
What Are Variables?
If you have ever done any programming, and since you are reading this blog post you most likely have, you will be familiar with the concept of variables. They are these little helpers in which you can store almost anything, except any physical object (you cannot store your favorite book, but its name). You can give it a nice (meaningful) name and retrieve it wherever and whenever you need it.
Variables are a very neat concept and without them programming would be pretty difficult to implement and extremely inflexible.
Can We Use This in Matillion ETL (METL)?
Of course we can. Matillion has done a great job in providing different variable types for specific use cases, making it super easy to implement. OK, you have to get familiar with these types and how to use them, but it is pretty straight forward. This blog post will provide you with a general overview and hopefully enough information to get started.
Different Variable Types in METL
Environment Variables
Environment variables are of a global scope as they are accessible throughout your entire METL client. You can store values that can be used by multiple jobs, like the name of your database and schemas, specific connection strings or project names.
Job Variables
Job Variables are defined within individual jobs. They hold a scalar value and will mostly be used in a local, job-wide scope. However, they can be handed over to other jobs, which will be explained a bit later.
Grid Variables
Grid Variables are special in that they can hold a whole set of data, like a table. They are also only available within the scope of a specific job, but they can be provided for other jobs like the job variables.
Automatic Variables
Automatic variables are, hence the name, automatically available after setting up your METL project. They hold information about your environment, project or job, like the name and id for example. Matillion is providing a full list of the available Automatic variables and how to edit them.
How to Create Variables in METL
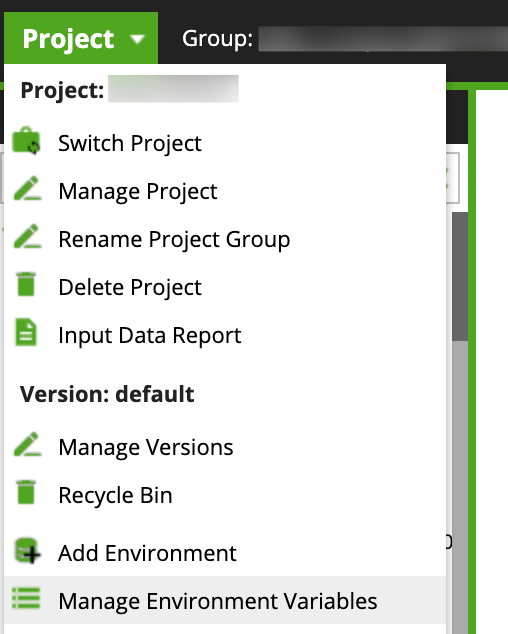
Environment Variables are available for the entire project. You can create them in the Manage Environment Variables dialog from the Project Menu:
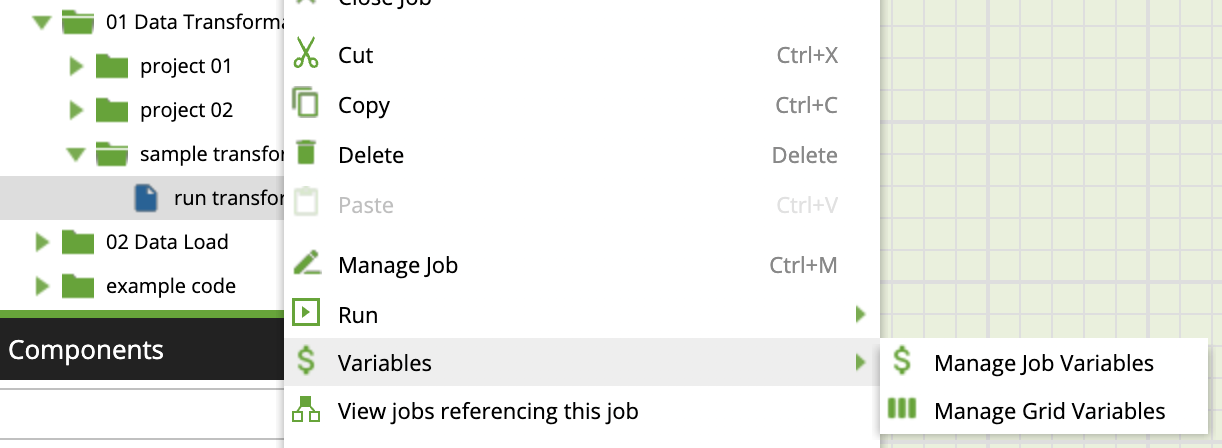
Job and Grid Variables are defined for each job, so they will be created in the Manage Job Variables or Manage Grid Variables dialogs. You can open these by right clicking on the job in the explorer menu or by right-clicking the canvas inside the open job.
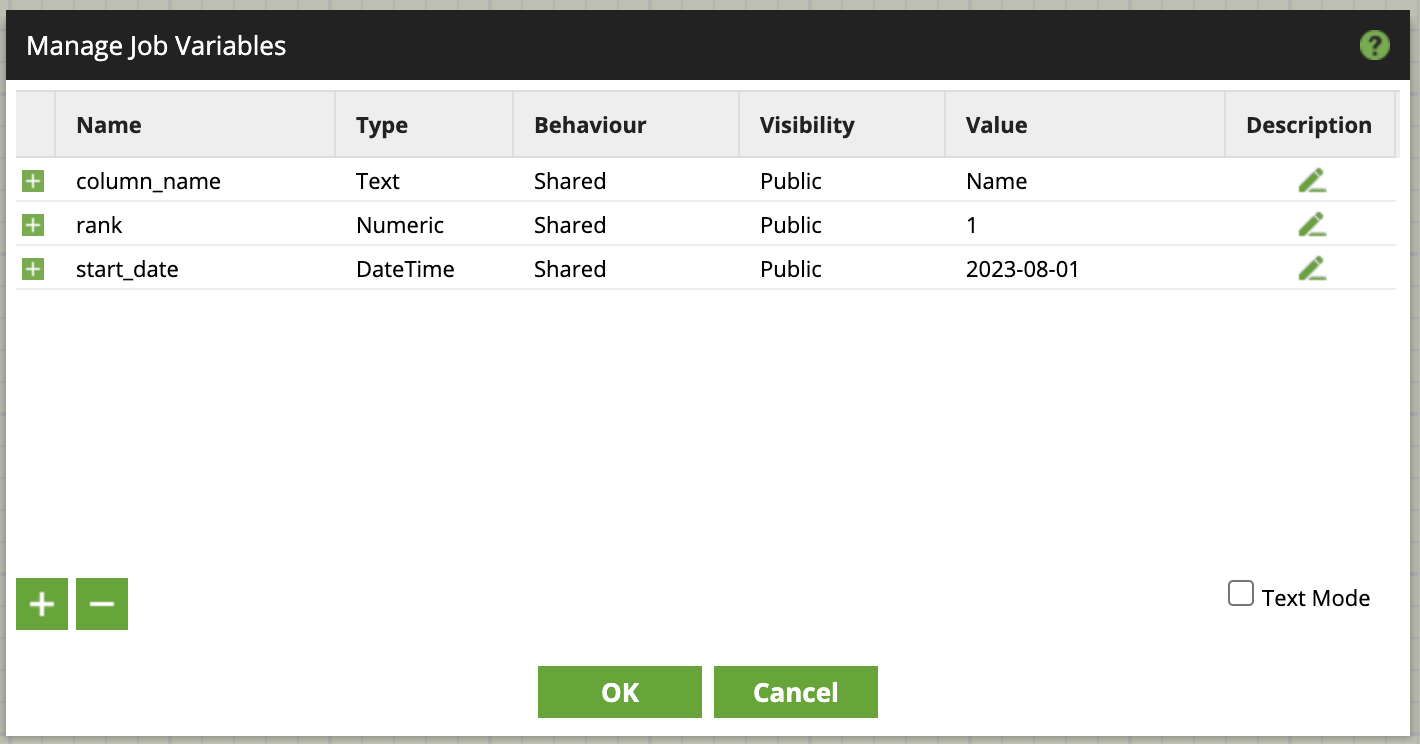
There are some settings that are common to all variables:
- Name: Give your variable a meaningful name.
