
In my last blog, I discussed how to do an Upsert in Snowflake using Matillion. Using the same workflow, I will discuss how we got the key value using the MD5 hash functionality available in Snowflake and why we need to do it. The why is easy, so let’s start there. The MD5 gives us a key value that we can use to reference back from the Fact tables in our data warehouse to the Dimension tables.
If you’re wondering why we need a surrogate key (SK) at all, you’re probably not alone. We use a surrogate key for join performance. Using a surrogate key is faster when joining two tables than using multiple columns in your join statement. This makes writing your queries a little faster while improving the performance of your query, and who doesn’t want that?
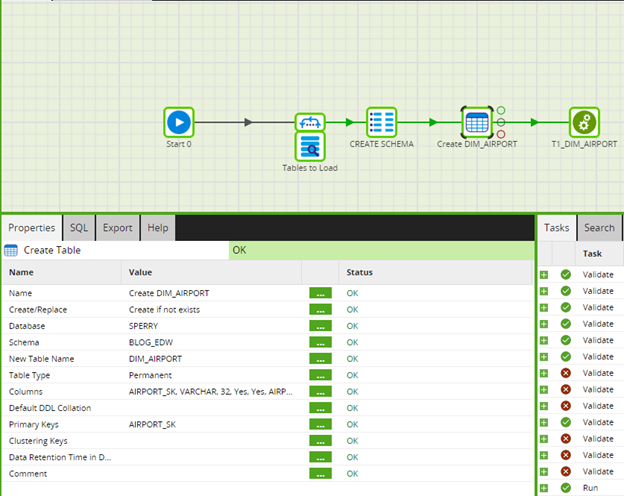
Here is a quick overview of what the workflow will look like when we finish:
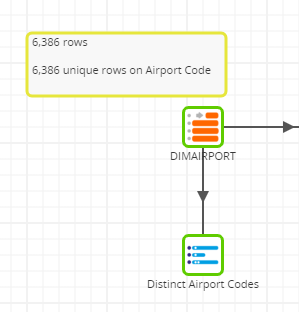
Our first step is to make sure we understand which column, or combination of columns, gives us a unique value. In this case, it is the Airport Code column.
Now we simply need to bring in a Calculator tool onto the canvas:
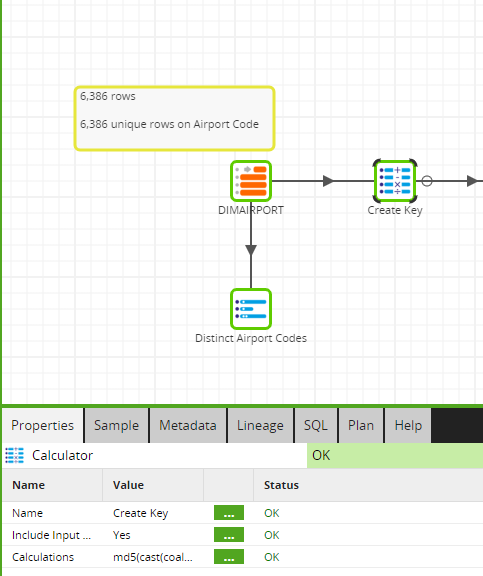
Finally, we write the code below to create our key. A quick note on the COALESCE function in the code: We use this so that, in the event of a null value in the unique field, you will still get a unique key value.

Just as a check, you will want to do a row count on your key value to make sure that you truly have a unique key. After performing this check, you can now refer to my last blog to create your Upsert. Once all of that is completed, you simply need to create the table and run the Upsert. Before creating your table, simply pull out a Rename tool in your Transformation canvas where you have created your key and rename your columns. Then, select the Metadata tab and check the Text Mode box.
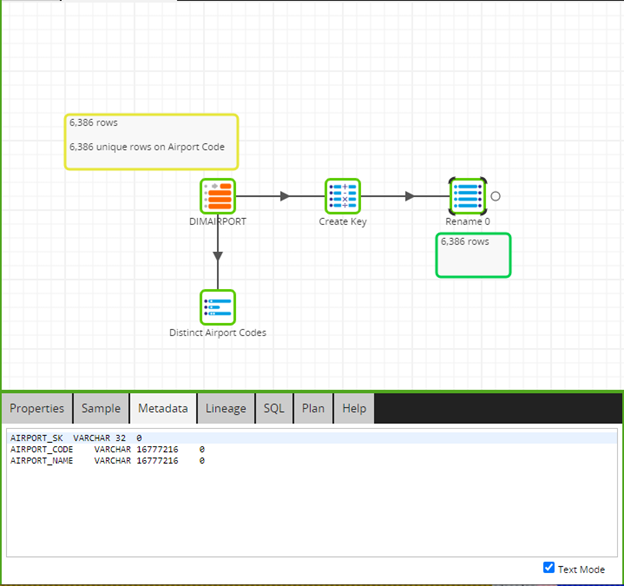
This will allow you to copy the Metadata of the table.
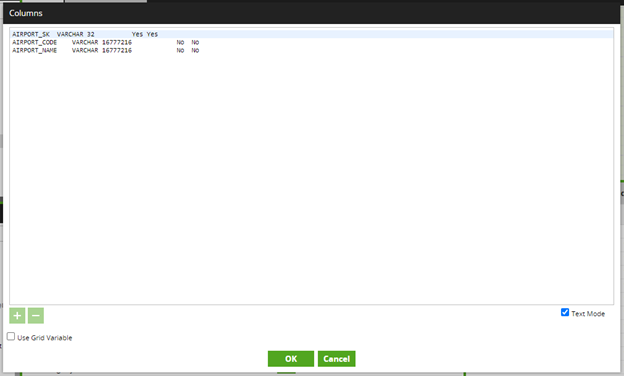
You can now paste this information into your Create Table tool in the Orchestration. While this may not help much with a small table like this, it can be a real time-saver with larger tables.
A Quick Disclaimer on Potential Collisions
When using the MD5 hash, keep in mind that, like any solution, the amount of data you have will determine whether or not this is an appropriate solution. For instance: There is a rare chance of collision. On average, you would need 2^64 records before you get a single collision though. In short, if you have a quintillion records in your table, hashing may not be the right way to go.
This number takes into account the “birthday paradox,” which I will link an explanation to below. The number of records you would need before a collision without the birthday paradox is 2^128, or 340 undecillion 282 decillion 366 nonillion 920 octillion 938 septillion 463 sextillion 463 quintillion 374 quadrillion 607 trillion 431 billion 768 million 211 thousand 456 (I only typed all that out because it seemed like fun).
Here are the links to a few articles to further explain all of this:
https://discourse.getdbt.com/t/avoiding-collisions-during-md5-surrogate-key-creation/4727
https://stackoverflow.com/questions/201705/how-many-random-elements-before-md5-produces-collisions
And here is a fun calculator you can use to get the numbers for things like 2^128:
https://www.wolframalpha.com/input/?i=2%5E128
If you’re a nerd (like me and at least one of my coworkers), here’s some information about the “birthday paradox:”