
Ever found yourself stuck in development limbo, waiting for a job to finish, only to realize you might need to tweak it again? It’s one of the less enjoyable parts of being a data engineer. But what if I told you there’s a way to speed things up and make your life easier? The answer is simple: run your tasks concurrently. I know you know, but did you know this is possible in Matillion Data Productivity Cloud? Let’s explore how you can achieve this and discover the benefits it brings!
What is Matillion’s Data Productivity Cloud?
In a previous blog post, I highlighted that Matillion DPC is a cloud-based product offered as a service, eliminating the need to manage virtual machines or staging space, and accessible entirely through a web browser. The Data Productivity Cloud combines data loading and data transformation capabilities into one robust platform. It supports unlimited users, projects and environments, providing unlimited scalability with Matillion-managed or user-managed agents.
It features intuitive access control, allowing permissions to be granted to projects by assigning users to one of three roles: read-only, user or admin. This flexibility promotes effective collaboration, enabling team members to share resources and work efficiently together using Git, which is crucial for version control and collaborative teamwork.
Matillion DPC is designed to be user-friendly, yet offers a wide range of capabilities, significantly reducing the need for multiple tools to meet business requirements. By focusing on one comprehensive tool, data engineers can save time, reduce costs and enhance the overall efficiency of data management processes.
For more information on Matillion DPC, check out our blog series on the topic.
What are the Benefits of Concurrency?
Any jobs that use multiple threads can take advantage of the scaling capability of Matillion-managed or user-managed agents. By leveraging Concurrency, you can observe a reduction in total job execution time. This can be highly advantageous in situations where:
- A single task tries to execute numerous subtasks — for example, when using iterators.
- Multiple tasks are being run on the same agent simultaneously — such as when various schedules initiate at 6AM.
How Does it Look Like?
At InterWorks, we have tested the concurrency capabilities of Matillion DPC by simulating a real-world data engineering scenario: loading tables from a database into Snowflake. This test is comprehensive, utilizing a wide variety of components.
Our primary job is divided into two orchestration sub-jobs:
- Metadata Management
- Data Load
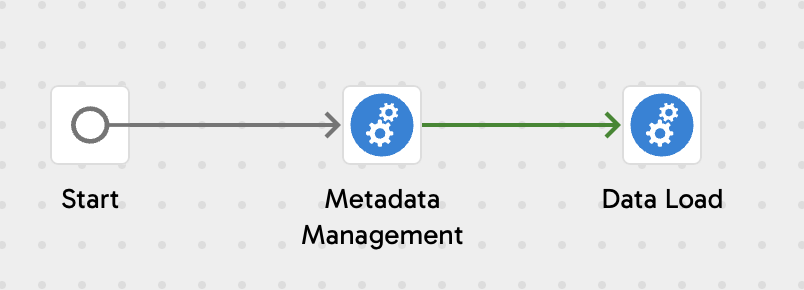
Metadata Management
This job creates a schema and a metadata table if they do not already exist. It extracts metadata from the source database (PostgreSQL) and inserts this metadata into the newly created metadata table. The “Metadata Merge” transformation job ensures that an existing metadata table is not dropped, if appropriate.

Data Load
This job also creates a schema if it does not already exist. It reads table names from the metadata table and saves them to a Grid Variable. It then sorts the table names (optional but nice to have) and uses a Grid Iterator to call Import Single Table, passing the table name.
The Import Single Table job, created by InterWorks, covers many use cases. It checks if a table already exists and if it can be loaded incrementally. If it can, the job extracts the incremental columns and generates the incremental query. If not, it generates a full load query. In both cases, the generated query triggers the data load for that table. Importantly, the grid variable passing the table name can be configured to run either concurrently or sequentially.
