
A couple of months into my life at InterWorks, I was asked to shadow an Alteryx project for a client. Well, I did not actually end up shadowing; it became more of an Alteryx challenge set by the project lead.
“Robin, instead of you just staring at what I am doing, can you take these workflows and figure out an automated way to document the data lineage backwards from the outputs?”
There were a lot of long, complicated workflows that this client needed to be rebuilt, which meant I was figuring out exactly what these workflows were supposed to do at every step. I was basically reverse-engineering them, which took a lot of effort. However, for exactly the same reason that it is difficult and involved to reverse-engineer a workflow manually, it is very difficult to do this programmatically – there are just an awful lot of “rules and exceptions to those rules.”
As a result, this has now become my greatest Alteryx challenge to date. It’s not like no one has tried this before (see the Alteryx Auto Documentation Tool). This Alteryx app documents the tools used in a workflow pretty well and includes the order of tools, so I could steal some ideas from it. However, it does not give a clear order of operations—apart from showing an image of the workflow—so this is not helpful in trying to trace back the data lineage from output tools. It does do a great job in describing the tools used, though.
Parsing Tool Configurations
I quickly found out that an Alteryx workflow is just an XML file, and since Alteryx can handle XML files all right, the initial input of the workflow isn’t an issue. I started out trying to parse the properties of tools that can be in a workflow, but since every tool has its own purpose and configuration, this meant I had to create an awful lot of mini workflows to deal with every tool that can be used in a workflow. So, how many different tools are there in Alteryx … well, I didn’t count them, but my temporarily embarrassed fully functional workflow documenter (😊) can deal with approximately 25 tools I’ve come across testing my work. I then went on to normalise the output of all these sub workflows dealing with a single tool at a time, generating a long list of considerations and questions:
- Tool ID and names
- What happens at the tool level (Tool Action), i.e. how the tool is configured
- What happens at the field level (Field Action) like flagging a newly created field in formula or summary tools, or flagging the join fields for a join tool
- Is the field selected, or does this field come out at the other end (more about field selection later as this is a headache of a subject in its own right)
- Is the field renamed
- What input does the field come from (if the tool has multiple inputs)
Not all this info applies to all tools of course, but it does generate a standardised output across all tools the workflow can handle now.
The Order of Operations
Okay, next challenge is the order of operations within a workflow. For a workflow like this, that’s obviously quite straightforward. There is a single start and end point, and the workflow doesn’t split or merge along the way from start to end:

But as soon as there are multiple start and end points, and splits and merges with or without joins and unions, the order of operations becomes as clear as mud. And the technical order of operation – in what order Alteryx does things – isn’t even that important. It is about understanding what fields are ‘arriving’ at a tool, which are ‘processed’ by the tool and which fields come out at the other end of the tool. If you have a situation where two streams are combined by a join or union tool, we need to know what fields arrived from stream one and stream two to be able to figure out what fields pass through and are being output by the join tool. But the workflow’s XML doesn’t keep a record of all fields that pass through a tool—only the fields that have something happening to them or are exceptions. More on how we know exactly what fields go in and come out of a tool later. First, we need to figure out how to put everything in the right order.
