
Late last year, I wrote a white paper that identified what the biggest pain points were for data and analytic leaders. The information was based on a multi-industry survey conducted across hundreds of clients, which provided insight on the main problems. From there, we took the time to formulate potential solutions rooted in decades of expertise to figure out how we can best help you navigate these complications. The first (and most common) pain point we’ll cover is data governance.
Foundational Concepts
With a term like data governance, we’re going to have to spend a little time on definitions. It’s a very broad term and will mean different things to different people or different contexts. What is data governance to an analyst working inside of a Tableau data extract vs. an enterprise architect building a multi-cloud strategy?
The good news is that the foundational precepts are the same. Data governance is the process of creating and managing data that is available, usable, trustworthy, secure and compliant throughout the data lifecycle.
Here’s a great example of an easily digested data lifecycle:
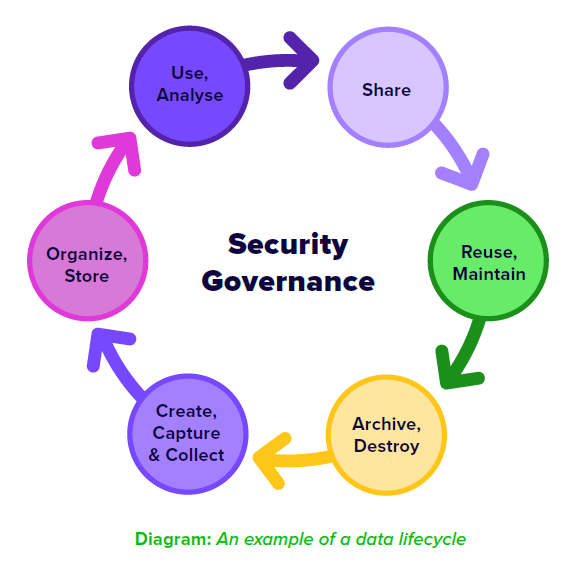
The Problem
Now that we have a basic, shared definition, let’s examine the problem as identified by our survey respondents. A confluence of factors has put ever greater pressure on data governance at a rate that has – so far – sprinted past reasonable capabilities of governing.
For example, our survey respondents identified the following problems:
- The explosion of data creation from the web, apps, IoT and the like
- The self-service trend and subsequent decentralisation of analytics that has made every businessperson into a data consumer
- The diversity of data sources and their unique needs for connection, integration, orchestration and more
- The increasing expectations of regulators and customers on data privacy and security against ever-present threats of malicious actors or potential risks from generative AI
- The proliferation and monitoring of downstream applications for data, such as reporting, analytics, data science, data apps, AI, etc.
It’s a lot for an already overburdened data team to consider. To put this into further perspective, let’s quantify these challenges with some hard facts.
According to IDG Research (2022), the average company uses over 400 different data sources. This could be your enterprise data warehouse all the way down to Marge from Accounting and her desktop Excel spreadsheet.
With ever more advanced data platforms, those data sources are going to include unstructured data, as well. We’re talking about scans, PDFs, images, video, audio and more. Nearly every infrastructure component within an organisation produces a stream of data, whether it’s monitoring the usage of engine parts or perhaps the gantries on a toll road. Maybe it’s the mouse movement and click patterns of every single person that has come to your online store.
Industry experts predict that the annual volumes of data creation will reach 200 zettabytes by 2026. What’s a zettabyte you might ask? It’s a trillion gigabytes. That’s an incomprehensible scale. Let’s try to humanise that number. A single HD movie is on average about 3 GB. If we took all the movies ever made – 500,000 of them since 1888 – that’s still only a fraction of a percent of a single ZB. It’s a literal explosion of data.
If the entire sum of data from the history of the human race could fit into a single book, that book would be duplicated with new data in just over two years. InterWorks Asia Pacific incorporated in 2018 and data volumes since that date have already multiple by +500%.
Within these sleeping stacks of data in your data lake could be treasures to unlock massive opportunities for market differentiation, competitive advantage or customer insights. At the same time, there could also be a slew of landmines of data that should be discarded or protected.
The sheer avalanche of information makes that a critical challenge particularly when amplified across a matrix of different users and use cases seeking to leverage that resource for data solutions.
