
I rarely ever receive pristine data, and I’d wager that’s true for most of us working in data analysis or business intelligence. Data can come to us from dozens—if not hundreds—of sources, and it certainly requires some preparation to make it useful. One of the most common data preparation tasks is to combine columns from multiple tables — a process called “joining.”
There are several tools that can help us join data together, but I want to focus on the theory of joins in this blog post. This won’t be a how-to kind of post but rather a quick explanation of the different ways we can join data and some of their effects. Let’s dig into it.
What Is a Join?
A join is a process that combines tables from one data source (like tables in SQL or sheets in an Excel spreadsheet). Imagine we have the two tables below: one table, on the left, shows the top 10 movies of 2017 sorted by domestic gross, along with their opening dates. The second table, on the right, lists movies that I watched during 2017, along with my personal rating from 1-10.
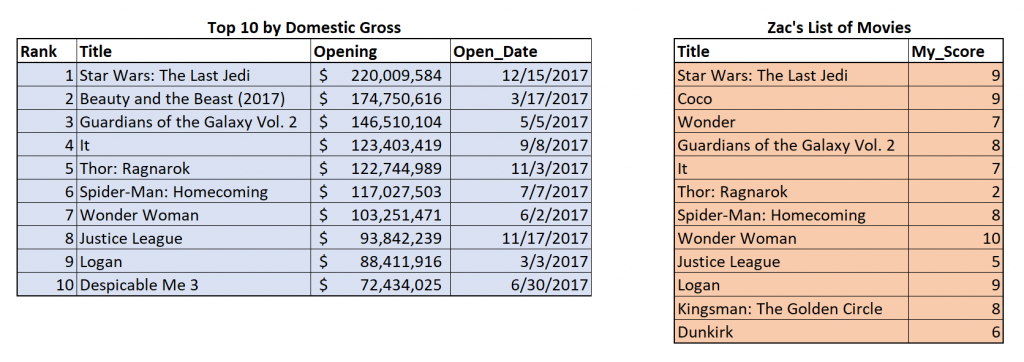
If I wanted to analyze all of this information together, I’d have to figure out some way to combine these tables, and that’s exactly what a join will do. When we join these two tables, we will merge their columns together into one new table. We’ll need a unique identifier for every single row. In this case, that will be the movie title. This is called our join key, and we’ll use it to put the data in the correct location. But there are a few different ways we can choose which rows make it into the final table, so we’ll need to understand the four different join types.
Inner Join
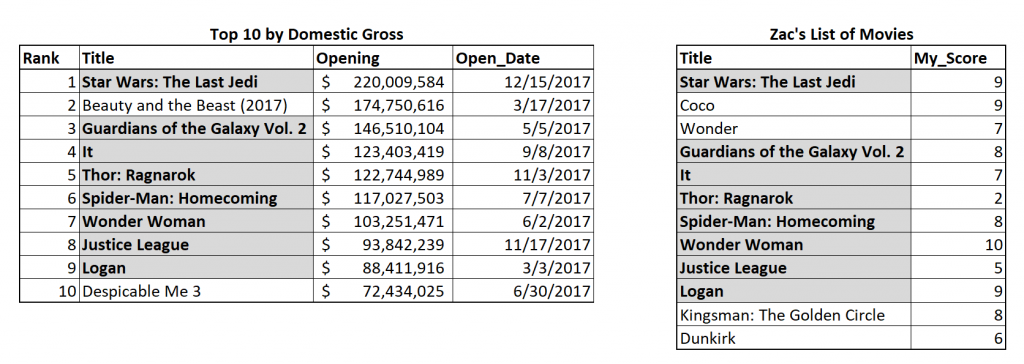
The first join type we’ll consider is the inner join. This process retrieves only the rows that are common to both tables. Below, I’ve highlighted those rows in gray. We can see that “Beauty and the Beast (2017)” is in the left table but not in my list of movies on the right. Similarly, “Coco” and “Wonder” are in my list of movies but not in the top 10 by domestic gross.
