
The Day Before: Bringing our Snowflake Data into Tableau
As the week began, we entered the development stage of our big intern project. My role thus far has been preparing for development by creating wireframes for the new dashboards.
For this project, we used a Snowflake-held data source which we would pull into Tableau and ThoughtSpot for development. The main table is rather large, with almost three billion rows. Naturally, I go for an extra-large snowflake data warehouse to cut loading times down while pulling the data into Tableau.
Everything started well. I recreated the joins of the star schema to the main table and the corresponding dimension tables in Tableau and made my first dashboard. As I continued developing, I wanted to take a deeper look into my joins and make sure they were as expected. In the process, I joined another large table to the main table. I quickly realized I chose the wrong table and canceled the query. Soon after, I left for the day and thought nothing of it again… until we realized the next day.
The Mess Up: A Mega Join Causing Long Snowflake Queries
First thing in the morning, I received a message saying that our project’s warehouse had used over seventy percent of our usual monthly usage on this internal account. We were only ten days into the month at the time. My team and I met to discuss possibilities and solutions. Initially, we were not aware of the effects. We started to see many more messages pop up from different InterWorkers. This is when we started to realize the scale of the mistake since it affected many other teams using the internal account as well. As we were brainstorming what could’ve caused this many credits to be used, I received a message with a screenshot of two fourteen-hour queries that ran on an extra-large warehouse, created by me.
As soon as we located the issue, the questions turned into solutions. Many InterWorkers came to me with assurance and positivity. Ty Ketchum, a Delivery Lead, brought our attention to the problem queries. In Ty’s message, he made it clear that everything was okay and fixable. This immediately calmed my nerves. With a quick meeting with Brooks Barth, a Service Lead, we were able to find solutions and prevent future hiccups. Brooks was able to dissect the SQL query to determine that the join I thought I canceled kept querying in Snowflake. Since I didn’t use the proper join keys, Snowflake was trying to join two large datasets that would ultimately create forty-five trillion rows (That’s 45,000,000,000,000 rows, for context.) The fourteen-hour queries ate around five hundred Snowflake Compute Credits in two days.
The Takeaways
Checking Snowflake Query History
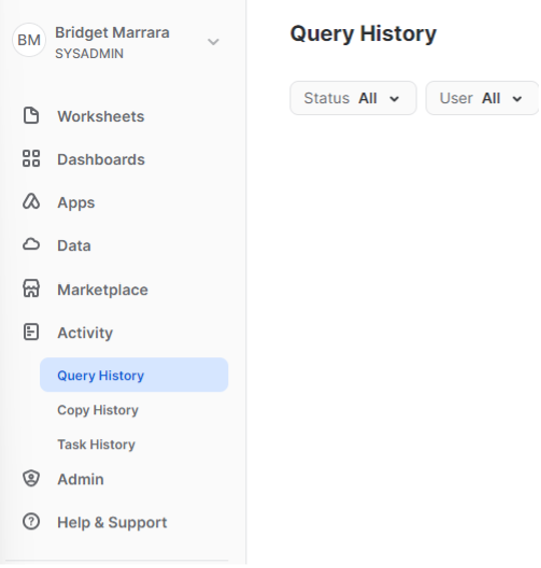
After the incident, I watched the query history in Snowflake like a hawk. Though constant checking is not necessary, it is important to check that queries are running and canceling as expected, even if it’s just for your peace of mind. To check the query history on Snowflake, navigate to the Activity tab on the menu on the left of the interface. Then, press the ”Query History” tab as shown below. On this page, you can filter by status, user, date, and much more:
Understanding Snowflake Warehouse Sizes and Credit Consumption
Another takeaway I learned is to switch to the lowest Snowflake warehouse size that is functional for your task. Once I pulled the data into Tableau, I could’ve switched it down to a medium or small warehouse. This would’ve minimized the credits that were used in this incident. To learn more about Snowflake’s usage, check out Holt Calder’s blog: “Introducing the Snowflake Data Cloud: Modern Data Warehouse.” For understanding how credits correlate to cost, see “Understanding Compute Cost, a Snowflake Guide.”
