a lot of difference if you’re new to the world of Alteryx or a veteran user of Alteryx, this is a new tool that you need to learn about first.
However, it is still a great data transformation tool with little to no coding, which enables teams to transform data without engineers or SQL skills. The fact that you can schedule and plan a whole sequence of flows makes it a great ETL/ELT tool, intelligence predictions and data summaries give a quick understanding of the cleanliness of your data and transformation suggestions can help the user find insights about the data in a jiffy.