The result of the inner join is the table below. The blue columns came from the left table, Top 10 by Domestic Gross, and the orange column came from the right table, Zac’s List of Movies. Note that the only movies in the result set are those that I saw and rated in 2017 yet also in the top 10 table.
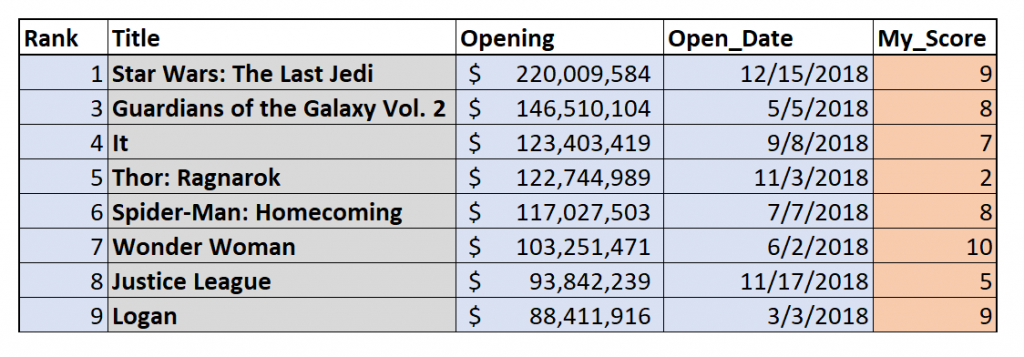
This has effectively filtered our resultant table; it only returned the top 10 movies if I had seen and rated them, and it only returned movies I had seen if they also grossed highly.
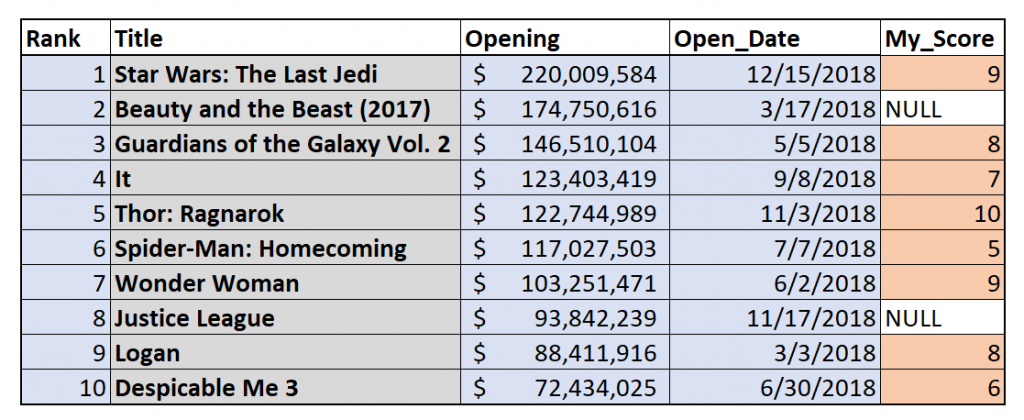
Left Join
We may want to return some rows regardless of their existence in the other table, and the left join can help us do that.
The left join treats one table—the left table—as the primary dataset for the join. This means that every row from the left table will be in the result set, even if there’s no rating from the right table. Below, I’ve highlighted the rows that the left join will return.
