
There are things in this world that data engineers love and hate. For example, they love green and hate red. Green is good, but when you see red, the ETL job is dead! Data engineers also love seeing the word “success” because it subconsciously triggers flashbacks of successful jobs. No errors. Data objects populated as expected. Glorious.
Data engineers really love Matillion.
After years of digging in the ETL trenches with older tools, Matillion is a breath of fresh air. Its sleek user interface and common-sense approach makes orchestrating dataflows easy as ever. We have had a lot of success building data warehouses in the cloud for our clients using Matillion.
This article will help you get started on your journey by providing step-by-step instructions on how to land data from a Microsoft SQL Server database into a persistent staging area in Snowflake using Matillion.
What is a Persistent Staging Area?
A staging area is a “landing zone” for data flowing into a data warehouse environment. In a transient staging area approach, the data is only kept there until it is successfully loaded into the data warehouse and wiped out between loads.
A Persistent Staging Area (PSA) is a staging area that does not wipe out the data between loads and contains full history from its data sources. The primary advantage of this approach is that a PSA makes it possible to reload the next layer in the data warehouse (e.g. a data vault) when requirements change during development without going back to the original data sources. You can begin collecting data for parts of the data warehouse you have not even built yet. The original data sources may not contain history anymore, but having a PSA will allow an organization to own its own data.
Overview
These instructions will cover the following six jobs: three jobs for the initial load and three jobs for subsequent delta loads. As you will see, the jobs are nested so that the first job calls the second job, and the second job calls the third job. Let’s get started!
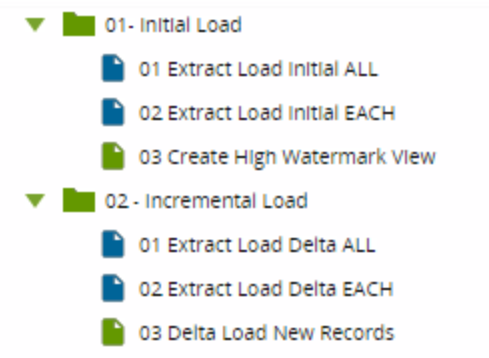
Initial Load
The first job (01 Extract Load Initial ALL) looks like this:
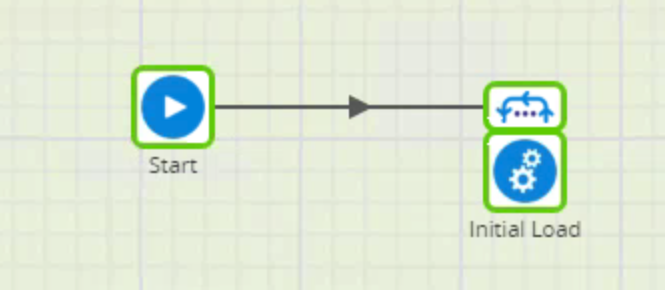
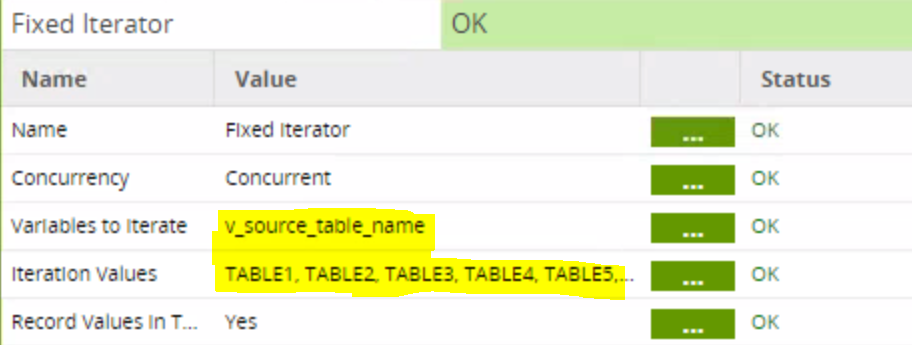
The top component is a Fixed Iterator that iterates through a list of tables, mapping the table name to an environment variable I created called v_source_table_name:
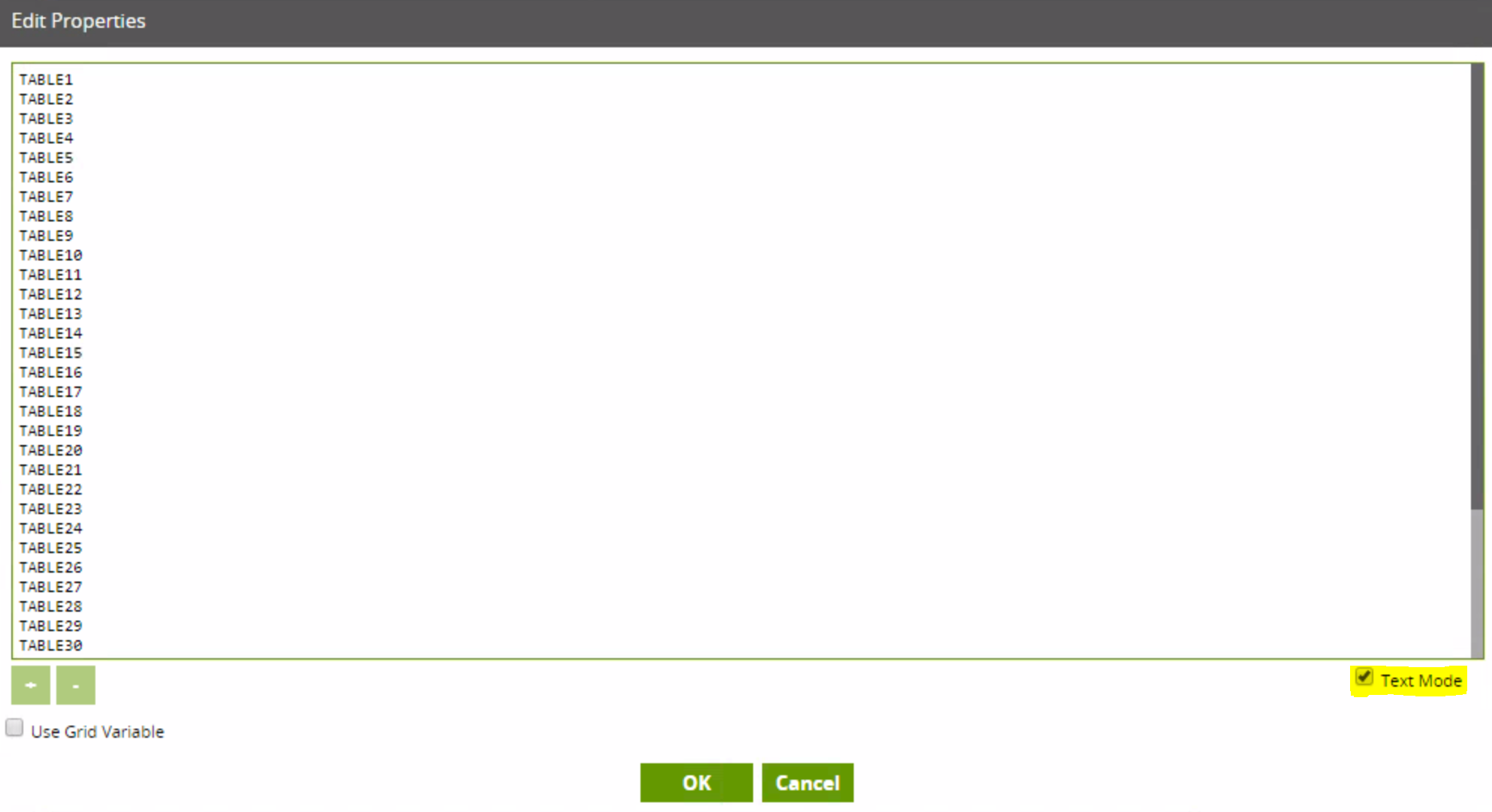
Matillion makes it very easy to copy and paste a list of tables into the Iteration Values with its Text Mode feature. Of all the things I love about Matillion, Text Mode has got to be right near the top of that list:
As I said before, the first job calls the second job in the Run Orchestration component, passing along the table names via the v_source_table_name variable:
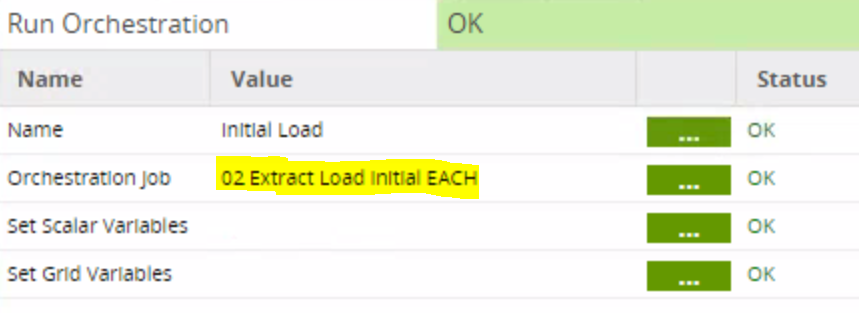
Now, onto the second job.