To work this out, my logic (which is overly convoluted, I know) takes every possible route as one ‘flow’ within the workflow. Consider this workflow:
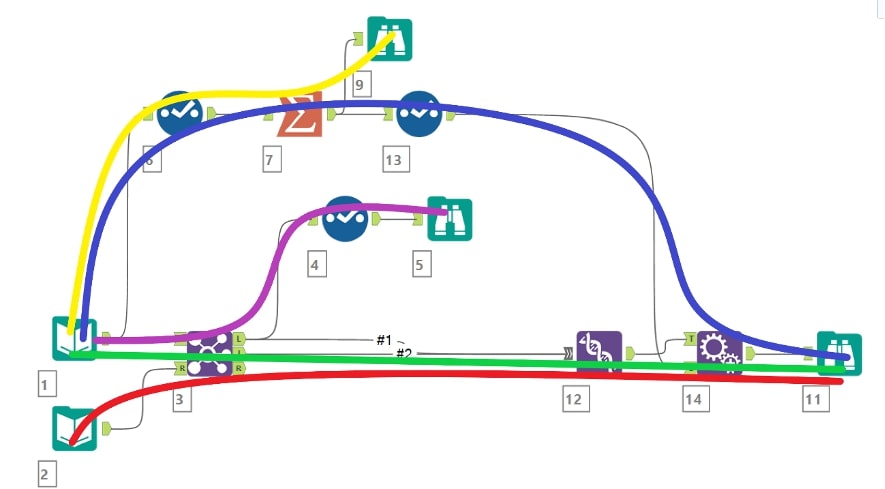
According to the logic I use, this workflow has five individual flows. There are three flows ending in the Browse end point (ID 11) at the right side of the workflow, the blue (1), red (2) and green (3) flows. The other two flows, yellow (4) and purple (6), have their own end points. Dealing with the workflow in this way ensures I can capture everything that happens to data passing through a tool, regardless of origin, when I join the configuration or properties of the tools back to this ‘order of operations’ data:
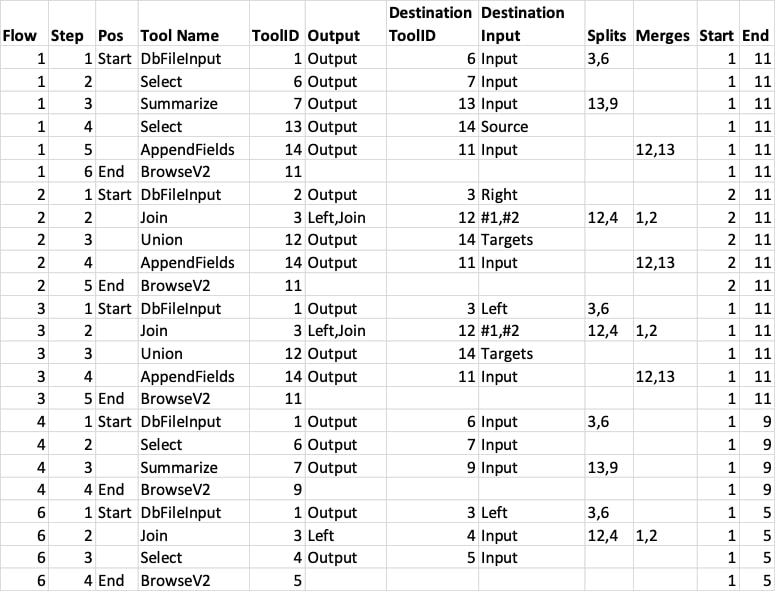
The ‘order of operations’ data includes splits and merges, as well, to indicate if the output of a tool has multiple destinations, or if the input of a tool has multiple origins. Interestingly in this case, flow number 5 has disappeared. This is the flow going from Input 2 to Browse 5 shown as a dotted line, and whilst that looks like an unbroken flow, since Input 2 enters the Join tool on the right input side and Select 4 connects to the left output side, no data from Input 2 can end up at Browse 5. A union tool to union the left output with the join and/or right output would ‘enable’ flow 5.
Field Selection, or How to Figure out What the Output Is of a Tool
When looking at the configuration of a single tool, it doesn’t necessarily tell you what fields pop out at the other side. For example, a select tool not doing anything will only show the *Unknown field in the parsing output. This does tell me that all fields that go in will come out. If a field is renamed, it will flag this field as selected, plus the *Unknown field. After some testing, the logic I figured was:
- If *Unknown is ticked, all fields will be output unless the parsed data explicitly shows a field as not selected – this tool-level behaviour I flag as ‘All’ or ‘All Except’
- If the *Unknown is unticked, no fields will be output unless the parsed data explicitly shows a field as selected – this tool-level behaviour is flagged as ‘Selection’
This same behaviour applies to Join, Join Multiple, and Append Field—tools with embedded select tools.
Other tools have their own quirks in handling what fields come out. A Union tool doesn’t show any fields being output but by default will output anything. A Summarize tool will show any field being output, so you know exactly what comes out without knowing the flow tools prior to the Summarize tool. With this in mind, I grouped the tools into three types:
- Outputs nothing that comes in (by default)
- Outputs everything that comes in
- It depends on the config of the tool
The output-nothing tools include the Summarize tool as, although it can output fields as they have come in, it will not ‘take over’ a field from a previous tool without it being in the tool’s configuration. Other tools in this group are the Crosstab, Transpose and Input tools. Tools that will output everything include Formula, Filter and any output tool. Dynamic tools, such as Dynamic Rename, pose a bit of a challenge as the output is often unknown if the workflow has not yet been run or edited on the machine you analyse the workflow on.