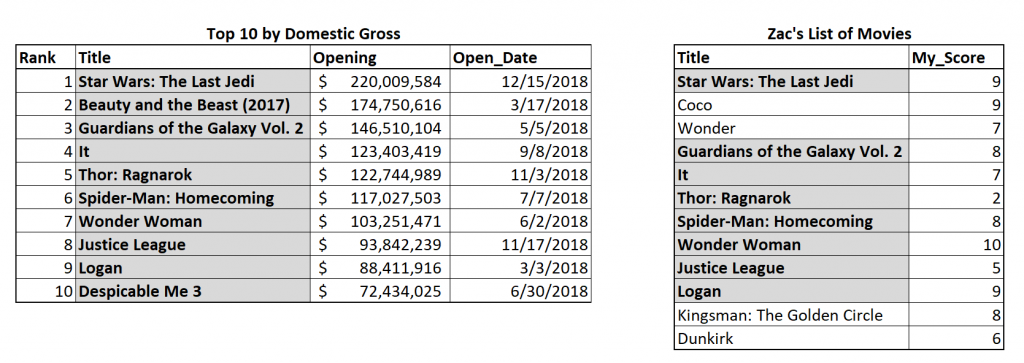
But what about those movies that don’t have a rating? What will go in the My_Score column for “Beauty and the Beast (2017)” or “Despicable Me 3?” Since there is no data to put in the table at those spots, the join will simply put NULL values there. We can see this in the result set below.
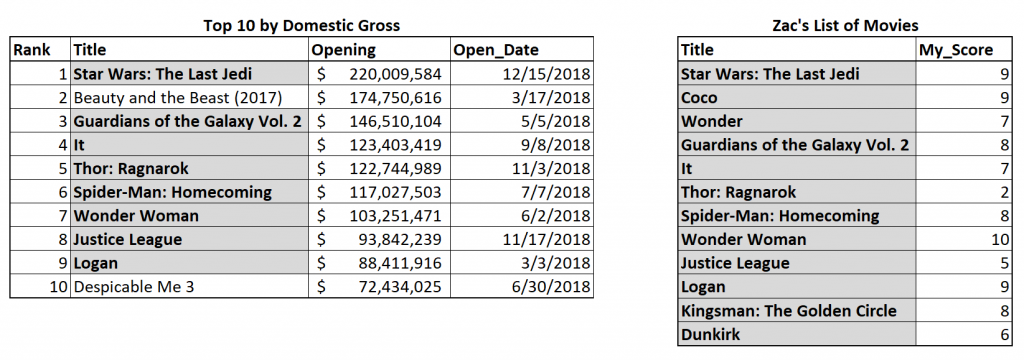
Right Join
The right join is conceptually very similar to the left join, but it treats the table on the right as the primary dataset. This means that every row from the right table will be shown in the result set, but “Beauty and the Beast (2017)” and “Despicable Me 3” will be filtered out. So, the highlighted rows below will make it to our result set.
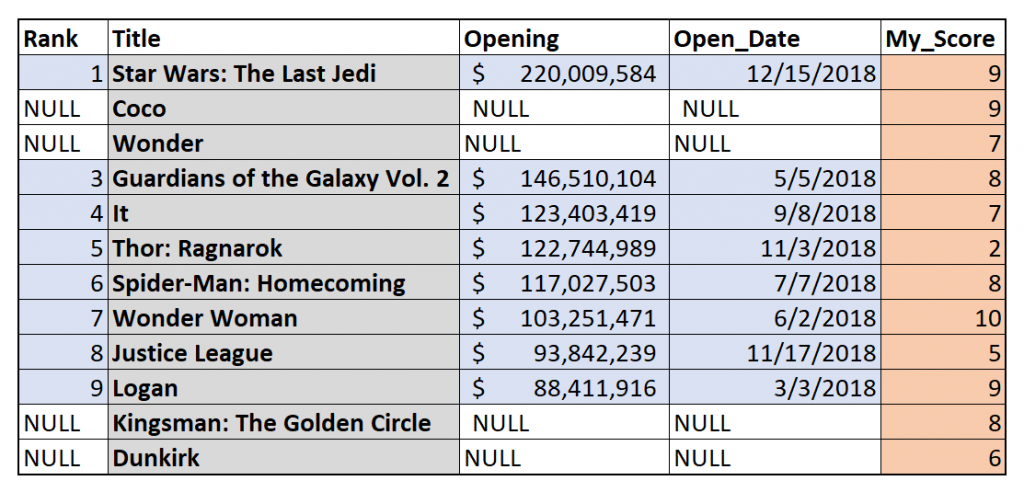
In the resulting table, we can see that “Coco,” “Wonder,” “Kingsman: The Golden Circle” and “Dunkirk” are present in the rows, but several of their columns have been filled with NULL values since there was no data for those movies in the left table.
