
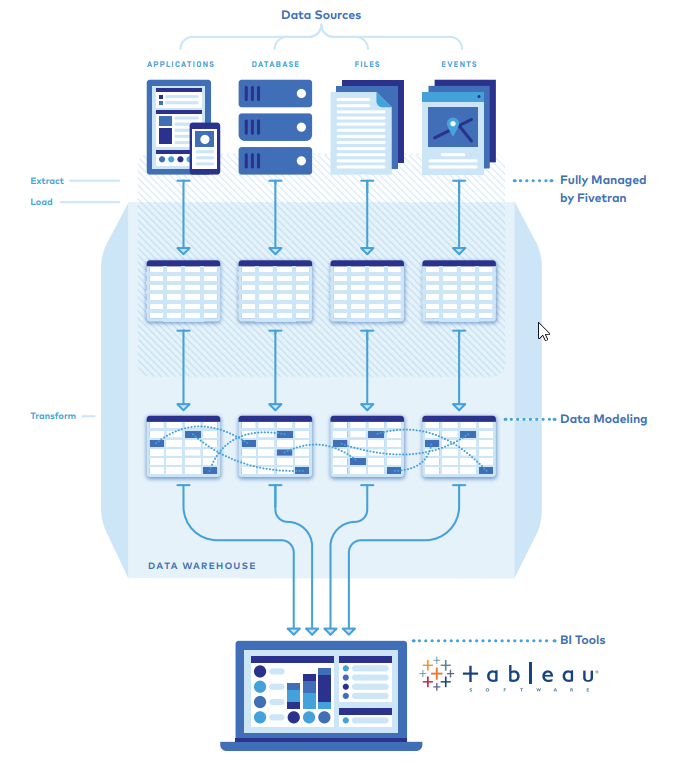
Image above courtesy of Fivetran
Lately, I’ve been writing a lot about Snowflake, a cloud data warehouse that brings joy to the world of analytics. While I’ve spent a good amount of time outlining the benefits of the way Snowflake approaches data warehousing, I recently had the idea of discussing why businesses benefit from using a data warehouse in the first place and how our new partner Fivetran streamlines the process of building one.
The Need for Data Warehousing
Our journey begins with why you should care about data warehousing, and to show you, I’ll open with a scenario. I am trying to create a single Tableau workbook that tells the story of how my harmonica tuning business is gathering new leads. We’re slam packed after going on tour with Willie Nelson. While I build my reports, it takes hours to locate the data I need, and after finally tracking some of it down, I’m running into issues using it. Since these data sources live in different places, and in some instances are managed by different people, I am forced to block off my calendar for the next week to resolve all the issues leaving me frustrated and at a halting stop.
Data Warehousing 101
On the other end of the spectrum, we have data warehousing, which is designed to avoid the issues presented above. Warehousing is built on the concept of storing ALL your data in one place for discovery, management and distribution. The goal is to replicate a similar solution to Amazon’s network of warehouses. These warehouses distribute millions of packages across the globe efficiently and with a clean operating process. Data warehousing aims to apply the same concepts of centralization, security, adaptability, accessibility and timeliness to how businesses store their data. The goal of the data warehouse’s existence is to be a trustworthy source for enhanced decision making.
Before you can move to a data warehousing approach, you need to clean up the messy menagerie of data sources, consolidating and synchronizing them to one central location. This replication process can prove to be tricky. I can almost hear you already: “But Holt, our business has a gazillion different departments, and they all have their own databases. How could I possibly migrate all of that to one place and not lose anything?” Well, I’m quite glad you’re curious because a great tool to simplify this process is Fivetran.
Fivetran
Fivetran is the no-maintenance pipeline, moving your data from separate sources into a centralized data warehouse quickly and reliably. Fivetran offers a ton of value to businesses through their various connectors, giving you the ability to synchronize over 100 data sources and centralize them into your Snowflake, Big Query or Redshift instance. When it comes to data replication, I haven’t found a product that is more satisfying to use than Fivetran. Each detail, from the user interface to the way it handles changes in the underlying data, comes together to create a unique sense of trust.
