
Surprise, surprise … another year in the books. I genuinely contemplated copying and pasting the opening paragraph of last year’s blog, but here I am writing an original opening to close out the decade. Start strong, finish strong, right? And as we begin a new year, we’re taking a closer look at how we can refresh our perspectives on data. Looking ahead, there are lots of new opportunities and technologies that can help renew your analytics efforts.
Reflecting on 2019
Last year, when I was sitting down to write this blog, the landscape in the industry felt very different. At the beginning of 2019, we identified a few areas to focus on in the new year. Looking at that list as an architect or engineer at InterWorks in 2019 meant a few things:
- Be Agile – Deliver value from source systems quickly. Take advantage of tools like Matillion to move data from relational databases and APIs into Snowflake.
- Be Repeatable – Fill the glass only once. This idea is called idempotency, and it means that a data pipeline should yield the same exact results in the warehouse whether it is run one time or dozens of times in the same time period.
- Be Transparent – Under the hood is where all the magic happens. Logging, alerting, modeling and documentation about our deliverables should be easily explained and readily available.
- Be Nice – Every client we work with is at a different stage in their own data journey. It is our job to help them along that path, and to have a good while attitude doing it.
That list might be obvious to some, but it is at the core of what makes InterWorks different from other consultancies. In 2019, our data practice strived to separate ourselves from competitors by being a “Small Giant”. As we move into 2020, we have a new list for our audience to watch out for as we start this new year and decade.
{kind=link}
Winning 2020
In 2020, we have one goal: continue the momentum of establishing ourselves as the best data consultancy in the world. Looking at how data has changed over the years, it is undeniable that managing, presenting and monetizing data completely changes the value of a business. Looking at what’s on the horizon, we are starting the year with a few focal points:
- Share the value of implementing streaming pipelines with our clients.
- Continue to explore exciting new message-bus technologies.
- Continue to be at the cutting edge of Snowflake’s new features and tools.
- Educate our clients and audience about how the cloud makes enterprise-grade tools more accessible.
Streaming Architecture
Towards the tail end of 2019, we saw a trend among our customers—the need for data pipelines that are continuously streamed into the data warehouse. This trend is not new; as a matter of fact, the larger tech companies in the Bay Area have been utilizing this architecture for years. Even though the architecture isn’t new, what is new is the set of tools capable of performing this task. It is beyond exciting to see enterprise tools that are now able to offer an easy-to-use, out-of-the-box way to leverage this architecture.
Businesses are typically concerned with costs. How do we get data from A to B for less than $X? This requirement typically took streaming off the table for one primary reason: We don’t know how much data will come through, and on tools that have a pay-as-you-go model, this can be problematic. At the end of the year, we started to see some new ways to address this. Using Snowflake’s Snowpipe, we can load data as soon as it is available in S3, and Matillion also has functionality that can support this style of workflow. Before the data flows through Snowpipe or Matillion, we can also use tools from AWS to micro-batch these streamed records to control costs. Overall, this landscape is much easier to navigate than it was before.
In 2020, I imagine most organizations’ ETL architecture will be split between batch and streaming workloads to support different styles of reporting:
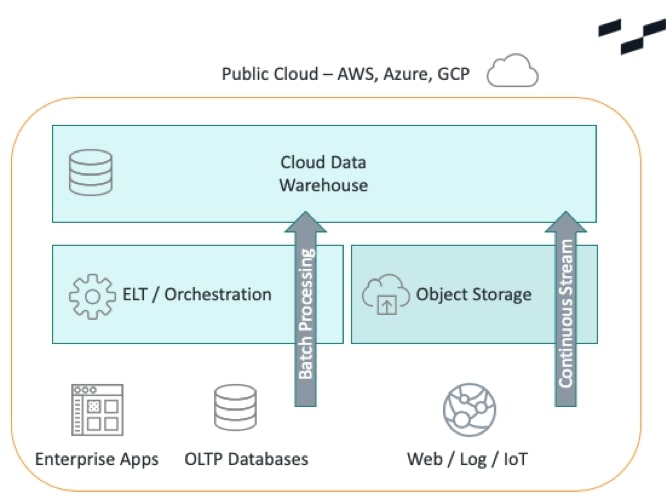
Message Buses
A trend that we are watching closely is the implementation of message buses in the traditional data warehouse architecture. A message bus is fundamentally a broker between systems. In your daily life, when you send an email to a recipient, a message bus takes your message and distributes it to another party. Architecturally, you could achieve this same back and forth from a transactional database (OLTP) to an analytical database (OLAP). These message buses are lightweight, typically handle single record sets at a time and pair nicely with tools that offer real-time data.
Currently, Kafka is the gold standard for message buses, but we also hear frequently about RabbitMQ and the use of AWS SQS for these workloads. What is extremely interesting to us about this architecture is the ability to completely merge the gap between transactional and analytical workloads. In 2020 and the upcoming decade, I believe we will see source systems that are ready to leverage this architecture as the standard.
Snowflake Maturing
At the beginning of 2019, Snowflake was just a great service. As 2019 closes, Snowflake has become an absolutely exceptional service. Snowflake originally differentiated itself through the truly decoupled storage and compute operations of the database; however, its effectiveness led us to assume that this architecture was soon to be copied by other cloud data warehouses. To combat this and retain its edge, Snowflake has introduced concepts into the platform that make working with large amounts of data at scale across an organization easier and less time consuming. In 2019, we saw the introduction of Stored Procedures, Tasks and Streams.
The introduction of these tools opened a whole new playground inside of the database, uncovering the opportunity for unique architectures and effective use of the platform’s strengths. I think in 2020 we will see some major changes to the platform: more tools that open worlds within the platform, more tools that affect the way we interact with Snowflake and more tools that change the way Snowflake interacts with customers. As the year progresses, InterWorks will continue to be at the forefront of all things Snowflake—and hopefully win another Partner of the Year award for the US and APAC!
Cloud Accessibility
The way cloud computing has impacted data is undeniable. Not long ago, you were only capable of running enterprise workloads if you had a multi-million-dollar budget. In the same way that Snowflake has lowered the barrier to entry for data warehousing, we believe things will get easier to buy and deploy across the entire industry. Tying this into the list above, I believe that in the coming years, we will see these tools and architectural patterns continue to simplify and become the norm across organizations.
The cloud’s impact on the accessibility of these enterprise-grade tools opens up opportunities for businesses that may have smaller engineering teams or less experience working with these tools. In the end, this will push analytics further. Having a low cost of entry is good for the future of these tools, as well as our industry as a whole.
Tackling These Data Goals in 2020
In this new year and decade, we are thrilled to continue studying technology we love in order to solve the data problems of the world. Let’s make this the best year yet!