The term “Medallion Data Architecture” was first coined by Databricks where they describe data at different stages of processing as being “bronze,” “silver” or “gold” level data. The term has since been used by Microsoft to describe stages of processing within Microsoft Fabric. It can equally be applied to data in other platforms such as Snowflake, RedShift or BigQuery.
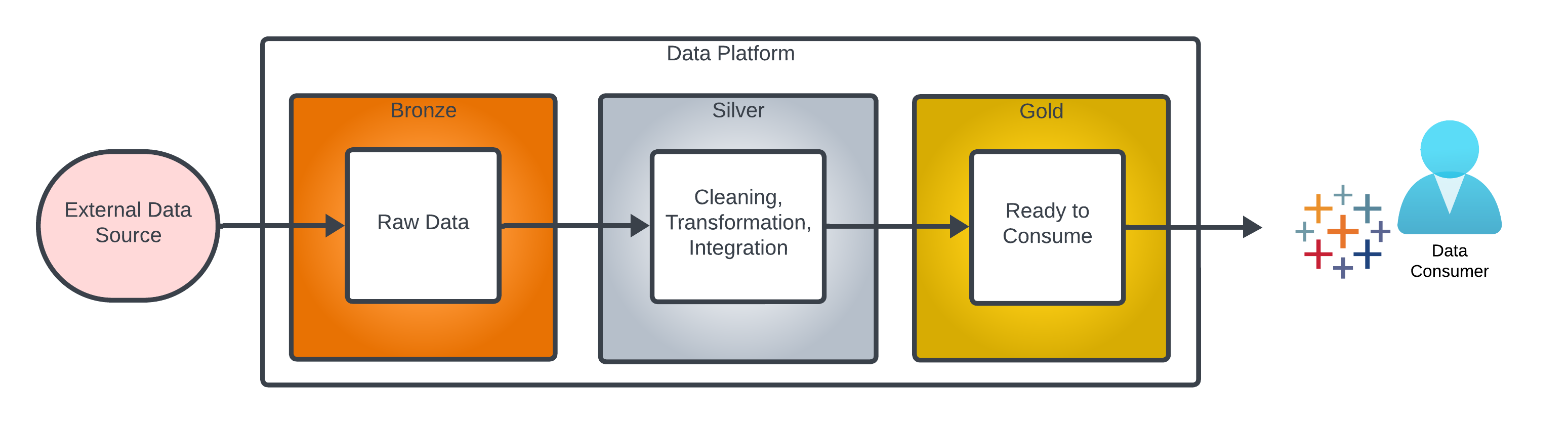
- Bronze data refers to data in its unprocessed state, exactly as loaded from the data source.
- Silver data refers to data at various stages of intermediate processing.
- Gold level data is fully cleaned and prepared ready for use by a data consumer.
Separating the bronze stage from the rest of the architecture means you always have a copy of the data exactly as it was loaded from the data source. If a fault occurs, it allows you to quickly determine if the the problem is related to source data or processing within the data platform.
Separating the gold stage from the rest of architecture insulates your data consumers from the complexities of data ingestion and integration. All they are able to access is the fully cleaned, secured and maybe pre-aggregated data.
At InterWorks, we’ve been implementing staged architectures like this for years, though in the past, we’ve referred to the different stages as “raw,” “integration” and “presentation” or something along those lines, rather than “bronze,” “silver” and “gold.” Stages in data processing don’t seem to have much to do with either Olympic medals or car wash options, but sometimes names just stick.
Snowflake’s cloud data platform is a great place to implement a medallion style data architecture:
- Snowflake SQL extensions can natively handle semi-structured data such as JSON or Parquet, so it’s straightforward to convert things like API data into regular tables.
- The Snowflake system architecture that de-couples storage and compute allows for fast and efficient sharing of data across databases and between Snowflake accounts without having to make separate copies of the data.
- Snowflake dynamic tables allow for efficient incremental processing of data without the need for additional SQL to separate existing and new data.
- Row and column access policies can be applied to any table to hide or mask data that a user is not authorised to see with no need for additional code.