- Type: This refers to the data type in which the variable is stored.
You can choose between Text, Numeric, DateTime and Data Structure. - Behaviour: This is referring to the way a variable is updated when used in multiple branches; for example, in a control structure or an iterator. You can choose between copied or shared. A copied variable will always start with the default value and keep any updates within the scope of the current branch. Each branch will get its own copy of the variable. A shared variable, on the other hand, will use any updates made throughout the entire job. It is shared over all branches.
- Value: Here you can set the default value for the variable.
- Description: An optional description, this can be very valuable for documentation.
Now to the specific flavours of each variable type. The Manage Environment Variables dialog will have additional options depending on your environment setting. Each of your environments will have its own column in which you can specify the value that is used according to the currently selected environment. For example, if you have two environments named dev and test, you will have two additional columns also named dev and test.
The dialogs for Job and Grid Variables will provide also an additional option:
- Visibility: This is referring to the scope of the variable. You can choose between Private and Public. When set to Private, the variable is limited to the current job, meaning it can not be seen in other jobs when using the Run Orchestration or Run Transformation components. Using the Public option, you can hand them over between jobs which will be explained later in this post.
For Grid Variables you have two more sections:
- Columns: Here you can define the Name and the Type for each column.
- Values: In this section you can provide default values for the created column.
In the animation below we create a Grid Variable named “test_grid” with two columns for “name” and “value”. These columns are populated with default values:
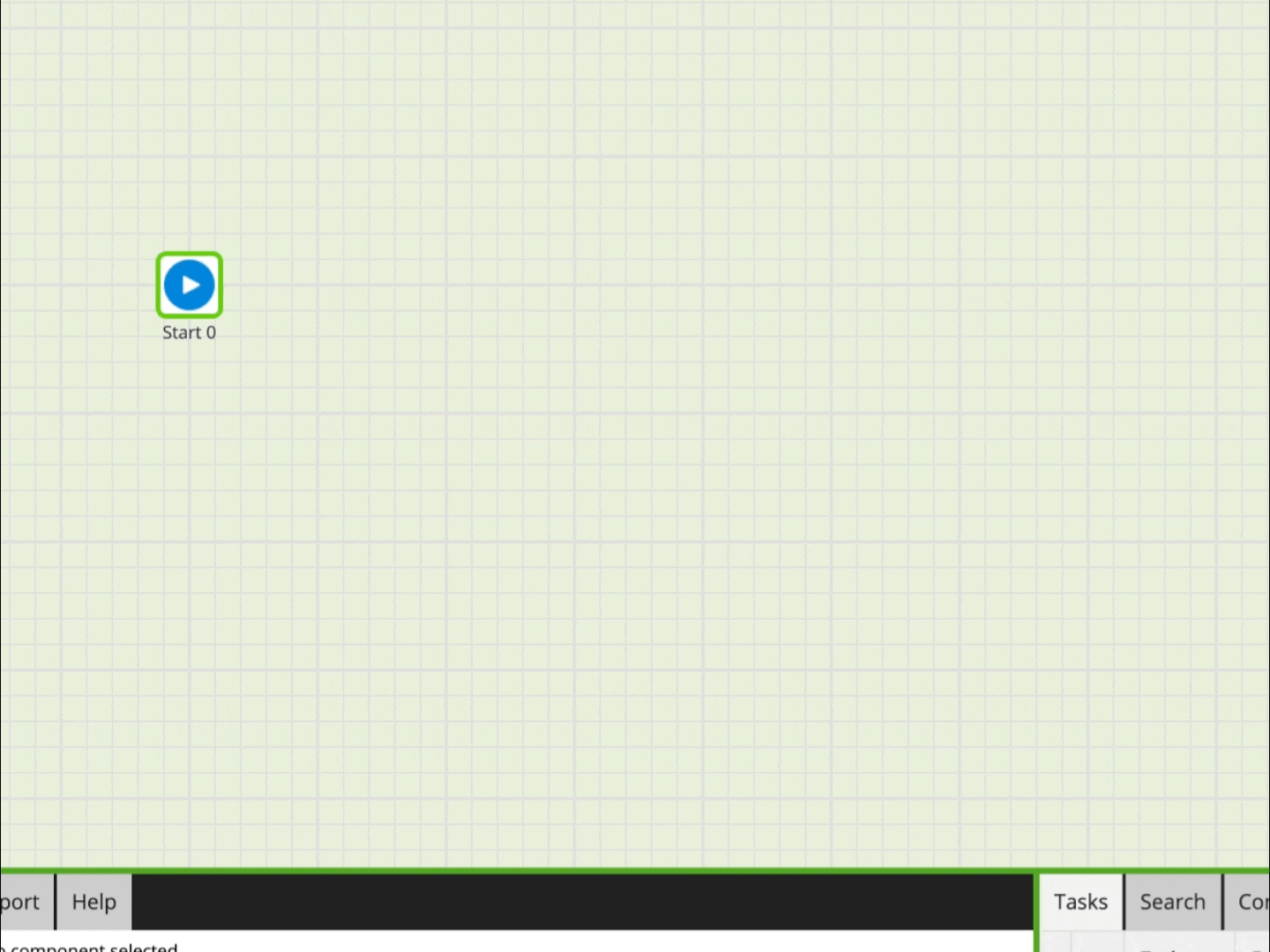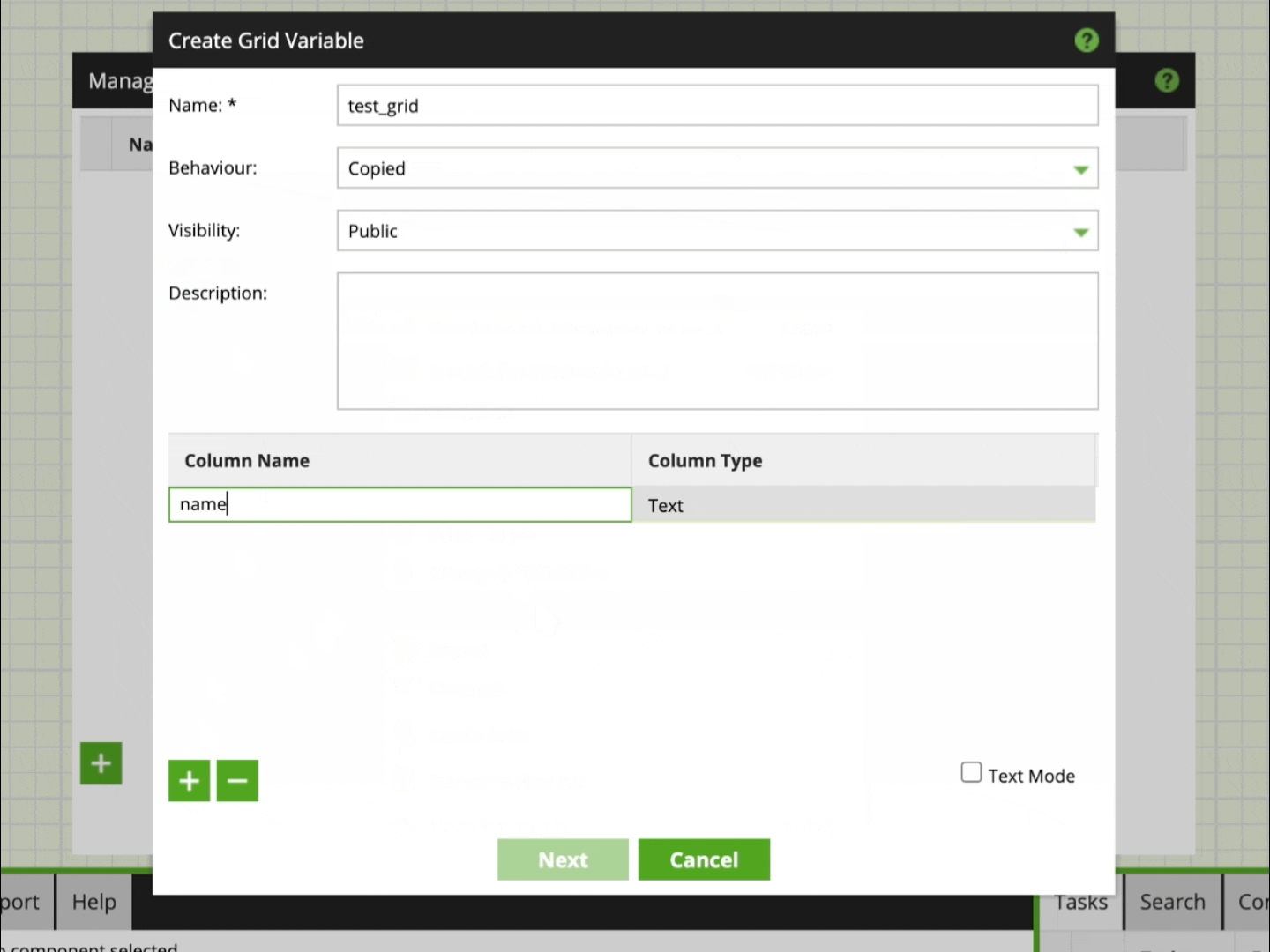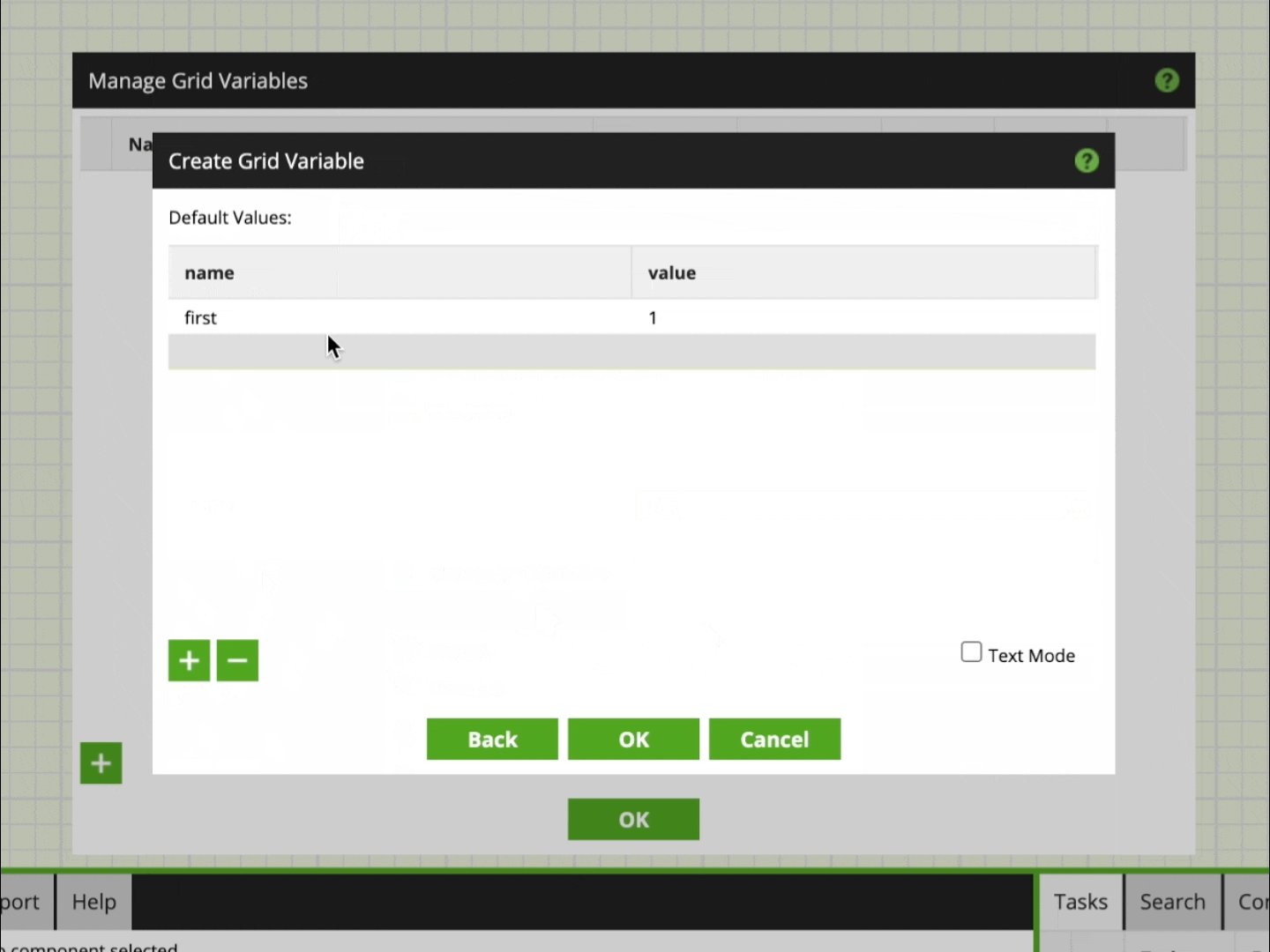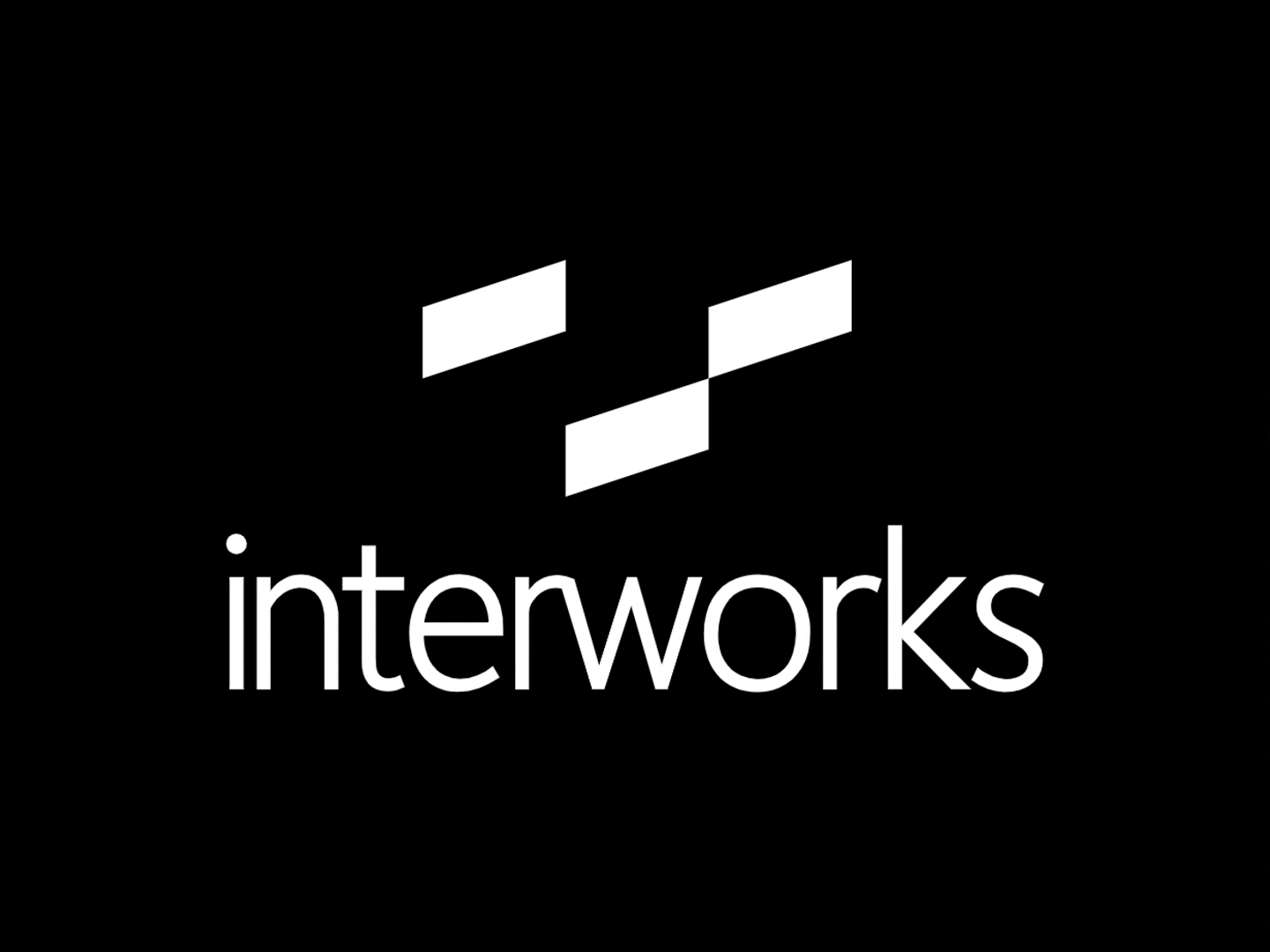
You also might have noticed the little check box labeled Text Mode. Text Mode is a pretty useful feature in which you can switch to a CSV style, tab-delimited view. In this view, instead of adding one variable at a time, you can copy and paste multiple variables in one go.
How to Update Variables in METL
Once a variable is created, it can be updated in many ways, like using the Iterator components. There are different types of iterators available, like the Fixed Iterator or the Loop Iterator. You will provide the variable and it can be updated with every iteration.
In the Python component, you can use context.updateVariable('variable name', 'new value') to update the value of the job variable. For Grid variables, this can be achieved using context.updateGridVariable('<GridName>', <values>) and providing an array as the value. A variable can be retrieved simply by using ${variable name}.
