
Building on top of my initial post about Matillion’s API Profile functionality, I have discovered some new information I just had to share with the kind readers of the InterWorks blog. In my original post about Matillion’s API functionality, I covered the ability to read, ingest, define schemas and land that data into a structured table in Snowflake. This process does a great job capturing data from a JSON response that is pretty basic—a basic response I would define as a response that we can reliably decide how to incrementally load it.
I recently ran into a situation where I could not reliably decide how to incrementally load an API response. The reason for this conundrum is the nature of the data: events! I’m not referring to weddings or company banquets (FWIW: our holiday party will beat up your company’s holiday party). I’m referring to events that are continually being created by a device. In this blog post, I am going to show you how Matillion can capture these events into a variant column that we can then manipulate for reporting downstream.
Why Does This Matter?
Look at this stream of events below:
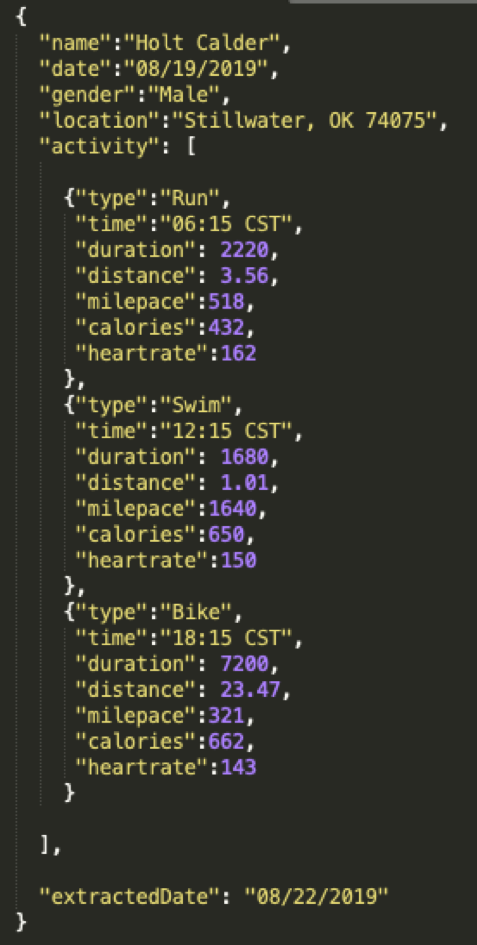
In the Matillion framework covered in my last post, generating the RSD file would require some extra love for my activity list. Matillion has a framework of items for the RSD file that help the program to parse JSON. For a little while, I started trying to learn all of these tips and tricks. Repeat element? Required. Explicit navigation coordinates for a complex JSON response that will probably change? Now I’m wasting time because Snowflake will allow me to navigate that structure in pure SQL. The benefit of pushing this workload down into Snowflake can be captured with a few points:
- No wasted time learning too much about the RSD markup
- Event table can be captured alongside the entities that record them
- Events can be used or unused depending on the report requirement
Adjust the API Profile
In Matillion, you will still want to generate an RSD file the same way covered in my initial post. After the file is created, we will begin to tweak it. Using the sample data shown above, you can see the RSD file generated each activity as a distinct column in my data source instead of treating each activity as a row in my dataset:
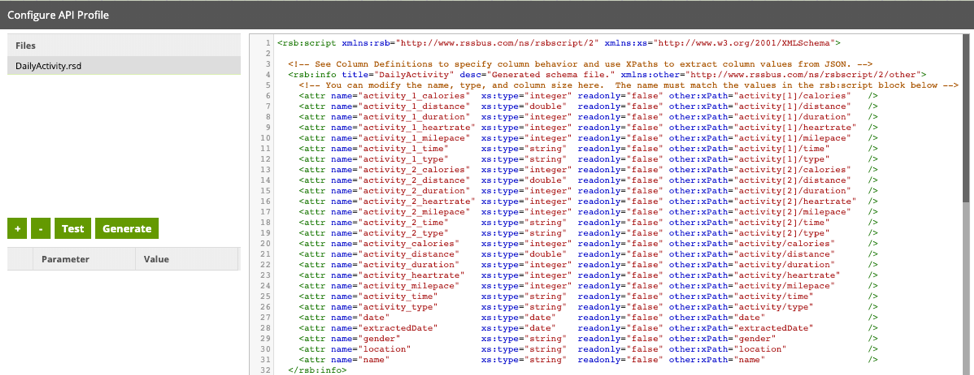
That is exactly what we don’t want. You, my friends, are seeing the exact dilemma that forced me to write this blog. I urge you not to invest time learning how to manipulate these columns into the RSD file. While for this example it wouldn’t be an overwhelming amount of work to fix the column definitions, you never know what else in the API will change and suddenly break your ETL.
