
Variables are a fundamental part of all programming languages, giving developers a flexible object in which they can store, update and retrieve data. What makes them extra useful in DPC is that the value of a variable can be set and updated using Python, the Update Scalar component or via a Grid Iterator that cycles through items in a list (more on that later).
My colleague Barbara has provided an overview of variables in Matillion ETL, so this blog will focus on how to use variables in the Matillion DPC (Data Productivity Cloud) Designer tool.
Variables in Matillion DPC are created within the pipeline canvas using this section on the left:
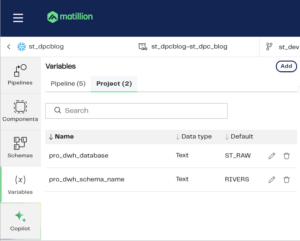
In this example, I have two project variables and five pipeline variables which are visible because I have a pipeline open in my canvas. The terms “project” and “pipeline” refer to the scope of the variables where a Project variable can be used throughout any pipeline in a project (a Project in Matillion DPC is a collection of resources such as orchestration and transformation pipelines, environment settings, authentication settings and schedules) and a Pipeline variable is limited to an orchestration or transformation pipeline.
In Barbara’s blog, she covers the following Matillion ETL variable types, and in Matillion DPC, these are roughly their equivalents:
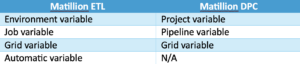
Note: At the time of writing, there are no equivalent Automatic variables in DPC — however, a feature that would be close to equivalent is in the roadmap.
When you click “Add” in the variable section (top right of image above) you’re shown a popup window where you can select the variable scope and type:
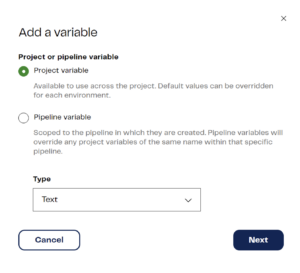
The types available to you are “Text,” “Number” and, for pipeline variables only, “Grid.”
The image below shows the two possible next screens, dependent on whether you selected Project variable (left) or Pipeline variable (right):
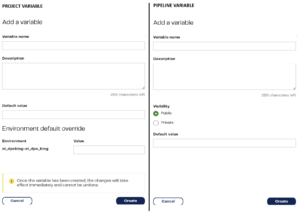
Both options ask for a variable name (keep these unique for the scope i.e. don’t create two variables in the same pipeline or project with the same name.) which can include letters, digits and underscores, but can’t begin with a digit. You can add a description which is optional, but the default value must be specified. This default value will be the variable’s state when the pipeline begins but can always be modified by pipeline components.
The “Environment default override” value for Project variables allows you to set a different default value for different environments. A project can have multiple environments (connections to your cloud data warehouse) against which you can run your pipelines, so if your project variable default value (like a database or schema name) needs to be different for each environment you can specify that here:

The “visibility” option is exclusive to pipeline variables and determines whether pipelines other than the one in which the variable was created can access the variable. Often, you’ll combine transformation pipelines within an orchestration pipeline, and by making a variable “public,” it can accept input values from components within the parent orchestration pipeline.
Grid variables hold a two dimensional table of values and, when creating them, you specify the number, names and data types of each column and can then add a series of default values if required. To dynamically populate the values within a pipeline, you can use the Query Result to Grid component or use a Python Script component in which you can read and update the grid variable as an array.
Once your variable is created, you can use it as a property value in components using the following syntax to call it. For example, if my variable is named “dev_schema,” I can refer to it using ${dev_schema} .
Example Workflow with Variables
I’d like to retrieve data from the Environment Agency flood monitoring API from two endpoints, one that returns information about the measuring stations and one that provides the river height values every 15 minutes from those stations. I’d like to write the JSON returned to my snowflake database and parse out certain items into tables.
The two endpoints are:
- http://environment.data.gov.uk/flood-monitoring/id/stations
- This returns JSON data with ALL stations in the UK, I only want the stations for certain rivers so I’ll be using the URL filter ?riverName=MyRiverName
- http://environment.data.gov.uk/flood-monitoring/id/stations/{id}/readings
- This returns the readings for a single monitoring station specified by the {id} element. The monitoring station ID or reference can be found in the stations endpoint above. You can choose to only return values for a certain day so I’m using the URL filter here of ?startdate=’2024-06-15’&enddate=’2024-06-16’
To connect to these APIs, I built a single custom connector in Matillion DPC containing endpoints for both URLs above. For the station endpoint, I added a Query Parameter (i.e. an item to append to the URL at run time) for riverName, and for the readings endpoint, I added query parameters for startdate and enddate and a URI parameter (something to be inserted into the URL not appended) for the station_id. Here’s an example of the readings endpoint:
This is relevant, as I’m going to use pipeline variables to dynamically update both the riverName query parameter and the station_id URI parameter.
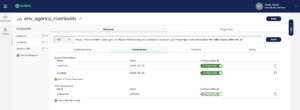
I want to choose three rivers and hit the stations’ endpoint to return all station information for those three rivers. To do that, I’ve created a Grid variable to hold the river names with two columns: one with the river name as it needs to be appended to the URL and another column to hold the suffix I’ll add to the table name in Snowflake. I needed to do this because table names can’t have spaces in them, but the river names for the URL have spaces. These are the settings for my Grid variable:
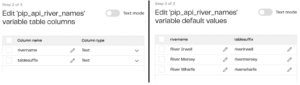
I can only use one item at a time from my Grid variable, so I need other pipeline variables to hold the current River Name and table suffix items from the grid list (these names don’t follow any standard convention — I’ve added “_fromgrid” so I understand I’m populating them from a grid variable):

