
A common scenario that people encounter is that people need to move one object in a S3 bucket to a different bucket. Recently, I encountered a data vendor that sent data directly to a customers bucket. The customers data pipeline was set up to access a different bucket, not accessible to the outside data vendor, within their AWS environment.
Every time we want to move the data landing in the bucket accessible to the vendor to the bucket accessible by our data pipeline, we can use a Lambda function. Lambda functions are great for this scenario because we can spin up an unlimited number of serverless functions and they will be completed within seconds. Setting up this process does not have to be a cumbersome one. Below are the steps to set up this function in your environment!
To start off, select the region you want to create the function in. Remember, each function is hosted in it’s own region.
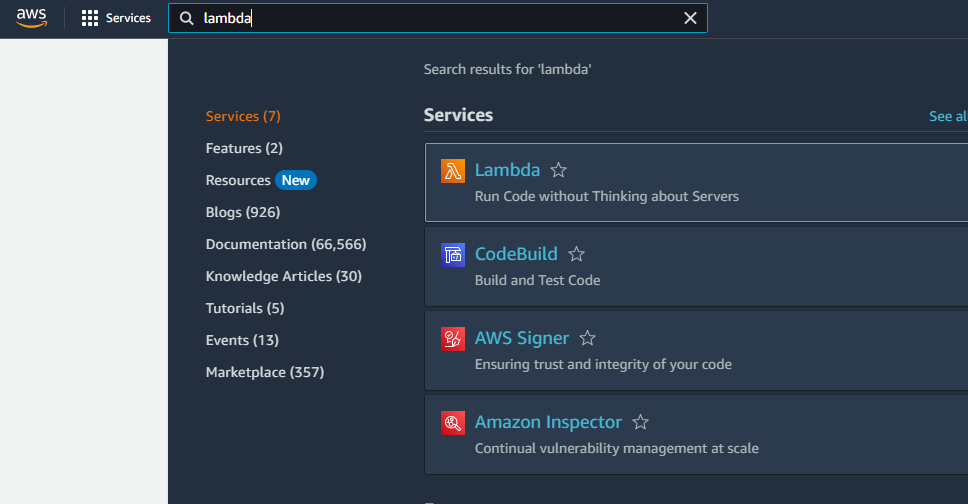
After selecting the region, search for Lambda in the search bar at the top of the screen of your homepage.
Once you have landed on the lambda homepage. Choose Create Function at the top-right corner of the page.
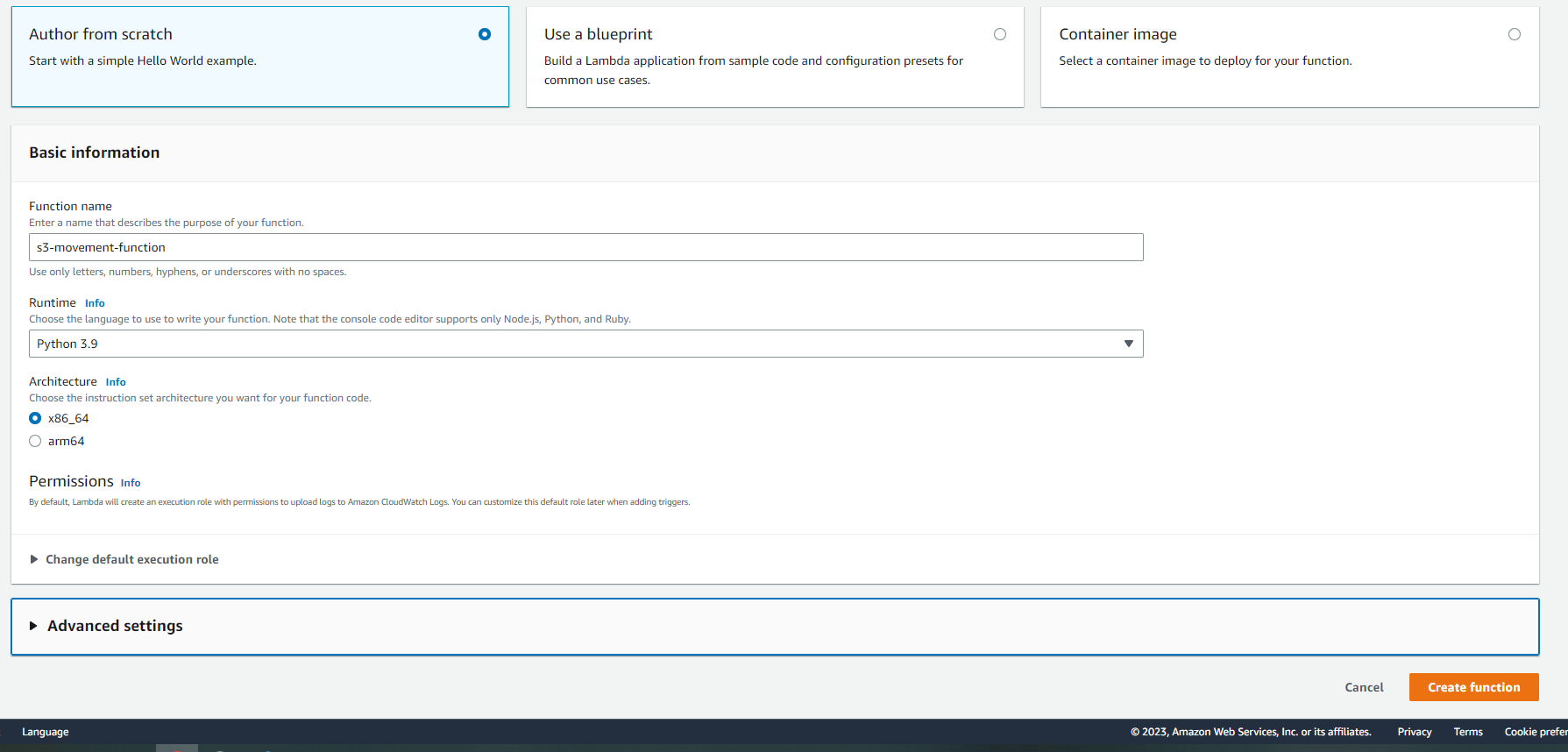
Lambda offers the ability to use blueprints or create functions from a container. Today, I am going to create a function from scratch. First, select Author from Scratch. We will then name our function s3-object-movement and choose the runtime.
For this example, I will be using Python 3.9 because that is the language I am used to working in and has native packages to easily move data between buckets. After selecting these two options, choose Create Function. No need to change any of the Advanced Settings or define a specific role, but those are features to consider depending on your organization’s policies.