The second job (02 Extract Load Initial EACH) looks like this:
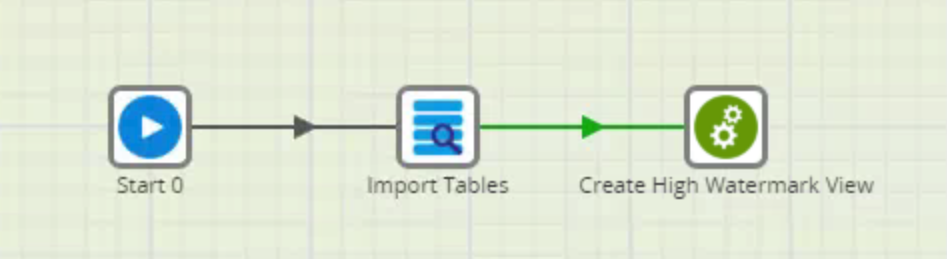
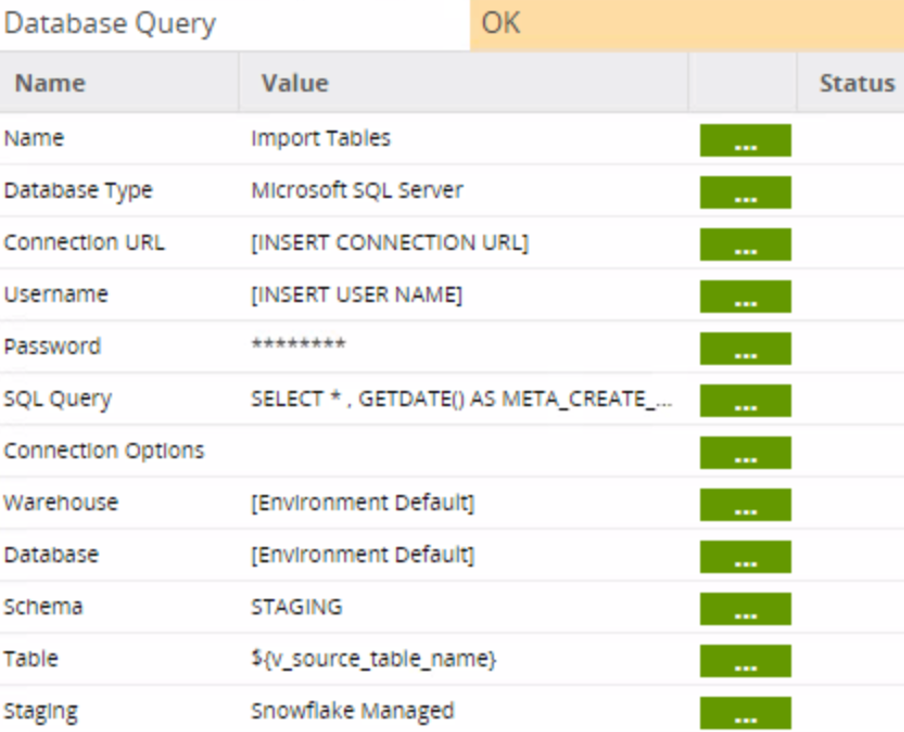
The Database Query component sends a SQL script to the source database (in this case, Microsoft SQL Server) and will write the output to a Snowflake table:
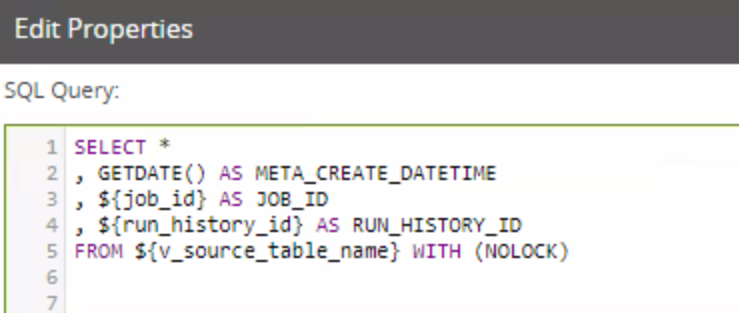
The SQL script selects all the columns and adds a few reference columns for auditing purposes:
The final component of the second job calls the third job:
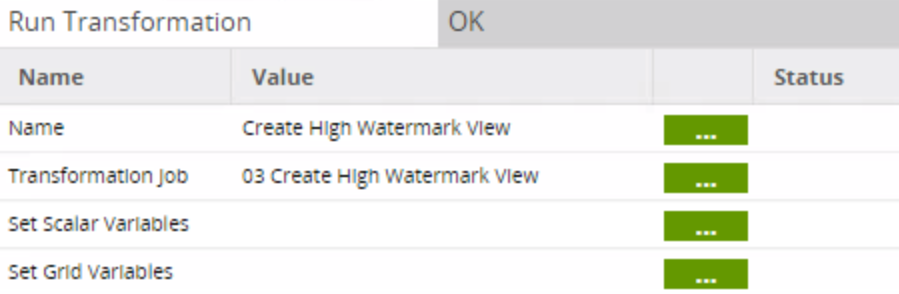
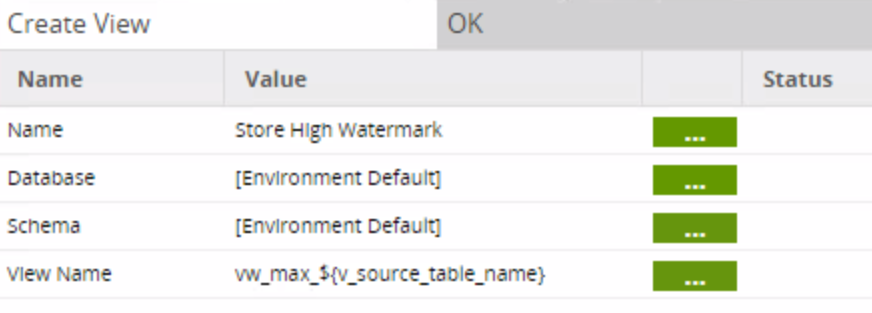