Using All Join Keys when Joining Data in Tableau
Aside from Snowflake’s capabilities, I learned a valuable lesson to use all join keys needed for a seamless join. In this case, I pulled in a table that caused a mega forty-five trillion row dataset to be created. If done correctly, the row count would’ve stayed close to the original three billion. The picture below, posted on Tableau’s help forum, defines a Left Join.

Since I didn’t use all of the necessary join keys, the data from the right table was duplicated… a lot. The graphic below is an example of this event:
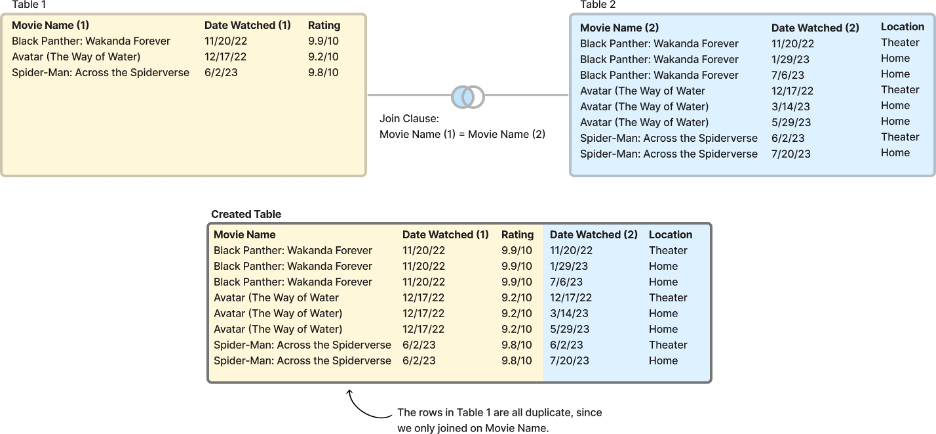
In this example, the join clause tells Tableau to add the rows from Table 2 to Table 1 when the values in the “Movie Name” column match. When only joining on this key, Table 1 has duplicate data in the new table. In my case, this happened on a much larger scale.
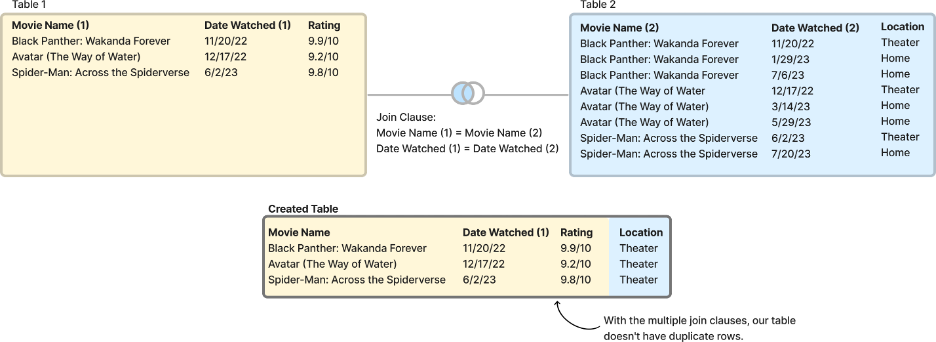
If I wanted to join the tables, I should’ve used multiple join clauses that would’ve prevented the duplication of rows. In the below example, the table that is created using two join keys, “Movie Name” and “Date,” does not have duplicated data and reads as expected. This is called a composite primary key:
To learn more about types of joins and how they work, look into the Combining Data with Joins blog by Zac Heacker.
InterWorks’ Attitude Towards Mishaps
Of the many lessons I learned, one stood out to me the most: Though for a moment I thought the world might end, my coworkers kept supporting me through the entire process. Not only was I met with empathy and kindness, but also solutions and suggestions. During our onboarding process, we were told that mistakes are just opportunities to learn. Months later, I know that InterWorks truly practices that motto.