We will insert the section of code into the code source window:
import json
import boto3
import os
s3_client = boto3.client('s3')
def lambda_handler(event, context):
for record in event['Records']:
source_bucket = record['s3']['bucket']['name']
destination_bucket = 'my-destination-bucket'
s3_key = record['s3']['object']['key']
s3_client.copy_object(
Bucket=destination_bucket
, CopySource=f'{source_bucket}/{s3_key}'
, Key=s3_key
)
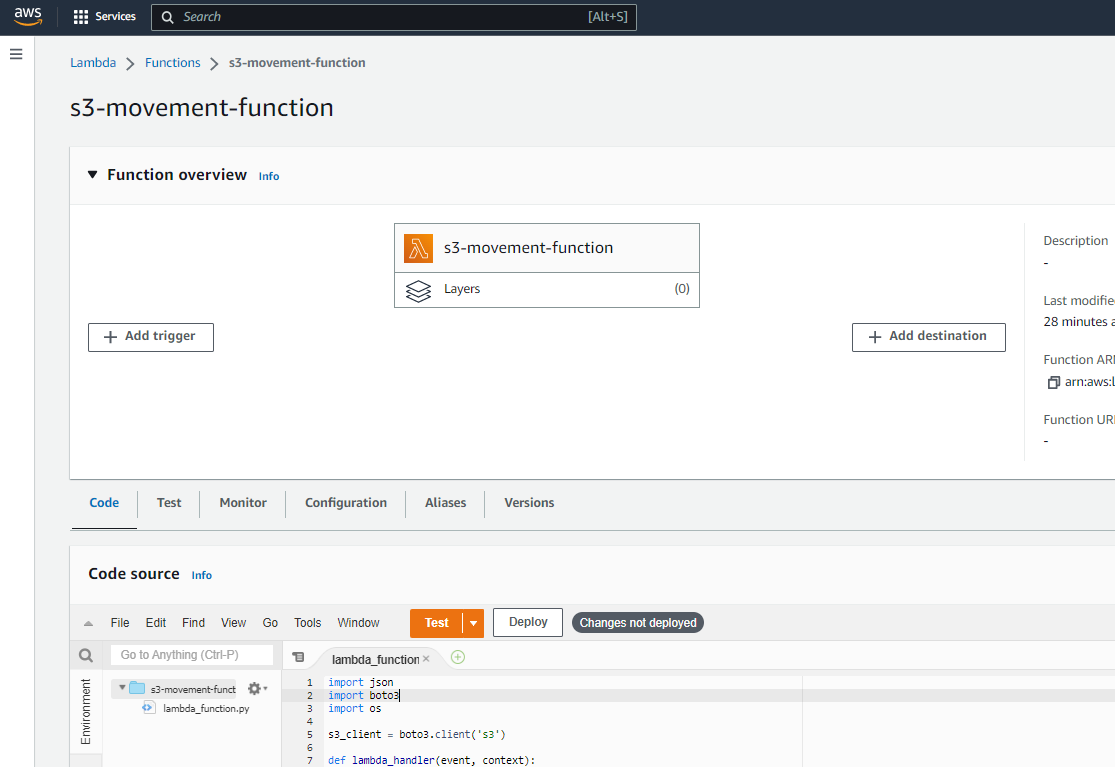
This function is a simple function to move the data from one bucket to another based on an event. An event is created by a trigger, which we will create in the next step by selecting Add Trigger.
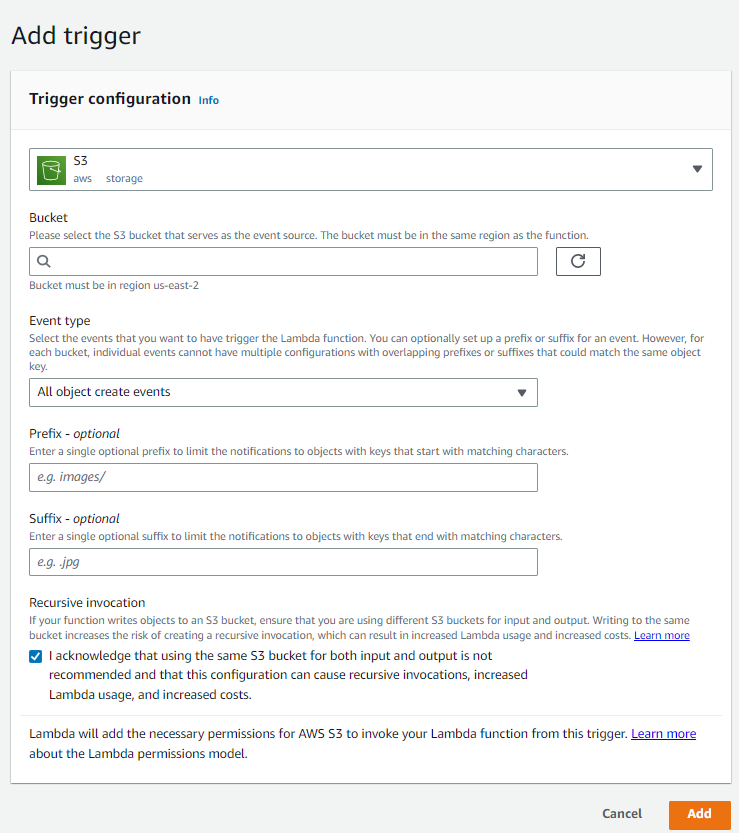
In the trigger configuration, we will fill out the following fields:
- S3 as our source
- Bucket – The source bucket which the data will initially land
- Event Type – All object create events
- Prefix/Suffix – To filter for the specific grouping of objects we wish to move between buckets
- Select Add to add your trigger
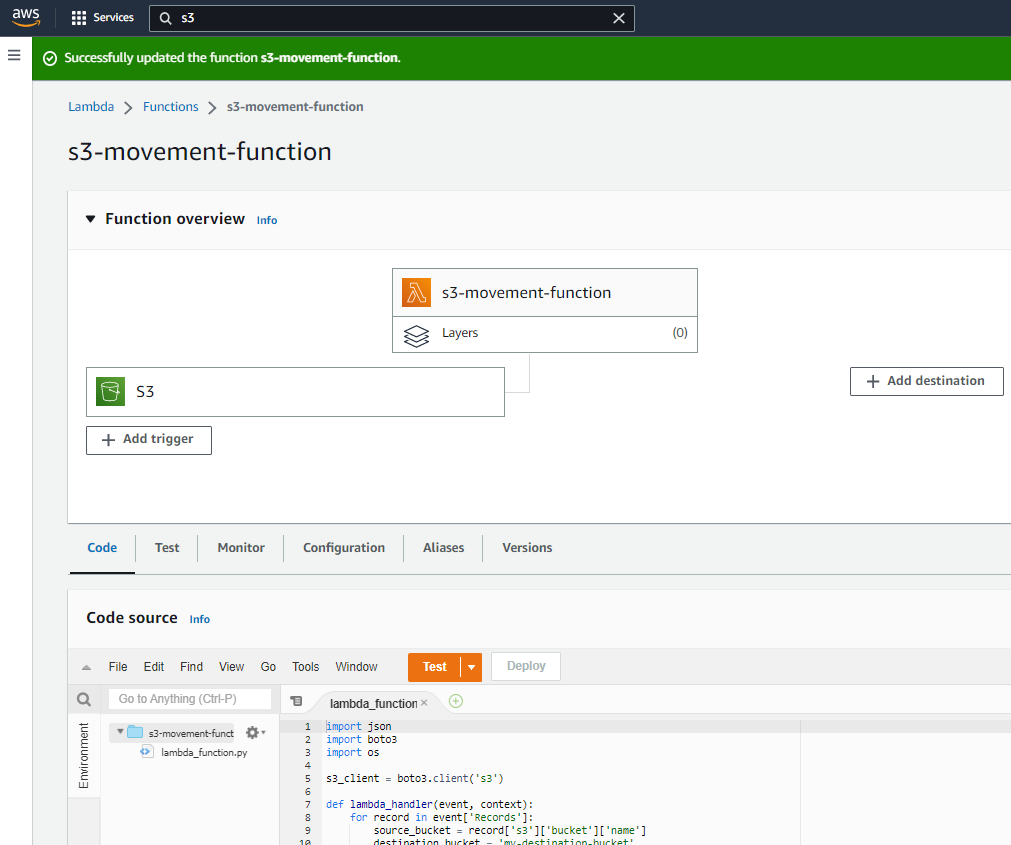
Once this has been completed, you will be directed back to your original window and your Lambda function is now live! If you are having difficulties setting this up within your environment, please reach out and I can help you walk through the setup.
Outside of this use case, AWS lambda has numerous other use cases in your data pipeline including setting up a custom connector in Fivetran or creating an external function in Snowflake.