When you weigh in all the factors, no wonder its data governance above all that’s causing sleepless nights for data and analytics professionals.
The Solution
Solving this complex problem requires a multi-faceted solution. I would start with defining data governance policies with the centre of excellence, bolstered by legal / compliance stakeholders. These are business decisions on some critical elements that your processes and technology can then automate downstream. But governance starts here, with people.
Some core concepts that should be explored and documented are:
- How and where are we collecting data?
- Where is that data stored?
- What type of data are we collecting? Pay particular attention to Personally Identifiable Information (PII)
- Who is responsible for these data sources?
- What are downstream dependencies on these data sources by use case?
- How are we going to socialise and continually reinforce our data governance policy to our end users?
- How will our users discover the data they need?
- How will we ensure a high standard of data quality and consistent business logic?
- What are our data quality controls, particularly when it comes to training AI models?
There’s a lot more ground to cover, but these bullets will get you deep into a robust discussion that will lead into the right topics. Remember also that a data governance policy is an evolving document that will necessarily change as your circumstances change, whether that be new technologies and their expanding array of features, how your end users will consume data in new ways, or new regulatory or compliance obligations.
Platforms
Let’s get into the technology now. First, a lot of your data governance risk can be mitigated with a carefully considered permissions structure for your users. Who can access these fields or these tables or these dashboards? Raw, unmodelled data like what you might find in your data lake or lake house should be accessible to your most competent data champions. Here is where you’ll find value in experimentation. The typical business user though should only see the most curated reports and dashboards as prepared by your centralised BI team.
It’s a careful balance between data security and integrity vs. innovation and collaboration.
To simplify creating and managing permissions, as a general rule, I recommend creating persona-based roles and organisational structures (like folders and projects for example) then assigning broad permissions on these. Avoid individual rules as much as you can, such as an asset-by-asset basis or by the individual. These get complicated quickly and can create a logical labyrinth where they intersect in contradictory ways. And then document these outside of the application for reference.
Unified Data
Centralising your data into a consolidated data platform is a great first step. There is tremendous value in doing this far beyond data governance, but let’s focus our answers within this question. Consolidate your data into a centralised data lake for storage. Cloud storage is quite affordable and getting even cheaper. Then, on a use case by use case basis, surface curated data feeds into a data warehouse.
These use cases could be specific reporting interests, self-service analytics, data science and more. Investing your highly skilled technical resources into building and expanding your curated data sources in partnership with business experts is the best way to amplify your ROI. It will lower the barrier for the rest of the organisation to start solving problems with data. Avoid at all costs having your technical resources falling to a centralised dashboard development methodology or the infamous report factory.
As your use cases are solved and centralised in your data warehouse, you will have an ever-expanding single source of truth. This is the easiest way to govern, and though it does take time to get there, it is well worth the investment.
The Role of AI
I’ve saved the best news for last. Since generative AI is one of the governance risks that cause so much consternation, it’s only fair that we wrangle this technology to help us find the solution. AI is impacting every tool in the data and analytics ecosystem in new and exciting ways, but I’m most interested in how its unveiling value in data governance, quality and master data management.
Prior to AI, data governance could very easily slip into the grains of sand approach where individual fields had to be considered across multiple tables and data sources by a human resource. It’s a tedious march through a never-ending cycle of qualify, classify and review ad infinitum. With generative AI, governance tools can now do this minutia with trainable intuition at CPU scale and speed.
The next generation of data governance tools (3.0) will have automatic ingestion, quality detection, curation and correction, integration into related data, chatbot style user interfaces and cataloguing. It sounds almost too good to be true, but these features are already present in various stages of maturity in the market leaders today – Informatica, Atlan, Alation, Collibra, etc.
Summary
Spend the mental energy to define what data governance means to your organisation with the domains of security, privacy, quality, retention, accessibility and risk. Evangelise this to your organisation frequently and thoroughly. Finally, do as much as you can within your tools to automate data governance via permissions, centralisation and AI-augmentation
Want to Learn More?
Find this information helpful? There are more blogs to come with more information on other pain points and the best solutions to ease the pain. We started with data governance, but stay tuned to see what the next biggest pain point is or read more in the full white paper.
Know your challenges but don’t know where to start in solving them? Reach out to our team, and we can help you figure out the best solutions for your needs.