Instead, let me show you the easier way 🙂
In this line in the API profile, we can see some attributes about one of our activity columns:
<attr name="activity_1_time" xs:type="string" readonly="false" other:xPath="activity[1]/time" />
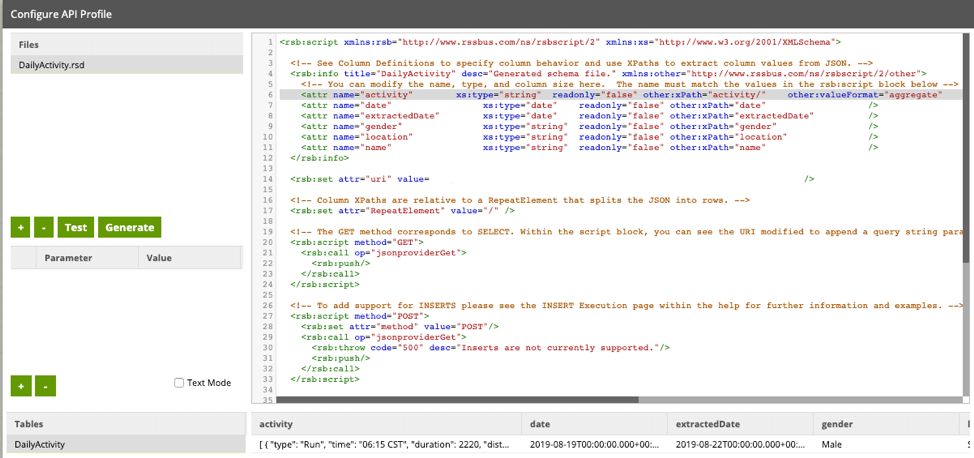
Adjusting the xPath and adding a valueFormat of aggregate to the column allows us to pull in that entire activity object as JSON. The change in my column definition is shown below:
<attr name="activity" xs:type="string" readonly="false" other:xPath="activity/" other:valueFormat="aggregate" />