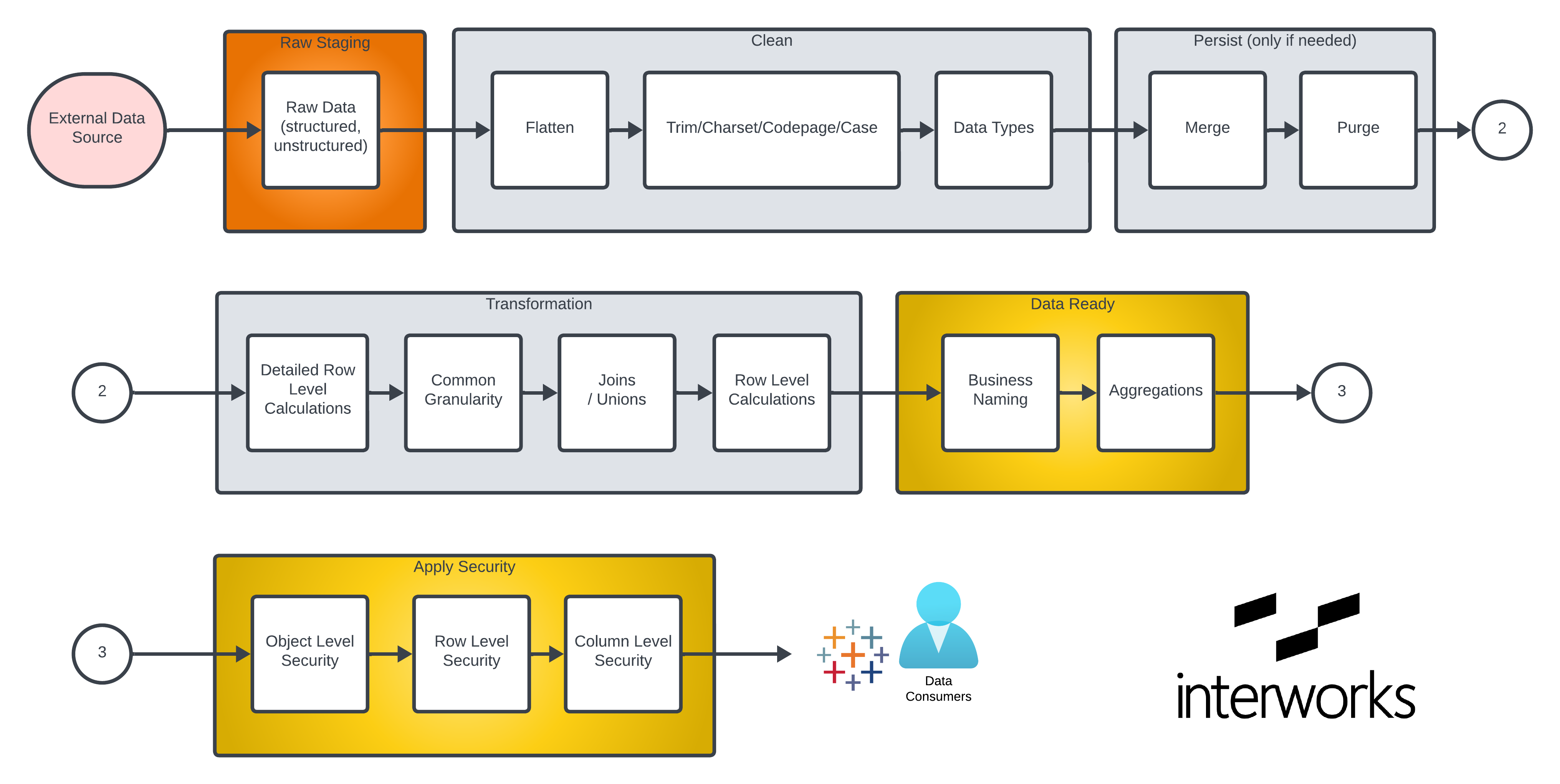
Beyond the three basic stages, there’s value to organising processing in a fixed order. As a data engineer, if you know that data type conversion is done at a particular point, then you don’t have to keep checking or reconverting the data in different places.
If you identify a problem that relates to a particular function, you know just where that processing has occurred.
Overall, an organised medallion data architecture will make your data platform more efficient and easier to maintain, ultimately reducing its cost.
Here’s what a medallion data architecture might look like with data processed in a structured way.