Variables can also be updated by directly storing query results during runtime. For job variables, this could be done with the Query Result To Scalar component, which should return a scalar value. Grid variables can be updated with the Query Result To Grid component, which is equivalent to the previous case but returns an array. Another option is to query and store metadata using the Table Metadata To Grid component.
There are some great blog posts from my colleagues, here at InterWorks, that go into more detail about using some of the mentioned components. There are two posts by Chris Hastie:
- The first one is about How to Reorder the Values of a Matillion Grid Variable, which is done with a Python component and can be useful after loading values with the Query Result To Grid component.
- The second one is about How to Combine Values of a Matillion Grid Variable into a Scalar Variable, where he shows how to use contents of a Grid Variable inside an SQL component.
And please check out Load Multiple Tables into Snowflake with Two Matillion Tools by Scott Perry (Spoiler: He is using an Iterator component).
How to Pass Variables to Other Jobs
Using variables inside of one job is great, but using them in an entire pipeline and passing them from one job to another (and back) is even better. Remember the Private and Public Visibility that was mentioned earlier? Now this will be important. When calling other METL jobs with the Run Orchestration or Run Transformation components, you can define which variables should be provided for the called job. This requires, that the variable is declared as Public and that it is created in both jobs.
But from the beginning: In the Run Orchestration component properties you have the option to Set Scalar Variables and Set Grid Variables. In the respective dialog that opens, you can select any variable that is declared in the called job. For the value that is passed over from the main job, you could either provide just a plain fixed value or — for the purpose of passing a variable — you provide a reference to a variable from the current calling job. To keep track, it is recommended to use the same names for the variable that is passed along:
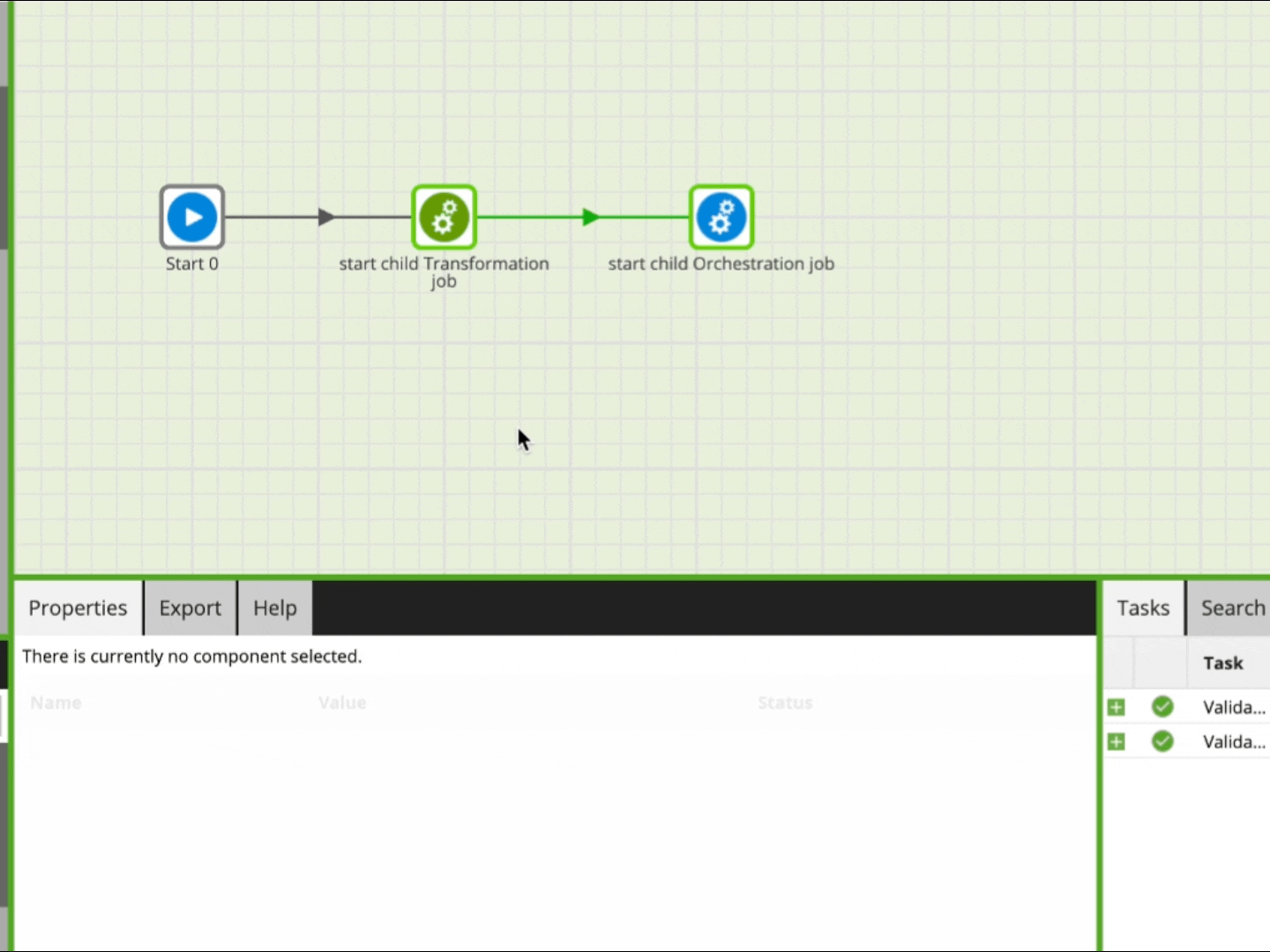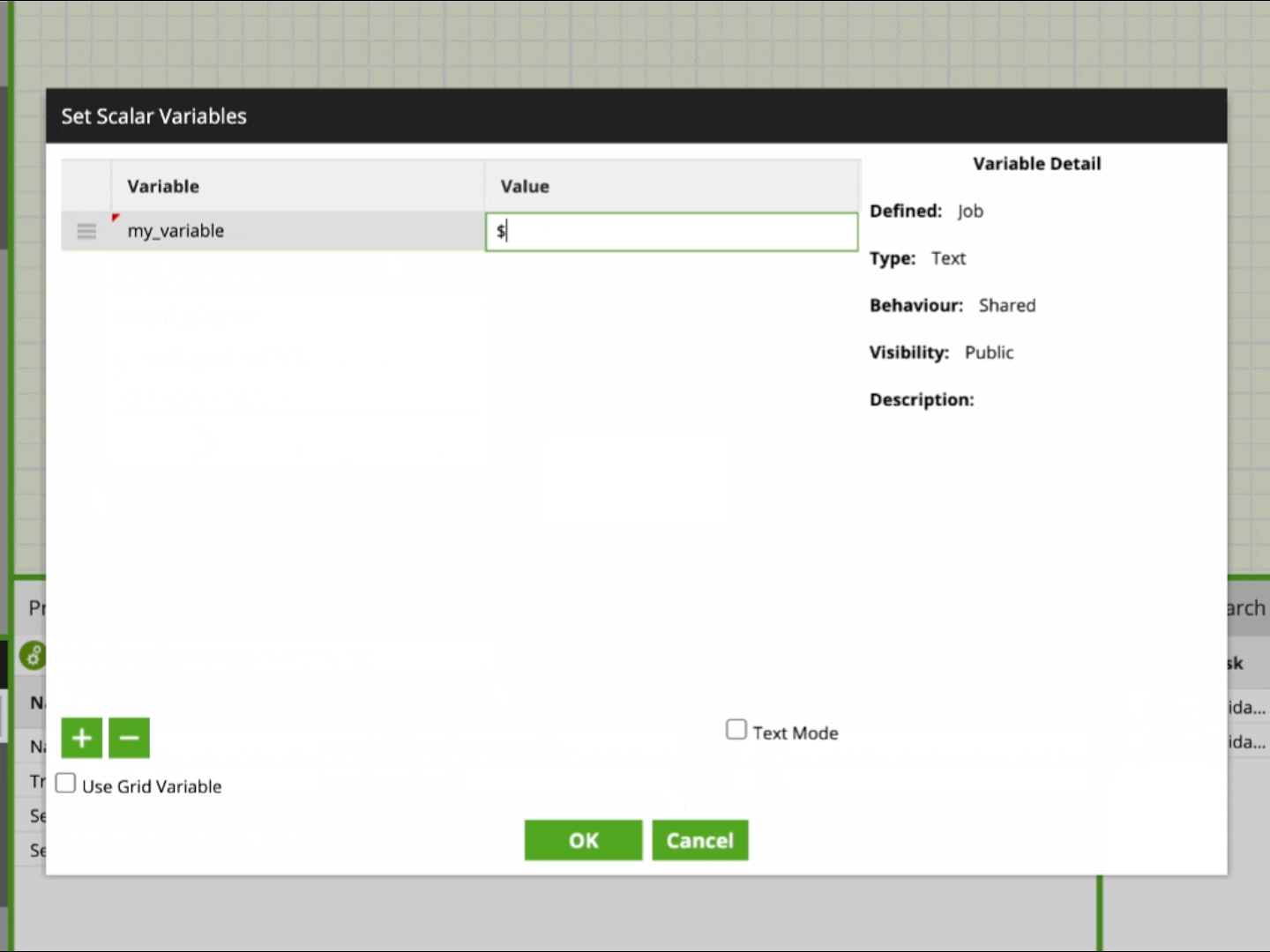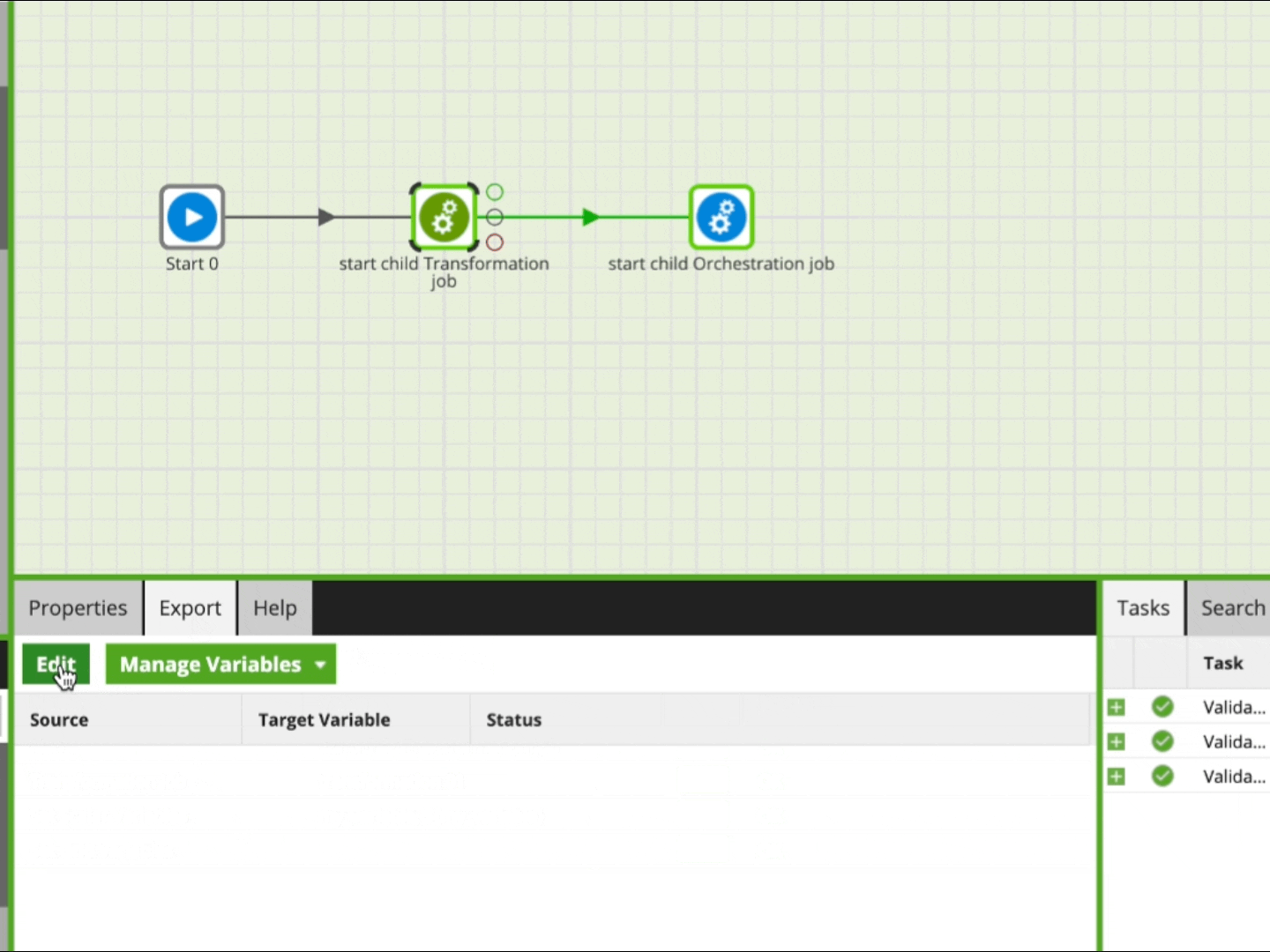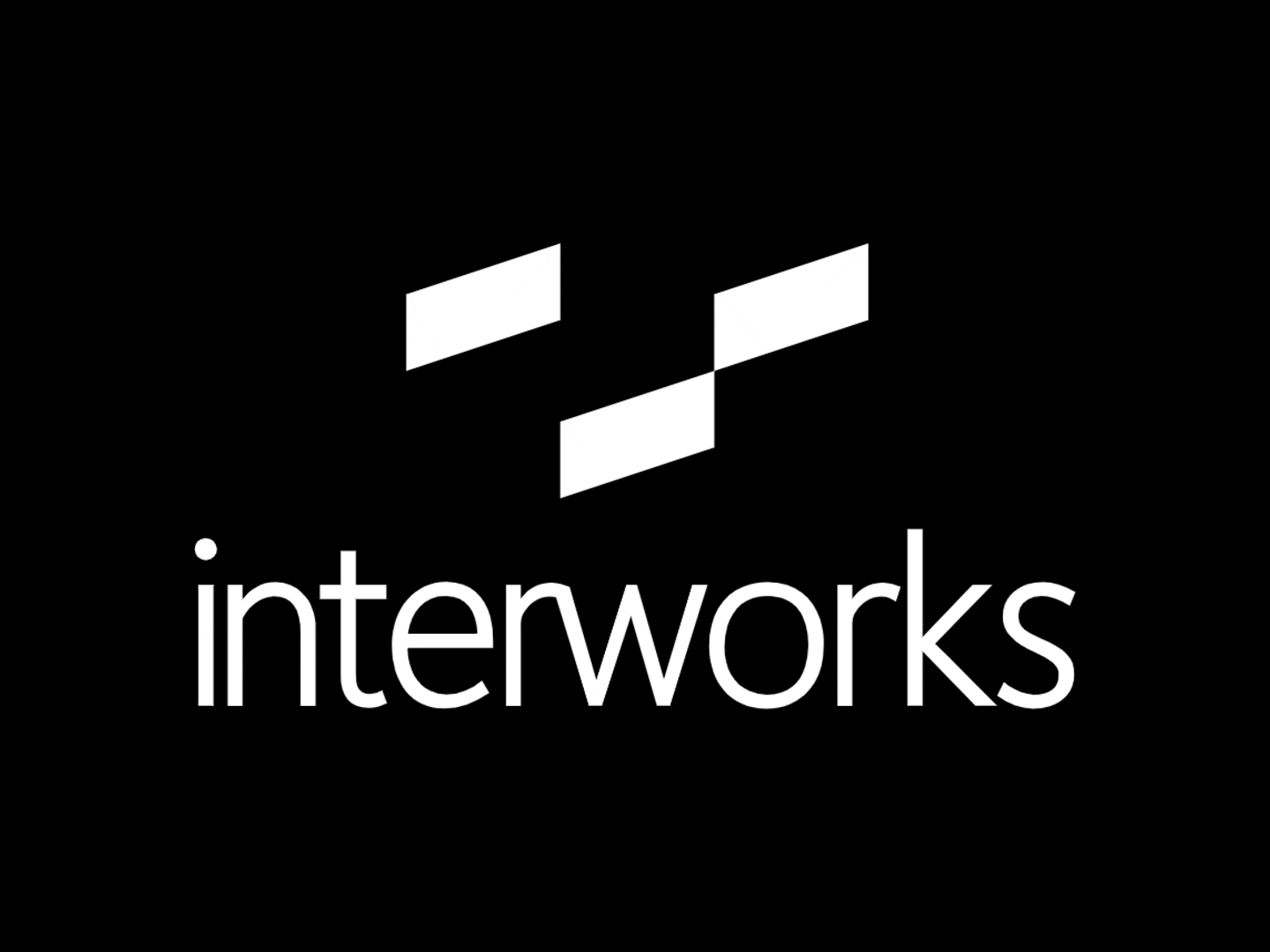
In order to retrieve an updated variable back from a called job, it is important that you declare it in the Export tab in the Properties panel.
This way you can also provide the variable(s) through an entire pipeline, i.e. over multiple jobs, possibly making changes along the way.
Some Special Use Cases for METL Variables
One great way to speed up and simplify your data transformation process is to use grid variables in your various transformation steps. This has the advantage, that you can concentrate all necessary updates and changes to one main job in your pipeline. For example, if a new field needs to be added from your data source, instead of having to document all jobs and components which need to be updated, you can simply define that grid variables x, y and z need to be adjusted in the main job.
You can then pass them over to the jobs that do the magic and don’t have to touch these other jobs in the pipeline at all. Next are some examples from a recent project I worked on.
For column names changes I used the Rename component using a grid variable to provide the necessary Source Column and Target Column.