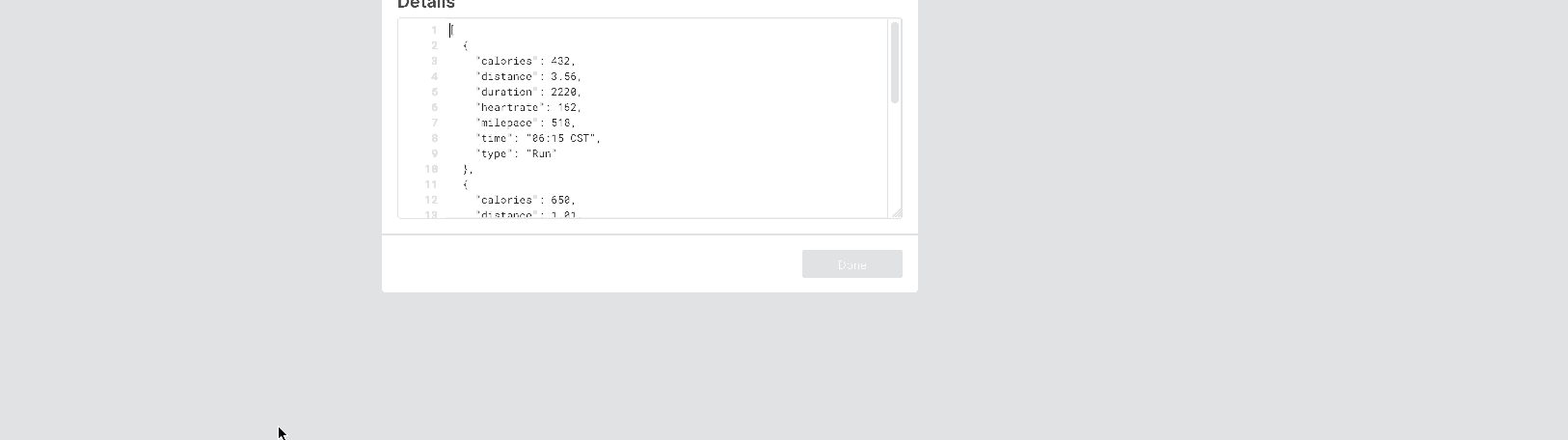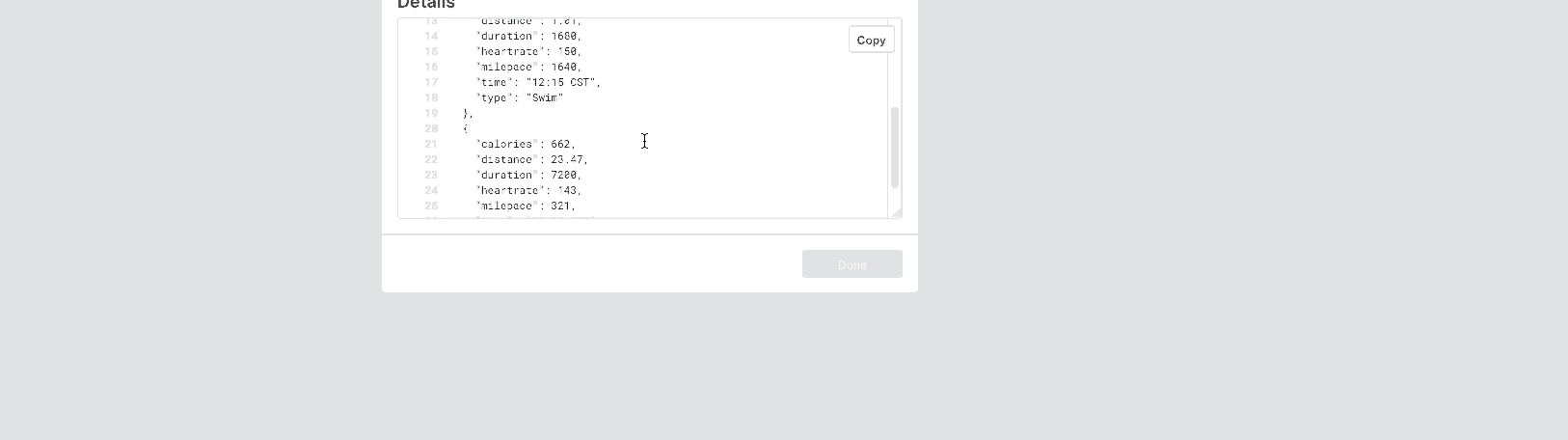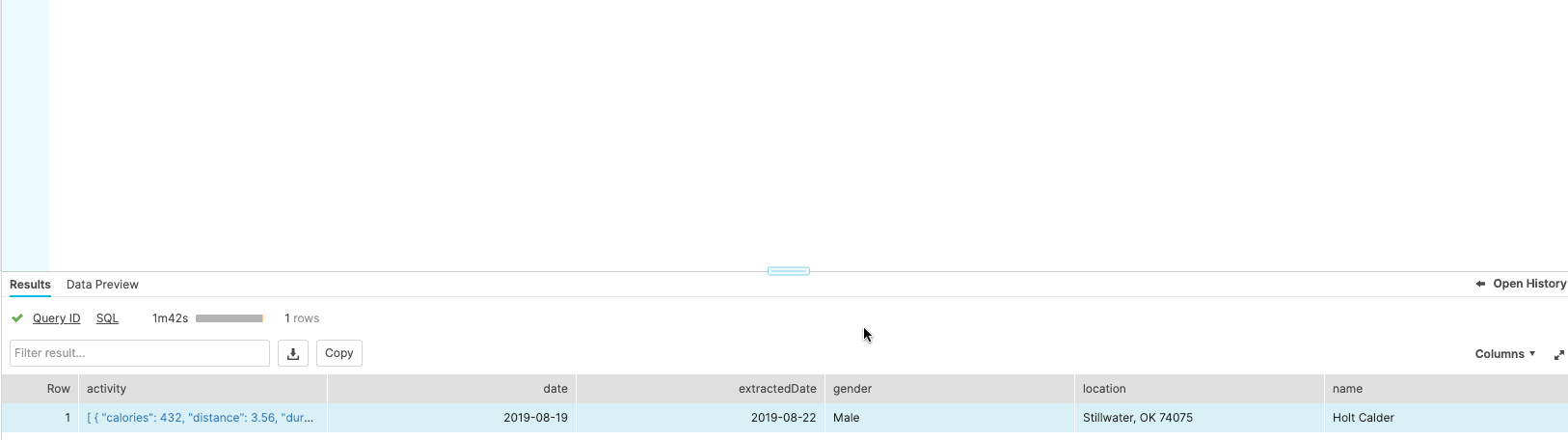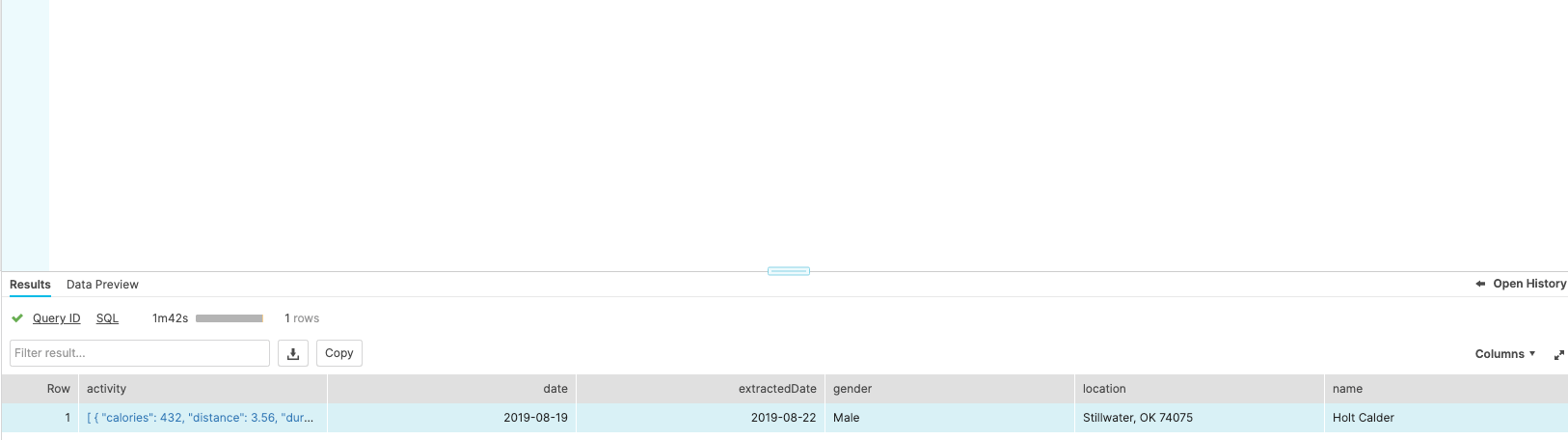
My updated RSD file is much cleaner and gives me a response I can manipulate downstream in Snowflake:
Load Data into Snowflake
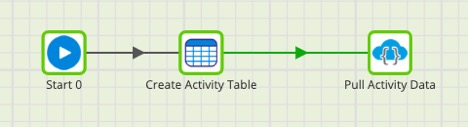
Matillion supports a few data warehouses, but they don’t all have a variant column. This means when Matillion’s API Profile decides which column type the response should be, it does not intuitively decide to create a variant column. Instead, it tries to load the JSON as string. We obviously need the data as a variant so that we can navigate its structure, so