
Matillion – cool name, cool tech. Before I get into the actual tech, I’ve just got to comment: Who comes up with all these company names? It seems like in the entire tech industry, the Coolest Names Award is going to big data. Okay back on topic: What is Matillion, and why should you care? Matillion is an ETL tool that’s available on the AWS Marketplace. It is completely cloud-based, billed at an hourly rate and comes with significant advantages when coupled with Snowflake, Redshift and BigQuery.
We have been using Matillion for Snowflake with as many of our clients as possible. Here’s why: When you build an extensive data warehouse from the ground up, it can sometimes be tough to hand it off at the end of the gig. Matillion effectively automates most tasks in the ETL process, allowing you to build a data warehouse from the ground up with complex ETL processes all while leaving very few opportunities for routine errors.
Matillion comes with a list of “components” that are used as a toolkit for your ETL journey. These components range from DDL SQL commands to Python scripts, and some of these components are designed to perform some of the most complex of tasks. The predefined components actually generate SQL code that you could drop in your IDE and test with, making data validation so much easier (all while making you look like a SQL guru).
To introduce Matillion, I’m excited to kick off a little project I’m working on. Over the coming months, I am going to relive my cross-country glory days and start prepping for longer-distance races. I’ve been running for about six years, and it’s something that I would like to become competitive in for the rest of my life. As I train, I want you to follow the process with me while I go from regular two-mile runs to my end goal of a half marathon. Along the way, I’ll build a data pipeline that will help me analyze my performance and identify contributing factors to my success.
Throughout this process, I am going to let Matillion do a fair amount of the heavy lifting. To get started, I’m going to build my Matillion project.
Initial Project Setup
Before I can start playing with anything cool in Matillion, I’m going to build a project repository that will host my orchestration and transformation jobs. After logging in to our AWS account and powering on the Matillion EC2 instance, I was able to log in to Matillion with a user account provisioned for me.
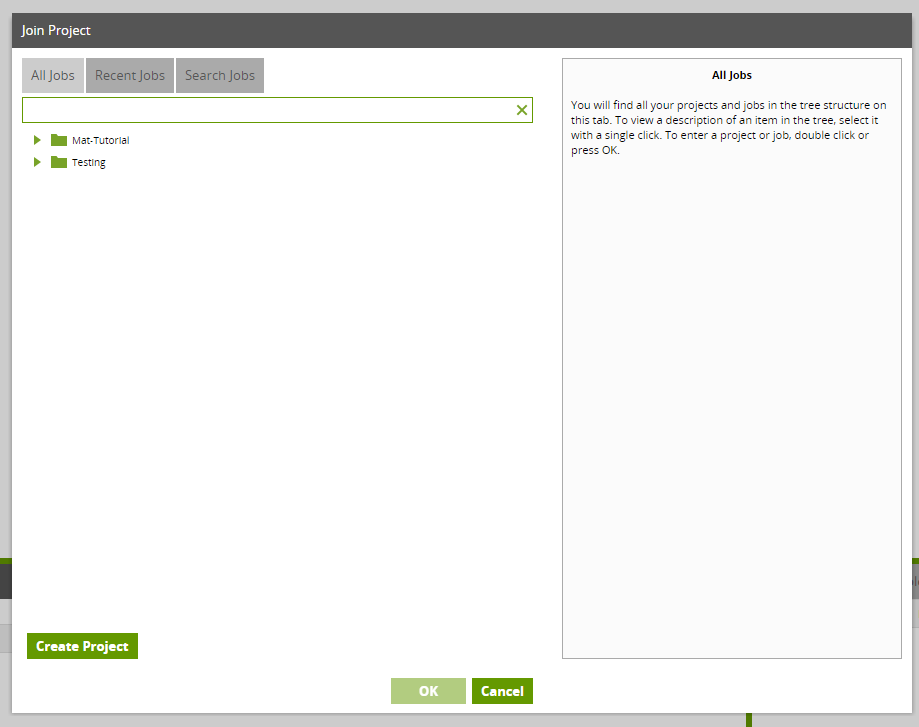
Now that I’m logged in, instead of joining an existing project on the launch screen shown above, I am going to create my own and lock it down so that only my user account will have access. Go through the form and fill in details relating to your project. This is where Matillion will be granted access to interact with our AWS S3 bucket and Snowflake.