The third job (03 Create High Watermark View) looks like this:
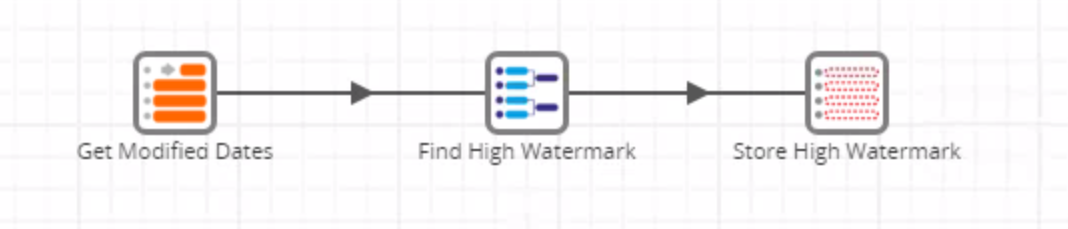
This job creates a view that stores the MAX value of the LAST_MODIFIED_DATE, a high watermark that will be used in subsequent delta loads:
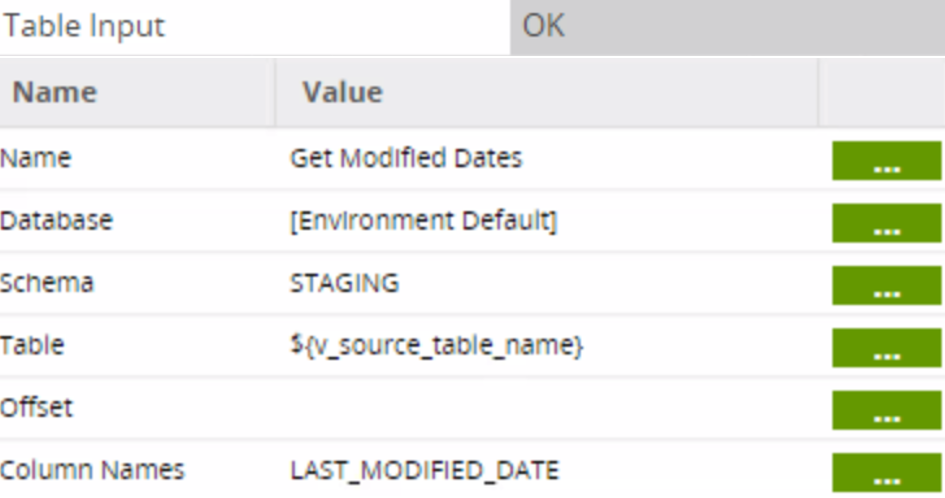
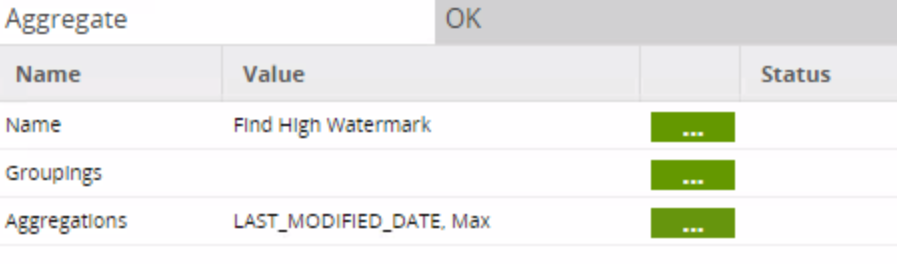
After a run the first job, the initial load should be complete! You should have all of your staged tables, each with an associated view that stores the high watermark date of that table. Now, let’s see how to load the table from that point forward.