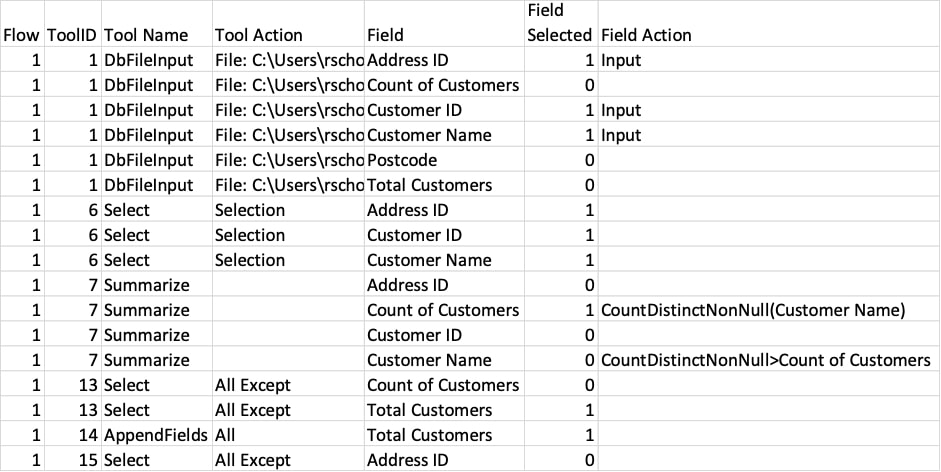
Armed with this logic, we now need to figure out which fields arrive at a tool and, based on the tool’s behaviour, what comes out to arrive at the next tool. If a field is not explicitly ‘mentioned’ in a tool, I need to check what fields are selected (explicitly or implicitly) in the previous tool, based on the order of operations for the specific flow we are analysing. After cleaning up this data, we now have a reasonable, but very data-heavy, dump of the Order of Operations, fields, actions, and how the output data came to be. But you need patience and a notebook to figure out the bits that are relevant. Also, you need to read the output upside-down for data lineage purposes. See below for an extract of the data as it looks now:
Reducing Data Load and an Attempt at Data Lineage
Next steps are to show everything the other way around and limit the data only to fields that are actually output and actions that have an actual impact on those fields only. The data-heavy Order of Operation and fields dump are needed as a base for this – we now know basically everything that happens in the workflow, so let’s reduce it to what really matters.
Putting everything in reverse order from Output to Input is the easy bit. Trying to figure out how a field appearing somewhere in the middle of the flow came to be is a bit trickier. For example, let’s assume that the fields Customer Name and Region are in my input A and Customer Growth Forecast % and Region are in input B. The output of my workflow gives me the forecasted Customer count by Region.
Within the workflow, the following things happen:
- Distinct count of customers by region
- Joining the Distinct Count to my Forecast percentages on the Region field
- Calculating my absolute forecast figures by region with a formula tool
Since the formula will refer to two fields, it cannot easily figure out the lineage by simply looking at a prior field. So currently, the workflow uses a macro to parse ‘raw’ formulas by looking at anything that could be a field.
Fields in Formula tools and in the expressions of other tools often appear in brackets but not always if someone types out the formula manually. As a result, we need some heavy-lifting and the macro to parse expressions to find out if the origin fields will compare all phrases within the expression to fields within the same flow, as well as check previous field names.
Then finally, we need to check for erroneous connections when trying to find our way back from end to start for output fields. For example, we have multiple flows ending in the same end point – in one flow, we have our individual customer data, and in the other flow, there is aggregated customer data. Both flows use the same origin data, so when tracing back our steps for Customer Name, it will find this in the individual customer data flow and the aggregated customer data flow (prior to the aggregation happening).
