
Recently, I came across a request from a member of the Matillion community to leverage the values of a Matillion grid variable in a SQL Script component. To be more precise, they had populated a grid variable with a list of values and wanted to use an IN statement in a SQL WHERE clause to retrieve any records that matched this grid variable.
Here is the simplified version of the SQL they wished to execute:
SELECT * FROM MY_TABLE WHERE MY_FIELD IN (<MY_GRID_VARIABLE>)
To feed this, we have the following grid variable in Matillion:
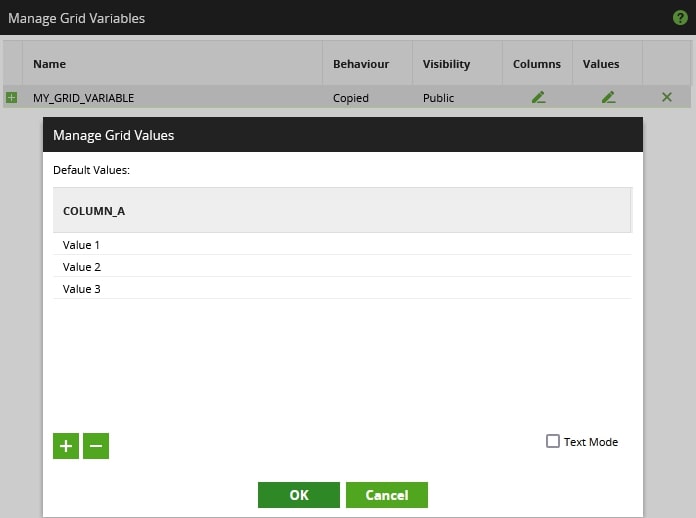
So the end goal would be for our original SQL script to be populated as follows:
SELECT *
FROM MY_TABLE
WHERE MY_FIELD IN ('Value 1', 'Value 2', 'Value 3')
The Solution
To solve this issue, we need to convert the grid variable into a format that can be easily understood by the SQL script. We are not looking to iterate over the grid variable or anything like that; we simply want to take all values of the grid variable and combine them.
The simplest way to achieve this is to create a scalar variable in Matillion and populate it with the concatenated list of values from the grid variable. So, for our example, this new scalar variable needs to contain the following value in a single string:
'Value 1', 'Value 2', 'Value 3'
We can achieve this in a few steps:
- If necessary, create a new orchestration job to perform this variable change and execute the transformation job.
- Create a new scalar variable to store this string value.
- Use a Python component to populate the scalar variable appropriately (the main piece here).
- Update our SQL statement to leverage our new scalar variable.
- If using a transformation job, ensure you update the variables being passed to it by the orchestration job.
Let’s step through these in more detail.
Create the New Orchestration Job
Depending on your current structure, you may need to create a new orchestration job for this. Remember that a SQL SELECT statement can only be executed as part of a transformation job, whilst the Python component and variable manipulation can only occur as part of an orchestration job.
Here is an image of how our final orchestration job may appear by the time we are done with this post:
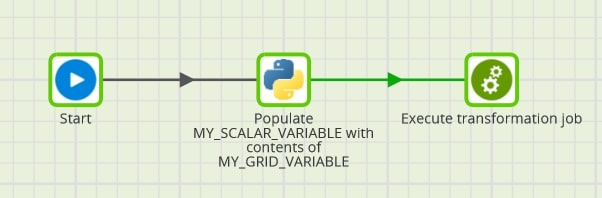
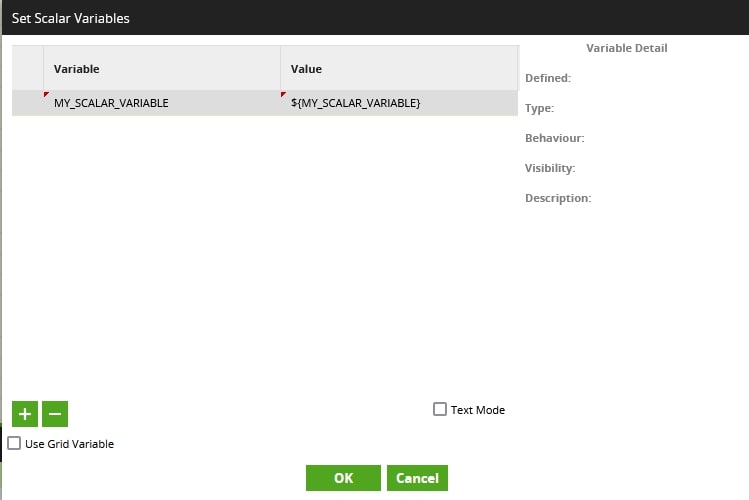
Create New Scalar Variable
This part is simple. We can create a new scalar variable in Matillion by right-clicking on the canvas and selecting Manage job variables:
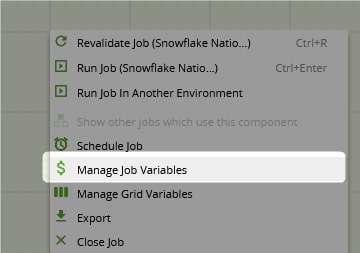
For our example, we call our new variable by the catchy title MY_SCALAR_VARIABLE:

If appropriate, you will need to add this to both your orchestration and your transformation job.
