
A regular expression, also commonly known as RegEx (pronounced as /reh-JEKS/), is a powerful text-processing framework that uses a sequence of characters to define a search pattern. It is a widely used method to identify if a pattern exists in a chunk of text, and it helps you extract that information if you need it. As a data analytics professional, possessing a fundamental understanding of RegEx can significantly improve your productivity and ability to perform various data transformation tasks for projects that involve text-based data.
Why Should I Learn RegEx?
Alteryx comes pre-built with some powerful string functions to allow you to conduct text parsing and manipulation. Several of the ones I use often are:
- Contains (…): Searches for a substring within the main text
- Left (…): Returns the first N characters of the string from the left
- Right (…): Returns the first N characters of the string from the right
- Length (…): Gives you the length of the text
- Trim (…): Removes trailing white space from the ends of the text
These functions, along with a myriad of other great string functions in the Alteryx library, are great to have in your toolkit. I highly encourage you to browse through the Alteryx documentation to get a full list of these functions.
Perhaps now, you may be wondering, “Where does RegEx fit into the picture then?”
Regular expressions are not meant to replace the Alteryx string functions; rather, they are meant to extend your text mining and data manipulation superpowers by allowing you to create custom search patterns for more advanced use cases. In fact, I use both methods all the time in developing ETL workflows in my various projects!
Regular expressions are not meant to replace the Alteryx string functions; rather, they are meant to extend your text mining and data manipulation superpowers by allowing you to create custom search patterns for more advanced use cases.
This blog tutorial will provide a hands-on example of using RegEx in Alteryx to help you get started ramping up on this powerful framework for your text processing and analytics workflows. Being proficient with RegEx also opens the door to more advanced text analytics use cases, such as Natural Language Processing (NLP), Sentiment Analysis and many more.
Note: Sample datasets and the Alteryx workflow referenced in this article can be downloaded at the end of this post.
Use Case: Parsing Credit Card Transaction Information
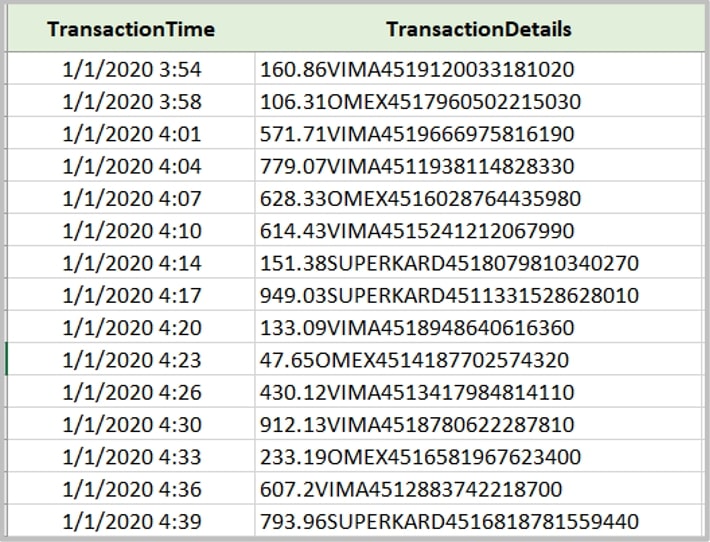
In this hands-on example, we are presented with purchase transaction data from a fictional Point-of-Sale (POS) system, where each record represents a purchase recorded with a timestamp. Our goal is to parse the [TransactionDetails] column to help us derive three important pieces of information: the amount of the purchase, the credit card company and the account number of the customer:
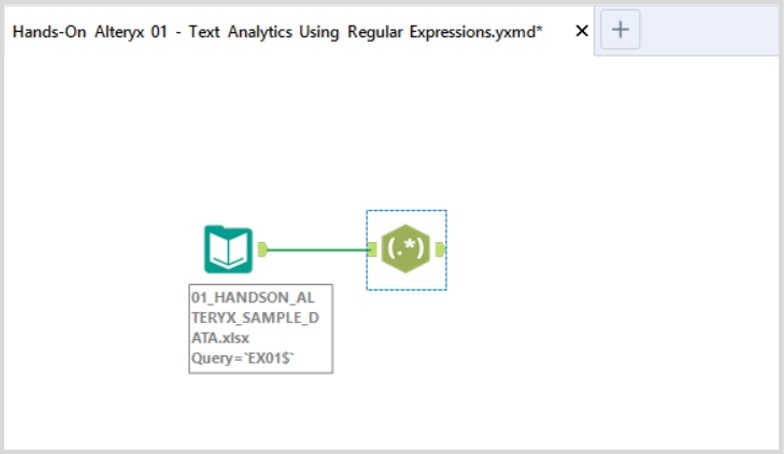
Step 1: Set up Your Workflow
To start, let us ingest the sample data (Sheet EX01) into Alteryx Designer. Drag the Input Data tool and RegEx tool onto the workflow canvas:
Step 2: Configure the RegEx Tool (Where the Magic Happens)
Next, follow the configuration settings as depicted in the screenshot below:
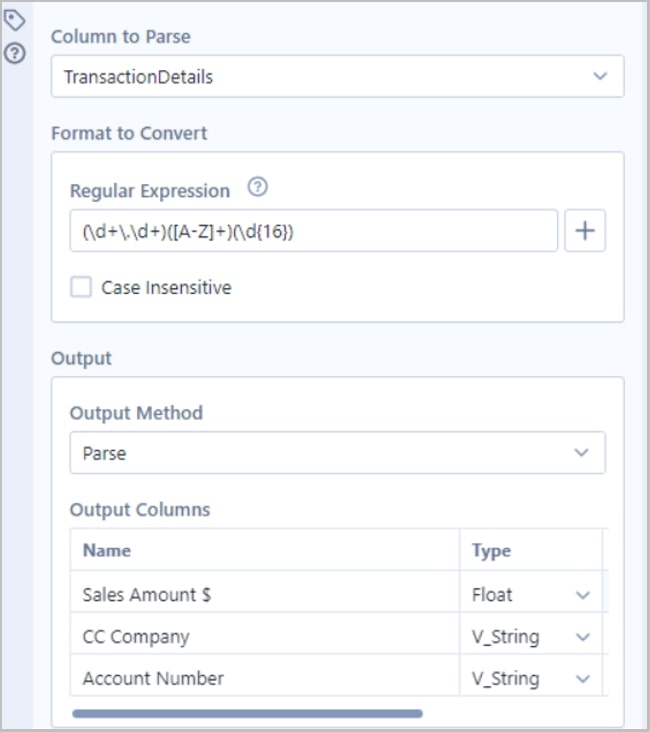
Here’s a detailed explanation on why the RegEx tool was configured this way:
- Column to Parse = ‘TransactionDetails’: this is the field of interest
- Regular Expression = (\d+\.\d+)([A-Z]+)(\d{16}): copy the regular expression into the text input; we will unpack this in the next step
- Output Method = Parse: our goal is to create three new columns to denote the sales amount, credit card company and account number
- Output Columns: here, we cast the fields to their correct data types and rename the fields to a business-friendly name
Step 3: Let’s Unpack the Logic
Now for the fun part. Let’s try to understand the regular expression pattern you’ve input to parse out our three fields of interest:
Set up the Different Groups