What is a Connector?
A connector is Fivetran’s main product; think of it as the Incredible Hulk of copy-pasting big data. These connectors have been carefully engineered to account for almost every scenario, ensuring the data flowing through your pipeline is accurate and unchanged. What do I mean by accurate and unchanged? I will outline a couple scenarios below and explain Fivetran’s approach to each situation.
The Missing Row
“My business occasionally deletes rows from our source system. I am using a Fivetran connector to replicate this data from my source system to a Snowflake instance. My data warehouse powers all my reports. What happens when a row is deleted from my source system but already exists in Snowflake? Will that data be deleted as well, and will I have any clue it’s gone?”
When it comes to deletion of data, Fivetran will never nuke your information. Instead, they have developed a great solution using system columns to ensure the integrity of your data remains. These system columns are added to every table that’s loaded to your warehouse and contain metadata about deletion, syncing and internal IDs to avoid duplicate values. Using these system columns ensures that Fivetran acts as the single source of truth for your data. Nothing will ever be massaged or removed; it is a true representation of your source system. The system columns added are:
- fivetran_synced – a timestamp of when the row was loaded into the warehouse by Fivetran
- fivetran_deleted – a Boolean field marking whether a row was deleted in the source system
- fivetran_index – an index for you to determine what order updates occurred in a table without primary keys
- fivetran_id – a generated unique ID to avoid the creation of duplicate rows
- fivetran_id2 – a generated unique ID to handle rows with null primary keys
The Errant Update
“We recently had an error occur in our source system. A few dummy rows accidentally made it past a development environment, and our Fivetran connector replicates the source database every fifteen minutes. We can identify that this would have created a higher-than-normal upload to our warehouse, but how do we track down those records and purge the bad data?”
Similar to the system column feature, Fivetran generates a full audit table after it completes loading. The fivetran_audit table generates metadata about the load job and contains the following columns:
- done – the timestamp for completion time
- id – the unique ID for the audit
- message – error messaging
- progress – internal use by Fivetran
- rows_updated_or_inserted – the number of changed or updated rows
- schema – the schema name where the update/insert occurred
- start – beginning time for the connector update
- status – the stage of the sync
- table – the table the rows were inserted into
- update_id – the unique update ID for the sync
- update_started – the scheduled start time for the update
Note: System column and fivetran_audit information quoted from the fivetran docs
 Above: Example of fivetran_audit Table from Google Sheet Connector
Above: Example of fivetran_audit Table from Google Sheet Connector
The Importance of an Audit Trail

Having an audit trail generated as you ingest data into your warehouse is a key feature of Fivetran. The system column and fivetran_audit tables are two of many system audit tables, and these tools add significant value to how your team reacts when something inevitably blows up. Many of Fivetran’s connectors even contain their own system tables that allow a look into the details of each upload and record data related to the service you’re connecting to. In addition to the generic fivetran_audit table, if a single table triggers multiple warnings, a fivetran_audit_warning table will be created. The cleanest piece of this audit trail is that it is generated as the data is loaded, and it lives right next to the new tables.
When you think about the task of centralizing an entire reporting environment in one place, the ability to trust the data flowing in is the only thing that matters. Having metadata about the loading process be generated automatically is a significant benefit of using Fivetran and is something that makes me feel comfortable to use it with our clients.
The Power of the Pipeline
While I have only touched on a few high-level traits of Fivetran’s ability to synchronize your data in a central warehouse, I think the value of the tool is obvious. In a world where every facet of your business is thriving on data, having a way to centralize what your business runs on is crucial. Not only have they thought of almost everything you will run into loading data, but they also have really done an amazing job creating sleek and intuitive UI that makes the tool simple for anybody to use.
With the ability to create custom web connectors using AWS Lambda or Google Cloud functions and hundreds of connectors already developed, the process of centralizing your reporting environment couldn’t be simpler. Fivetran is designed by analysts, for analysts, and is a crucial piece to getting the most out of your cloud data warehouse.
If you have any questions about Fivetran or how to sync data to a warehouse across your business, please feel free to reach out below!