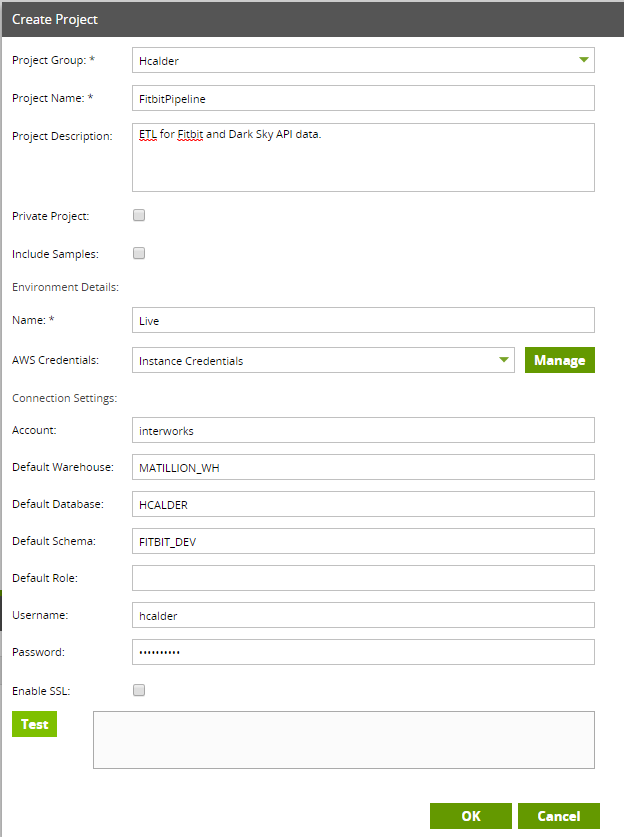
Quick overview of the fields to pay attention to:
- AWS Credentials – If you leave this as the default, it will authenticate with the AWS IAM that was used to configure the Matillion instance
- Account – Snowflake account name
After creating the project, I can test the credentials and begin building.
Pipeline Overview
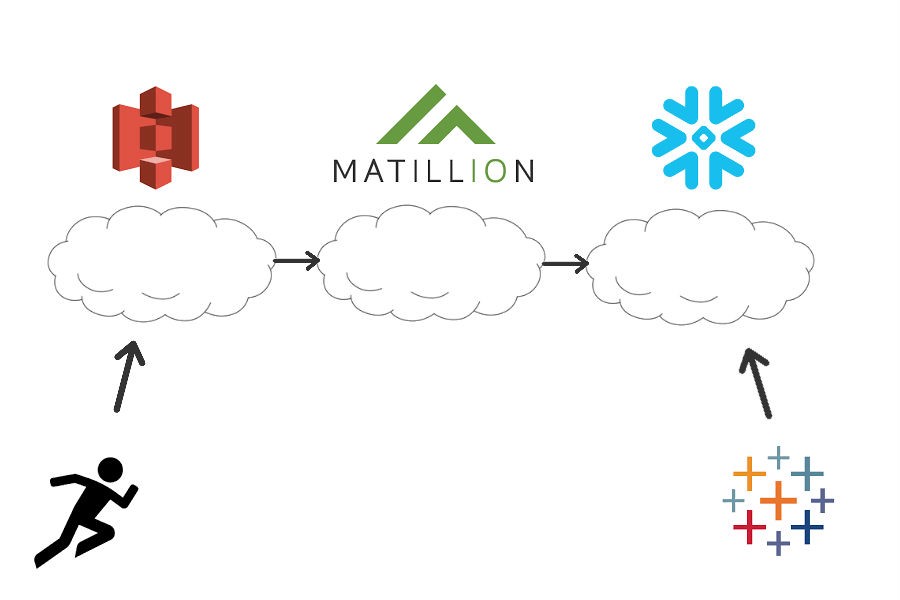
Now that the project is built, I’m ready to get started. The first thing to do here is to figure out what I want my workflow to accomplish so I can plan what tools to use accordingly. As T. Boone Pickens once said, “A fool with a plan can beat a genius with no plan any day.” In this scenario, I’m the fool with the plan. This project is going to be analyzing data from two sources: The Dark Sky API for weather, and performance data from a fitness iOS app or Fitbit. This will help to figure out how weather conditions impact my performance.