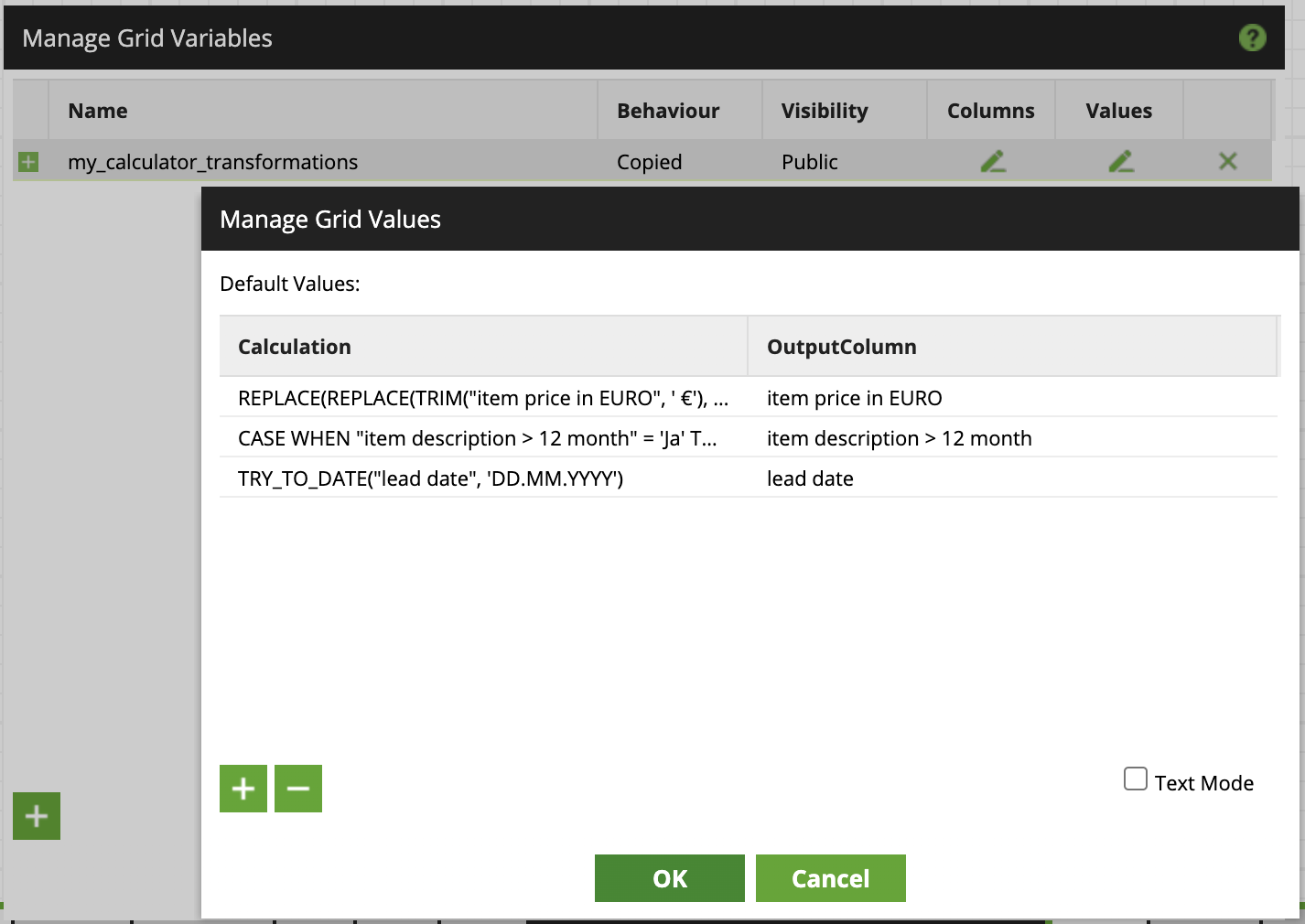
For the various transformations that were necessary I provided a grid variable to the Calculator component. Instead of the complex (and, in my opinion, slightly intimidating) calculator dialog, you can just create a grid variable with two columns, one for the calculation and one for the output column. For calculations, you can use all of the available functions, for example:
- String manipulations like
REPLACE(REPLACE(TRIM("item price in EURO", ' €'), '.', ''), ',', '.')to convert European style currency to a usable number format. - Case statements like
CASE WHEN "item description > 12 month" = 'Ja' THEN 'yes' WHEN "item description > 12 month" = 'Nein' THEN 'no' ELSE 'no' ENDto prepare the value to be converted into a proper Boolean format. - Date calculations like
TRY_TO_DATE("lead date", 'DD.MM.YYYY')to handle different date formats from various sources.
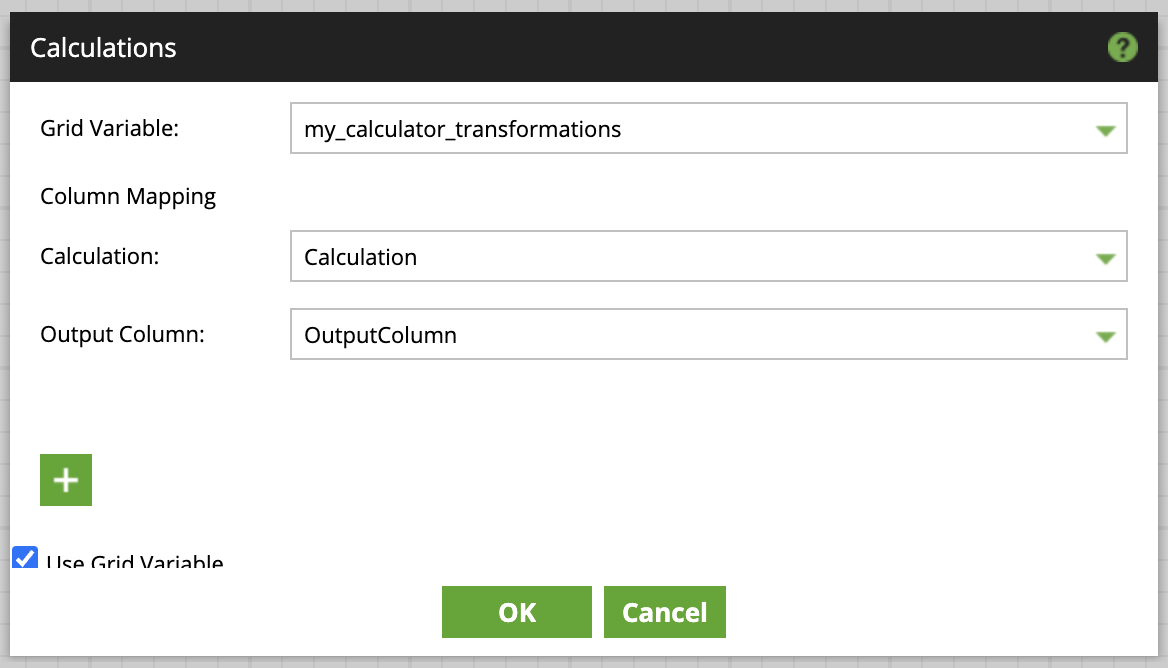
After these transformations I added the Convert Type component to convert all manipulated columns into the correct datatype. That grid variable needs to have columns for Column, Type, Size and Precision.
In the end, we have three grid variables that will be maintained in the main job and are passed through to whichever job that needs them. I was able to easily document all the changes in an external list just by copying the grid variables into an Excel file. This way the current status is also available outside of METL, which I find very useful when the instance is not running 24/7.
There are of course many more use cases like this, Just keep an eye open for that little “Use Grid Variable” toggle.
Wrap Up
I hope this introductory blog was helpful in demystifying those METL variables. And please stay tuned as there might be a blog about how variables are handled in the all new Matillion Data Productivity Cloud coming soon. In the meantime, check out what Fadi Al Rayes has to say about it: Getting SaaSy with Matillion’s Data Productivity Cloud.
If you want to learn more or need help with building or maintaining your pipelines, please reach out to us at InterWorks.