the final step to making this configuration work is “hacking” the API Query Component to load our API response into a predefined table structure to ensure we have the correct data types. To do this, we build a job that will create our table and run the API Query Component without recreating the target table.
Matillion Orchestration Job
JSON Response

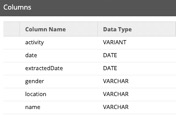
Snowflake Table Structure
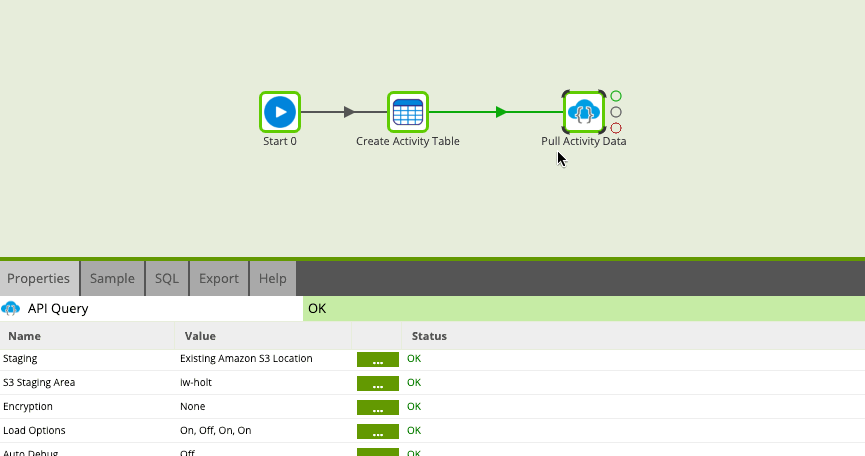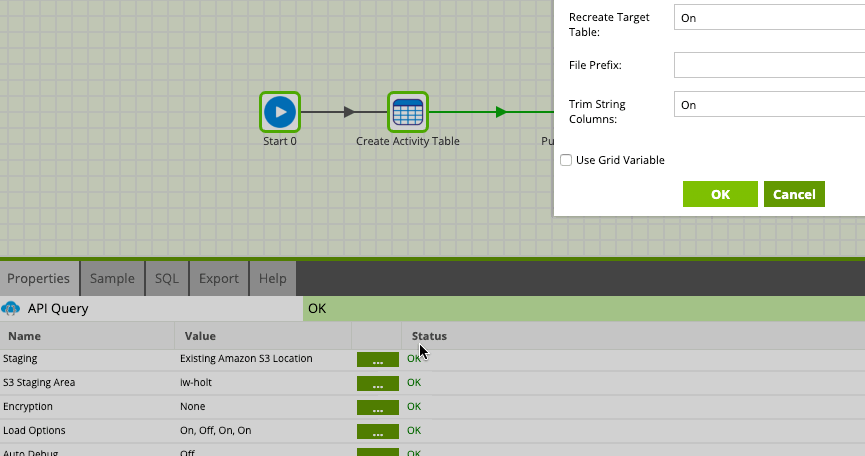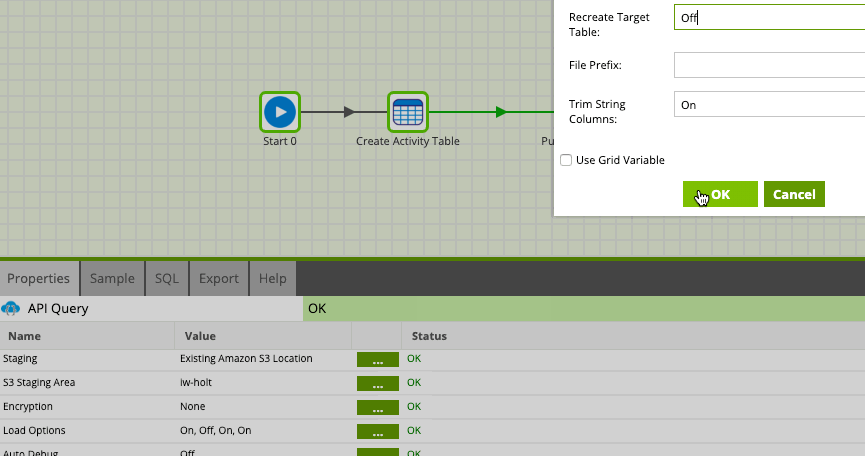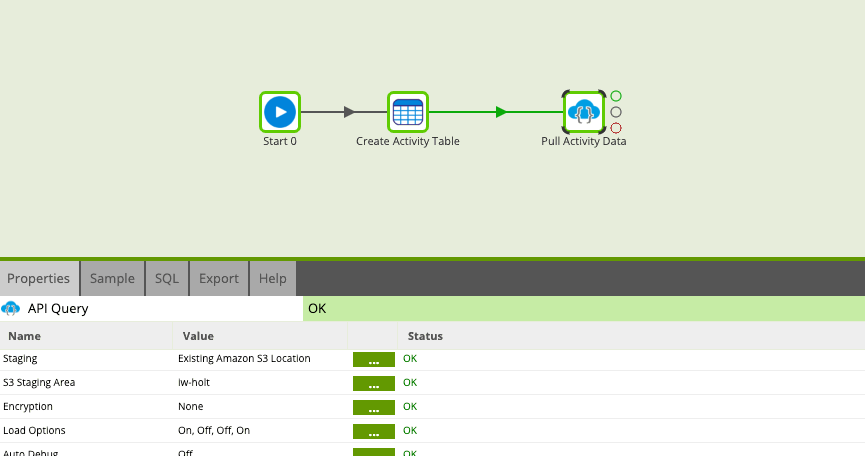
Turn off Recreate Target Table Load Option
Flatten it or don’t; you now have the flexibility to work with this data in SQL! For more information about writing SQL against JSON with Snowflake, check out this blog.
While this particular example is targeted more towards event-driven APIs, the logic and value of being able to run raw JSON through Matillion has many applications and broadens the tool’s ability to work with disparate data sources. I have worked on a few API projects using Matillion, and this is a game changer for the longevity of those solutions.
As always, if you have any questions about Matillion or API integrations, please feel free to reach out!