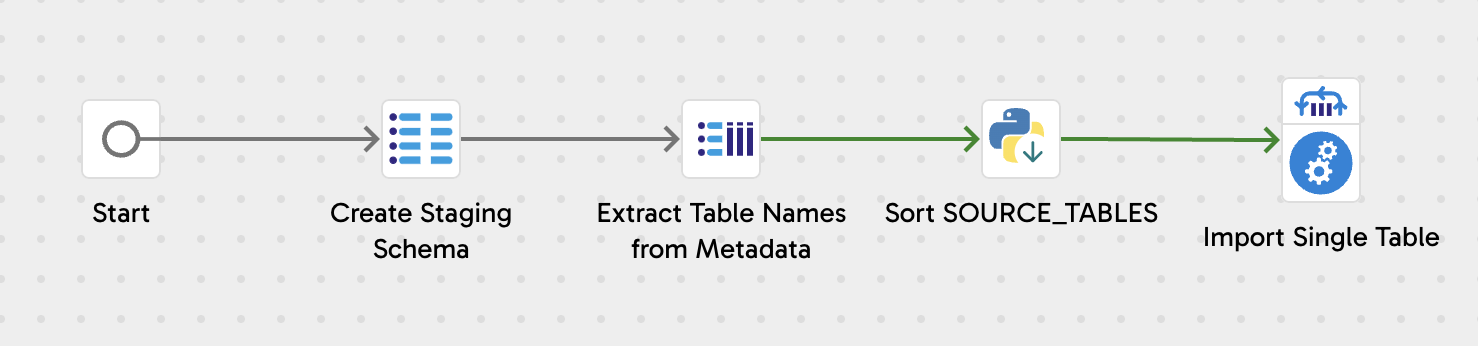
Testing Procedure
For our tests, we used a Python script to generate tables containing 20 columns of various data types and 100 rows each. These tables were loaded into a PostgreSQL database, with three different table counts being tested: 10, 100 and 1000. Before each measurement, the schemas for the metadata and the tables were dropped.
The results of our tests are represented in the following chart:
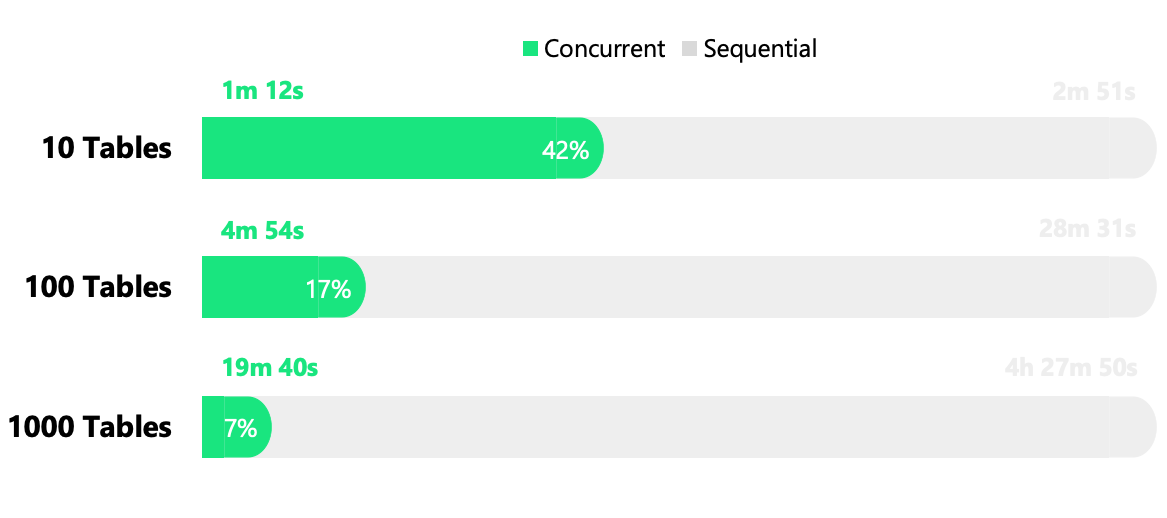
There’s a noticeable 58% decrease in total runtime when processing 10 tables. This performance enhancement becomes even more apparent as the number of processed tables rises, reaching an impressive 93% with 1000 tables.
Wrap Up
The concurrency capabilities of Matillion DPC demonstrate impressive performance, particularly when executing multiple subtasks simultaneously, which significantly reduces runtime. This efficiency is not limited to grid variables but extends to all iterators available in Matillion DPC. Additionally, Matillion DPC will execute jobs concurrently if they are scheduled at the same time, making it a comprehensive SaaS tool for data loading and transformation. Matillion DPC is an invaluable asset for your data engineering tasks, enhancing both speed and efficiency.