Incremental Load
Once the initial load is complete, subsequent jobs only need to load the deltas (new or changed records since the last load).
The first job (01 Extract Load Delta ALL) looks almost identical to the first job of the initial load:
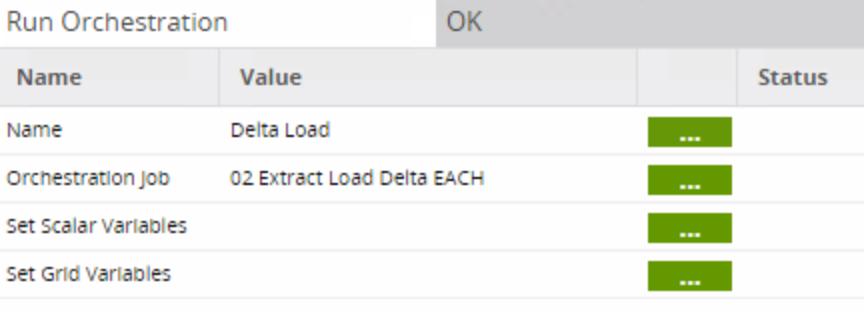
The only difference in the job is the orchestration job called in the Run Orchestration component:
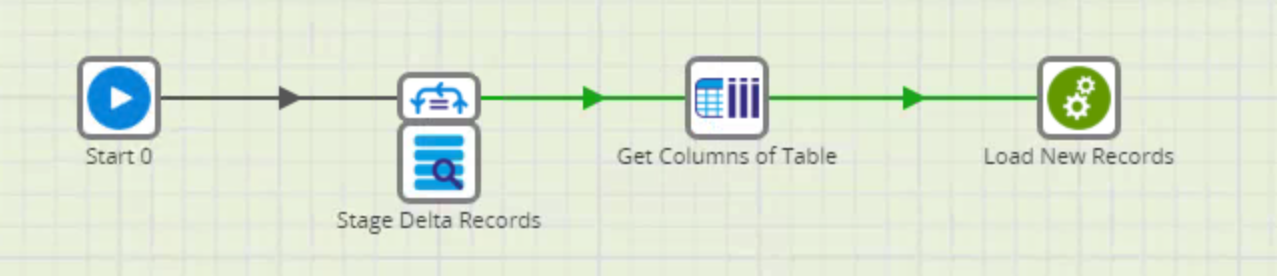
The second job (02 Extract Load Delta EACH) looks like this:
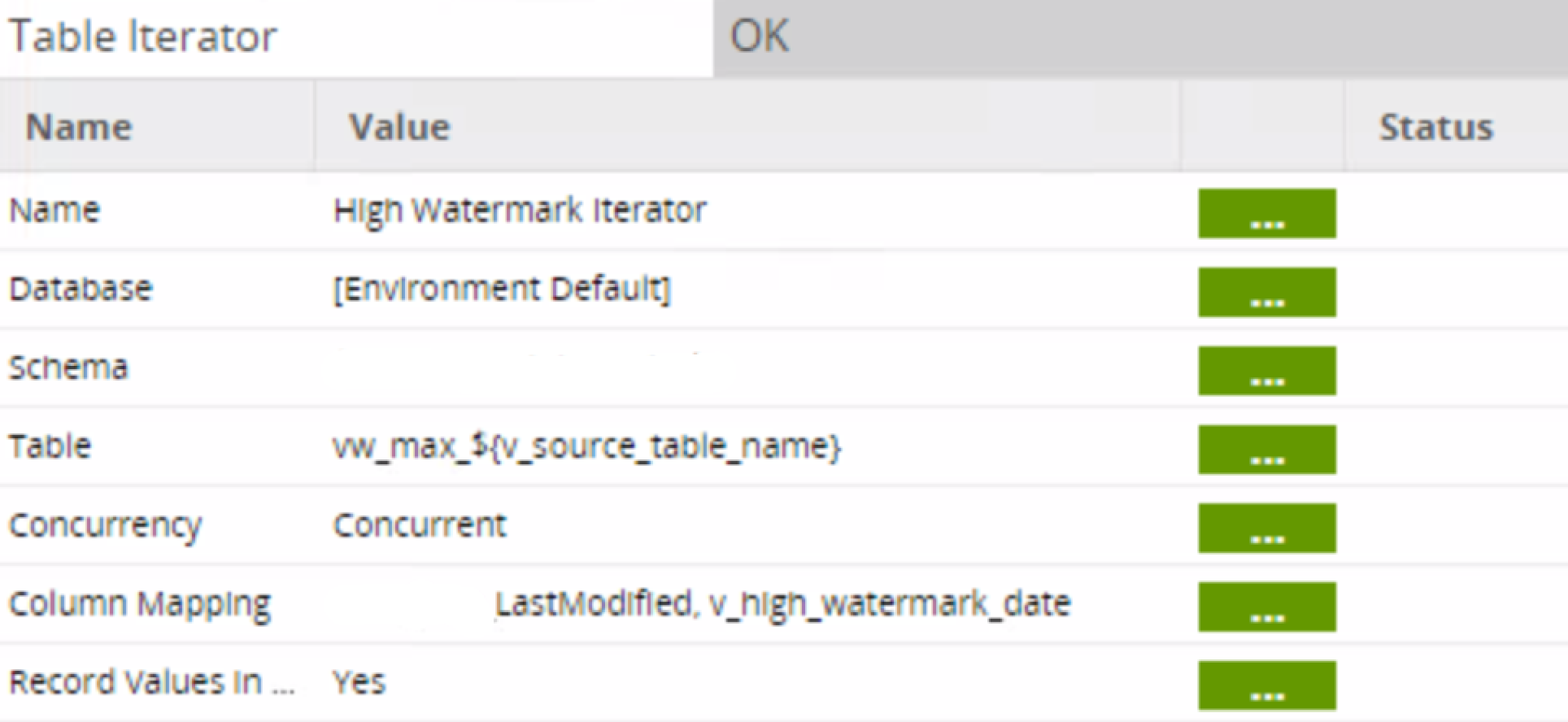