After getting out and running around ’til my face turns blue, I want to upload this data to an AWS S3 bucket on a predetermined schedule (maybe with a fancy Python script 😊). From S3, I then want Matillion to take the Dark Sky JSON data and load it into a table, then do the same with the workout data. From there, I’m going to let Matillion to build a view with the tables that hold my data. Then, I will connect it to a Tableau dashboard for visualizations.
It’s going to look something like this:
Getting the Matillion Job Started
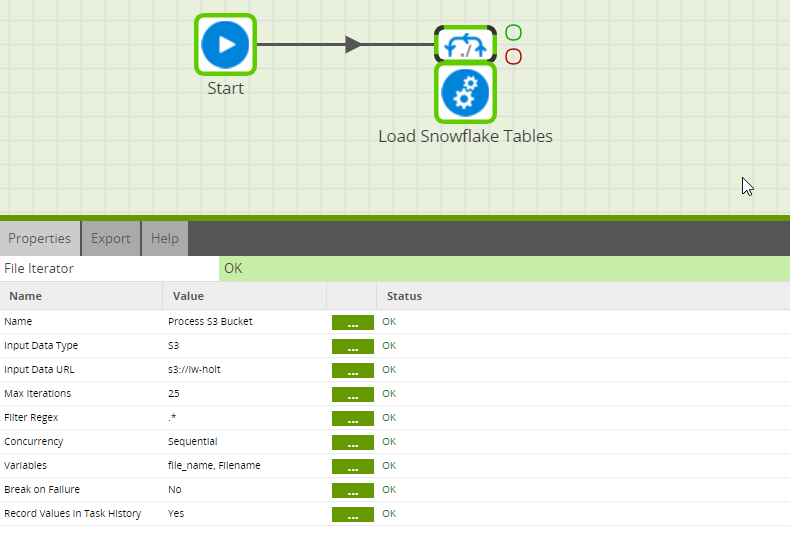
The first step of my Matillion job will be reading files in my S3 bucket and storing their names in an environment variable for later use. To accomplish this, I created an Orchestration Job in Matillion and attached the File Iterator component to the beginning of my workflow. The File Iterator is selected in the screenshot below. The iterator reads through my S3 bucket iw-holt and stores each file name in the variable file_name. Additional functionality allows me to filter the selection with RegEx, which will be useful for this project.
This is just the beginning of my data pipeline’s requirements. Over the coming weeks, I will be adding extensively to this project, and I am excited to walk you guys through the process. In the future, expect blog posts about:
- Building and loading tables with Matillion (makes working with JSON even easier!)
- Using Matillion to clean semi-structured ata
- Snowflake’s performance with a live connection to Tableau
- Anything interesting I encounter building the pipeline …
If there is anything you would like to see represented in the project, please feel free to drop it in the comments! I will be using Matillion quite a bit, but I will definitely keep my eyes peeled for opportunities to introduce Talend and Fivetran. I am excited to showcase for you guys the power of some of these cloud tools I’ve grown to love so much. Using cloud ETL tools with Snowflake makes something like this not only possible but easy. This will be a great learning experience for everyone observing and potentially could give you guys an example of how to build the pipeline for your own data warehouse!