Outer Join
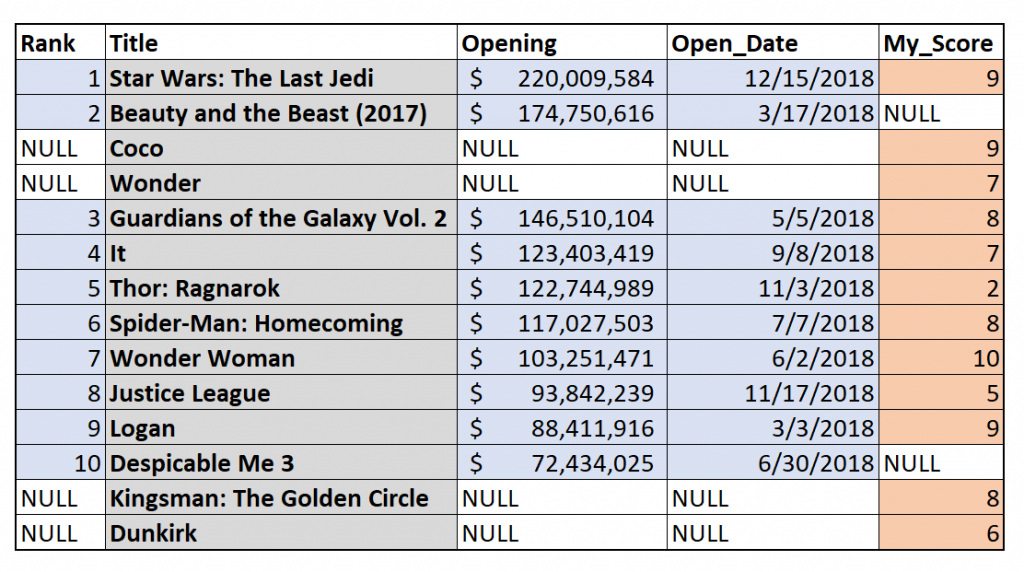
The final join type is the broadest and NULL-iest: the outer join. This process keeps rows from both tables and fills in NULL values where necessary. Any movie in the top 10 domestic gross table will make it into the result. Likewise, any movie in my personal table will make the cut. Below, we see that every row is highlighted gray.
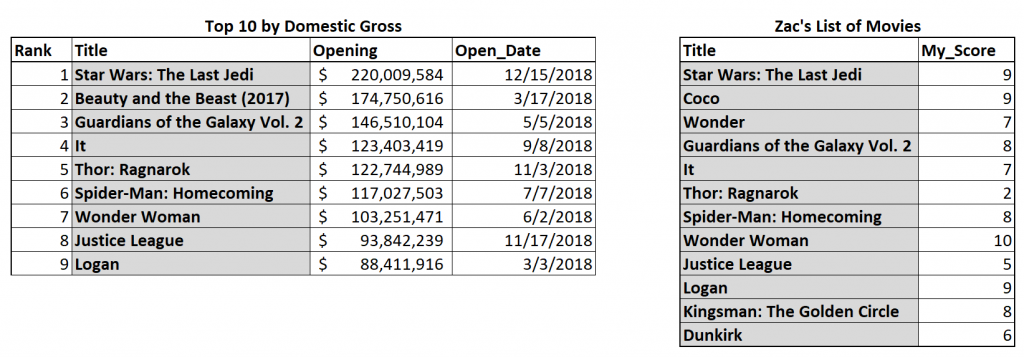
When we perform the join operation, we get every single movie, as well as NULL values wherever there is missing data.
So, joins let us combine columns from multiple tables, but it’s important to remember the effects that the join type can have. Inner, left and right joins will filter your data and reduce your result set. Outer joins will include every row but have the potential to include a lot of NULL values. As always, thinking about your goals and choosing the right tool for the job will lead to the best results.