In the configuration settings for the environment agency connector, I’m using the river name variable here:
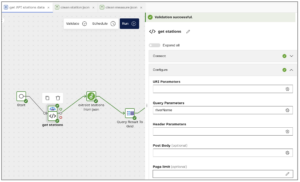
If I open the Query Parameters section, I can add my variable name there:

And in the destination section, I’ve used multiple variables:
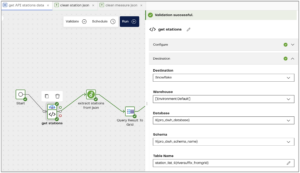
I’ve added my riversuffix_fromgrid variable to the end of the table name to make it unique for each river. I’m also using two project level variables: pro_dwh_database and pro_dwh_schema_name. You’ll quite often need to specify warehouse, database and schema within components, so if I want to move my pipelines from targeting a dev database to a production one there are a lot of settings to update. If, however, I make my database and schema variables, I only have to change those once to update all components.
What enables this connector to cycle through different river names and put the station data into different tables is the Grid Iterator component. Within this component I specify the Grid variable:
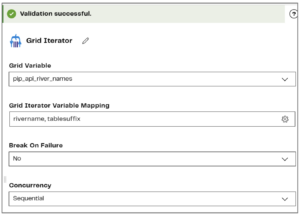
Then set up the variable mapping like this:

Each iteration will pass the rivername and table suffix values from my Grid variable to the rivername_fromgrid and riversuffix_fromgrid variables, which are inserted into the custom API connector.
The next step in my orchestration pipeline runs a small transformation pipeline that unions the three tables of station JSON data into one and extracts information about the stations including a list of station_id values and writes those to a table named stations_all_info:
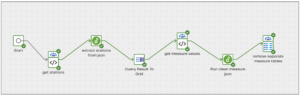
The third component (ignoring the start component), “Query Result to Grid,” passes values from the table created in the transformation pipeline into my second Grid variable “station_ref_grid” using the following settings:
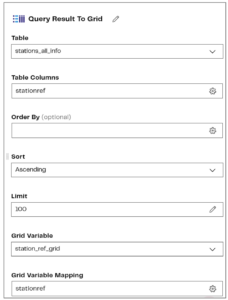
Note that another component “Query Result to Scalar” has a similar function allowing a value returned from querying a table to be passed to a pipeline variable.
As before, I have a separate pipeline variable named “station_ref” into which I’ll pass the values from the station_ref_grid variable using a Grid iterator. That will enable me to trigger the readings endpoint inserting my station_ref variable into the station_id URI parameter and appending to the table name like this:
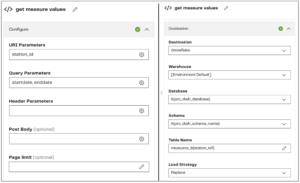

The purpose of my workflow was to retrieve measuring station information for a limited list of rivers and then retrieve reading values only for the measuring stations returned in the first API call. I achieved this with a combination of project and pipeline variables using existing no-code components to dynamically populate and loop through values in grid variables.
I’m not a full time data engineer, but I use this API example as a way of testing how easy it is for me to use a data ingestion/transformation tool as it’s very similar to client work we’ve done in the past. I’ve attempted this exercise with Fivetran, Airbyte, Dataiku, Alteryx Cloud and using a Python script but I found using a Matillion DPC workflow the most straightforward way out of all those options. I think the documentation, which I’ve linked heavily in this blog, is very easy to understand.