Use Python Component to Populate Scalar Variable
To achieve this, we leverage the following Python script, using Matillion’s Python Script component. This script is mostly comments and not much actual code, so I have not provided any further description outside the comments in the code itself. Remember, this must be part of an orchestration job:
# The purpose of this Python script is to convert a Matillion grid
# variable into a flattened scalar variable, that contains the values
# in the example format below, which matches that required for an
# IN statement in SQL:
# 'Value 1', 'Value 2', 'Value 3', etc
# Define an empty python variable to store the scalar variable value.
# Defining this at the start also ensures an empty value is present to leverage
# if the various IF steps below are not triggered, avoiding errors
py_my_scalar_variable = ''
# Retrieve the contents of the Matillion grid variable and store in a Python variable
py_my_grid_variable = context.getGridVariable('MY_GRID_VARIABLE')
# Print the grid variable for logging:
print('---------------------')
print('MY_GRID_VARIABLE:')
print(py_my_grid_variable)
print('---------------------')
# Only do the rest if the grid variable is not empty, and contains more than 0 values.
# Otherwise the default, empty value of py_my_scalar_variable will persist
if py_my_grid_variable is not None:
if len(py_my_grid_variable) > 0 :
## Matillion grid variables are lists of lists.
## Since we only want the data in the first column of the grid variable,
## we leverage a concept known as "list comprehension" to unpack our
## variable value into a standard list, only retrieving the first column.
## Remember that in Python, counting starts at 0, not 1.
py_unpacked_grid_variable = [x[0] for x in py_my_grid_variable]
## Flatten our unpacked grid variable into a single string, including
## quotes that indicate string values in SQL.
py_my_scalar_variable = "'" + "', '".join(py_unpacked_grid_variable) + "'"
# Update the Matillion scalar variable with the contents of the Python variable
context.updateVariable('MY_SCALAR_VARIABLE', py_my_scalar_variable)
# Print the scalar variable for logging:
print('---------------------')
print('MY_SCALAR_VARIABLE:')
print(MY_SCALAR_VARIABLE)
print('---------------------')
Update Our SQL Statement
Finally, we update our SQL Script component to leverage our new scalar variable:
SELECT *
FROM MY_TABLE
WHERE MY_FIELD IN (${MY_SCALAR_VARIABLE})
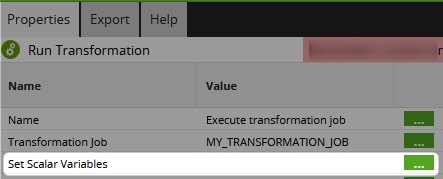
If a Transformation Job, Update the Variables
Our example SQL code will not run as part of an orchestration job, as SELECT statements are only allowed in transformation jobs. So if you are trying to use this method in a transformation job, you will need to add the extra step to pass the scalar variable to the transformation job when executing it via the orchestration job:
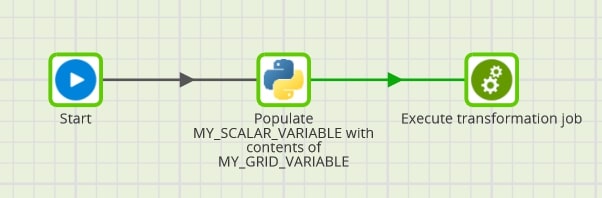
Full Flow
Combining the above steps results in the following simplified Matillion flow:
I hope you’ve found this useful. Let me know if you find any creative or interesting uses for this approach.