A Table Iterator captures the high watermark value stored in the vw_max highwater mark views created during the Initial Load and maps it to the environment variable v_high_watermark_date:
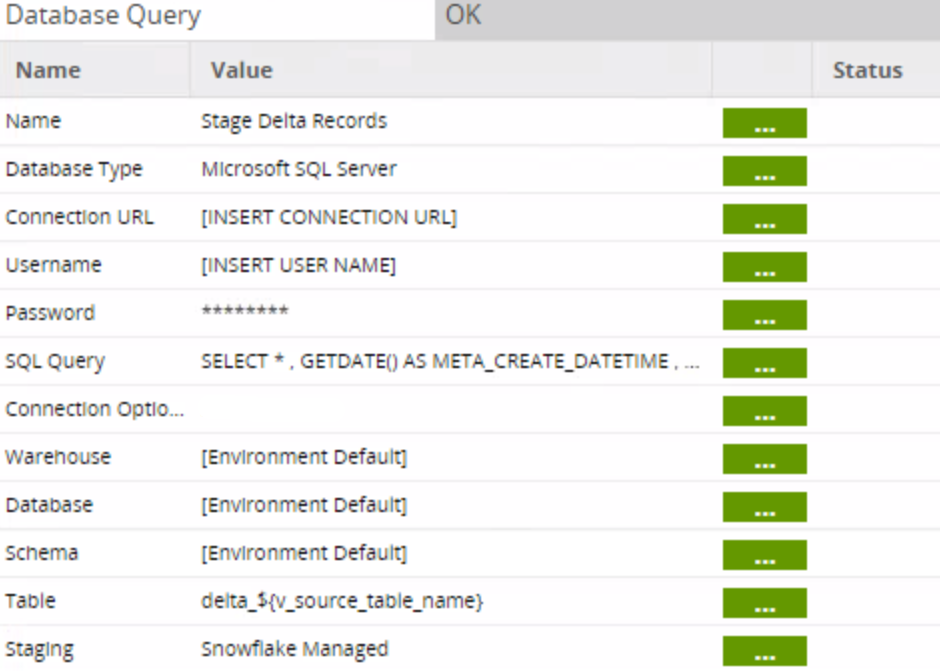
The database query will select only the records with a LAST_MODIFIED_DATE greater than the high watermark date, writing the new records to the delta_ table:
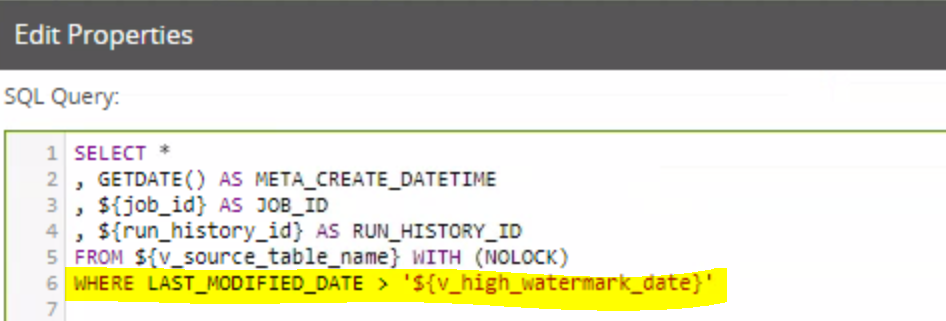
In the SQL Query, the variable v_high_watermark_date is used as a filter:
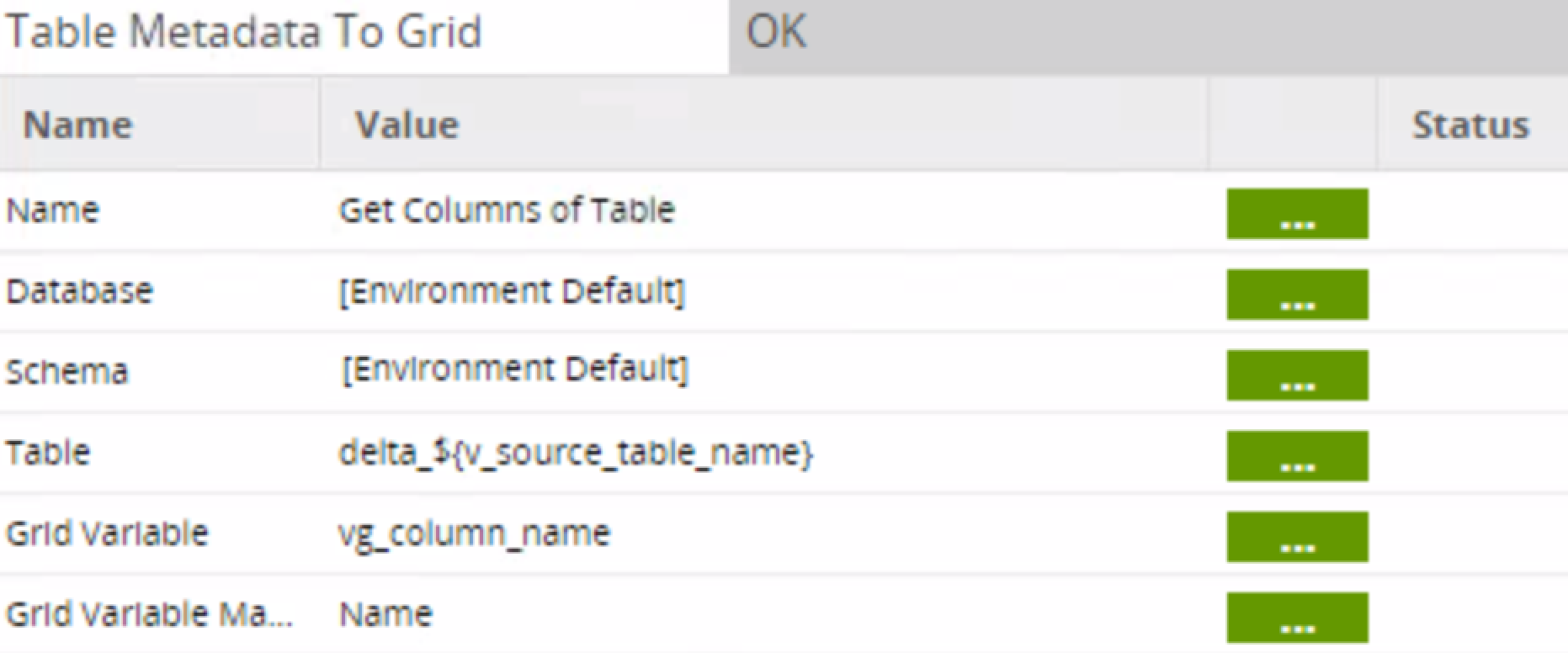
The Table Metadata To Grid component is an extremely useful feature in Matillion that allows you to map