So, our final step is checking if the order of operations still makes sense and the lineage isn’t moving between flows when trying to order the operations of a single output field. This is done by checking how many Order of Operations steps are between every ‘touchpoint’ of a field. If there is more than one step in between, we disregard the whole flow that this touchpoint is in for the purposes of data lineage. The final output (excerpt) looks like this:
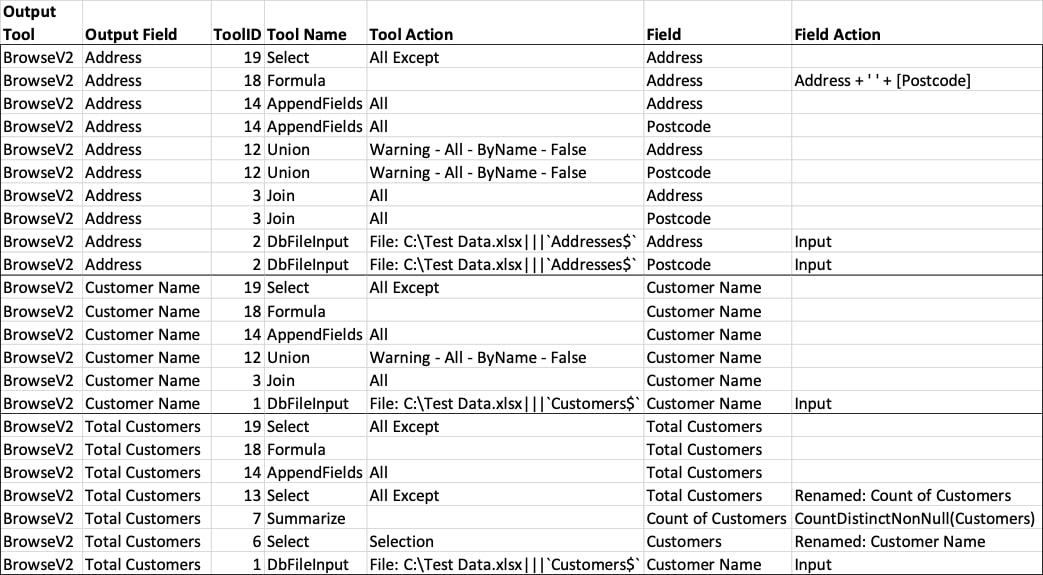
There are three fields in this output: Address, Customer Name and Total Customers. Address is a combination of two input fields called Address and Postcode, Customer Name hasn’t been touched, and Total Customers originates from Customer Name, first being renamed to Customers then summarised as a Count of Customers and then renamed to Total Customers.
As you can see, the thing has become a bit of a beast of a workflow – this doesn’t even contain the macros and nested macros (I think there are about 10 macros in this workflow now). Some of the challenges that I couldn’t work out during the days were worked on in the middle of the night after dreaming in Alteryx workflows:
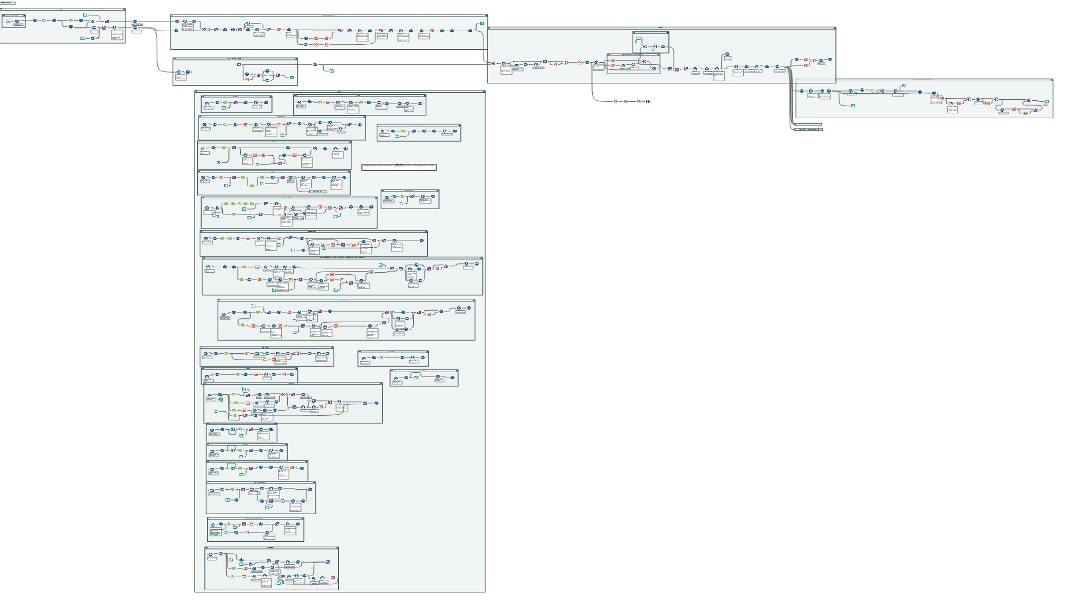
A Work in Progress
I am pretty sure bugs are still plentiful in the workflow parsing, combining and analysing all this data—mostly because of behaviour I didn’t take into account or exceptions to the rules I’ve put in place when trying to deal with all the different ways data moves through a workflow. I’m still testing this Alteryx Documenter with larger, more complex workflows, and I uncover new things every time I work on it. So, stay tuned for my next installment of Adventures in Alteryxland where I’ll tell you all about the bugs I found and hopefully fixed. If you want to have a play with the Documenter, please drop me a line, as I need to package it all up due to a lot of (nested) macros.