The parenthetical symbol ( ) above is a RegEx metacharacter that allows us to chunk our text string into three distinct groups. Remember from our initial data preview that we are interested in parsing out the amount of the purchase, the credit card company and the account number of the customer. Next, let’s take a deeper dive to the patterns we’ve written inside each group.
Parsing the Transaction Information
Let me introduce you now to some common characters and symbols you’ll need to get familiar with in creating your own RegEx patterns. This is by no means an exhaustive list, but here are some of the basics you’ll need to know as we solve for this business use case (Here’s a handy RegEx cheat sheet to help out):
- \d: matches any decimal digit character
- \D: matches any non-digit character
- \w: matches any word character
- {…}: defines an explicit quantity inside the bracket
- […]: defines a set of characters to match
- [a-z]: matches lowercase characters from a to z
- [A-Z]: matches uppercase characters from A to Z
After all that preliminary information, the tabular view below summarizes and explains the logic of the pattern we constructed:

Your Final Output

Important Considerations
The “.” symbol in RegEx is a metacharacter, so it is used as a pattern to match any character string. In our sample scenario, we wanted to match the literal dot to denote the decimal point, so we will need to precede it with an escape character “\”, so the final pattern becomes “\.”
In terms of best practice, I recommend creating robust patterns that can account for various scenarios. In the screenshot below, notice the minor change I implemented in the RegEx tool configuration, wherein I assumed that the dollar figure would always have two decimal points only. The resulting output generated null values in the example highlighted because it did not meet these criteria:

Next Steps
I hope you found this hands-on tutorial interesting and useful. Please feel free to message me if you have any questions! Stay on the lookout for more Hands-On Alteryx blog entries in the future.