the columns of the delta table to a grid variable vg_column_name for use in the third job:
The Run Transformation component calls the third job and passes the grid variable:
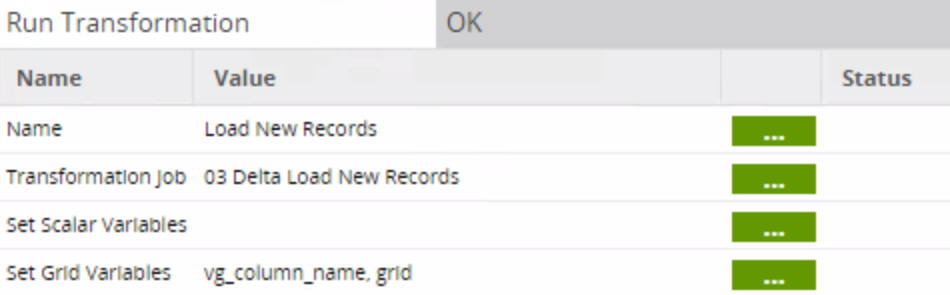
The third job (03 Delta Load New Records) inserts the new records from the delta table to the staging table:
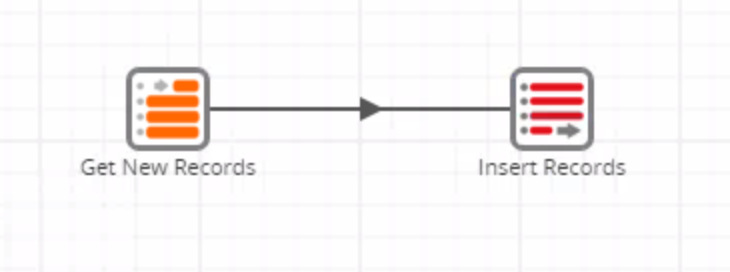
The Table Input calls the records from the delta table. Note how the columns are mapped using the grid variable instead of specifying each column name. If not for this feature, a separate job would have to be created for each table:
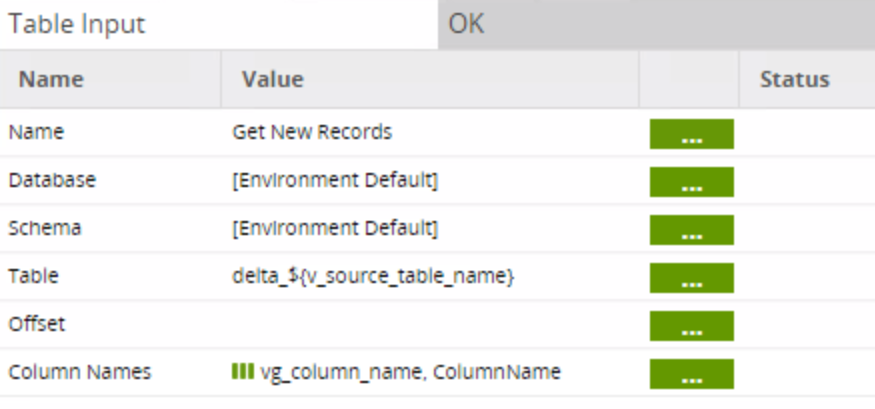
The Table Output inserts the new records into the target table in the persistent staging area. The property is set to Append new records:
Schedule the first job (01 Extract Load Delta ALL), and you’ll get regular delta loads on your persistent staging tables. The price point of storage keeps falling, so this method is a great way to capture history on your valuable data resources and future-proof your IT infrastructure.
If you have any questions about how to do this, please feel free to leave a comment, or send me an email! Good luck!