
Transferring datasets via email is definitely not ideal, and while we try to avoid it as much as we can, there are occasions where our data providers do not have the resources to provide their datasets any other way. Maybe they are able to implement better, more elegant ways of providing their data such as APIs, file drops in cloud platforms like AWS or Azure, or DB accesses; but setting this up takes time, and they might not be prepared to deploy this immediately. The data refreshed in a daily fashion might be urgently required, making a workaround using email attachments data necessary.
Whatever the reason might be, if the need arises to stage email attachment data, Matillion comes to the rescue. With an easy recipe, we will be able to have our data staged in Snowflake, ready to be integrated with our other data sources and prepared for final consumption.
Stage the Email Details
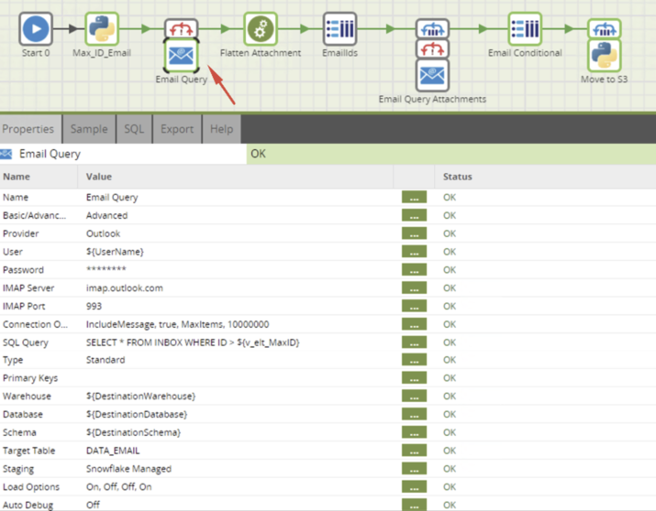
Use the Matillion component Email Query to obtain the full details of the email and stage it in a table, which in our example is called DATA_EMAIL.
Important: There are two important connection parameters you might want to use:
- IncludeMessage = true allows you to download the message body content and attachment data.
- MaxItems = 500 is the maximum number of emails to be staged from most recent to oldest. The default is 100, so if you don’t modify this, it will always be giving you the latest 100 emails.
Pro Tip: Due to performance, you would like to avoid going for the full email dataset every time you run your pipeline. In a benchmark testing, doing an extraction where maxitems = 100 was completed in under 1.5 minutes, while an extraction on the same dataset with maxitems = 1,000 is completed in 14 minutes.
Ideally, you will stage the emails and perform incremental loads based on the email ID being greater than the max email ID in your database. For this purpose, we obtain in a Python component the max ID and save it in a job variable (in our example: v_elt_MaxID) to be used in the Email Query.
You can use the following Python code for this purpose:
cur = context.cursor()
qry_maxid = '''
SELECT IFNULL(MAX(ID),0)
FROM "${DestinationDatabase}"."${DestinationSchema}"."${DestinationTableName}_2"
'''
cur.execute(qry_maxid)
qry_rows_inserted = cur.fetchone()[0]
context.updateVariable('v_elt_MaxID',qry_rows_inserted)
print('Variable v_elt_MaxID has been updated to {0}'.format(qry_rows_inserted))
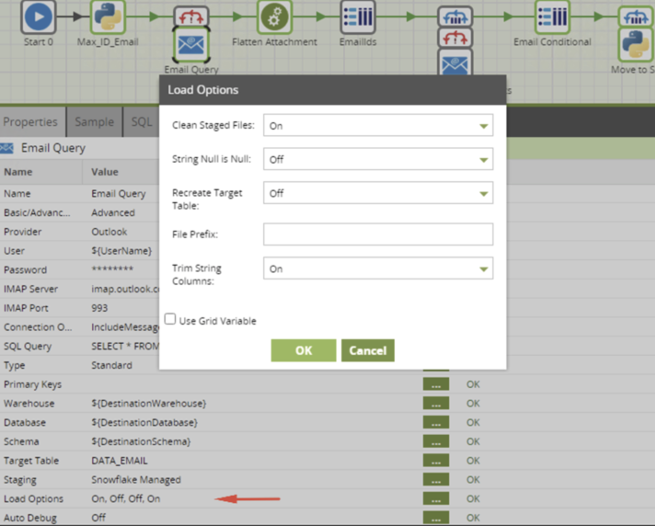
Also, make sure that your Email Query Load Options has set Recreate Target Table to Off:
Flatten the List of Attachments
For the emails that contain multiple attachments, this list will appear in your field DATA_EMAIL.ATTACHMENTS as a semicolon separated varchar. For example:
- ~WRD0001.jpg; image001.jpg; CustomerData_20210101.xlsx; image (23).png; DailySales_20210101.csv
We will need individual file names later on, so the next step here is to flatten out this ATTACHMENTS field:
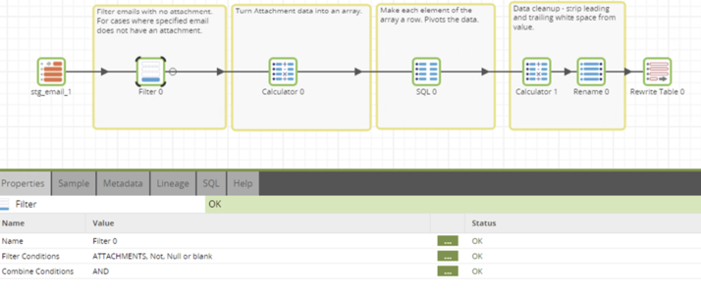

Below is the SQL script:
SELECT
att.VALUE
,ft.*
FROM "${DestinationDatabase}"."${DestinationSchema}"."${DestinationTableName}_2" ft
,lateral flatten(input => SPLIT("ATTACHMENTS",';'), outer => true) att

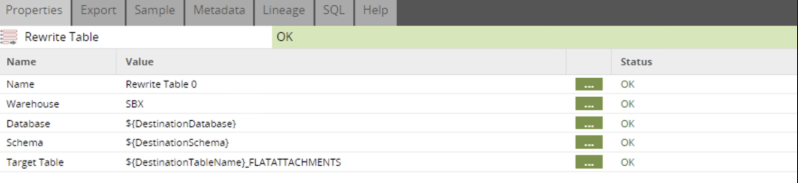
The resulting table, DATA_EMAIL_FLATATTACHMENTS, will contain one attachment per row. This table will be used later on to loop through it and obtain the file name that will be moved from the folder to a cloud storage location, such as S3.
Stage the Attachments Per Email ID
The next step is where we download the files into a Matillion box folder and/or the attachment content encoded into a Snowflake field. In our example, the table where we are downloading the attachment data is DATA_EMAIL_ATTACHMENTS.
Again, for performance reasons, it is recommended to download the data from the emails that we haven’t downloaded. For this, we will use a Query to Grid component to obtain the email IDs that we haven’t processed in DATA_EMAIL_ATTACHMENTS:
/*Query to obtain the list of Email IDs to loop through them and retrieve the attachment*/
SELECT ID
FROM "${DestinationDatabase}"."${DestinationSchema}"."DATA_EMAIL"
WHERE ID NOT IN
(SELECT ID
FROM "${DestinationDatabase}"."${DestinationSchema}"."DATA_EMAIL_ATTACHMENTS"
GROUP BY ID)
GROUP BY 1
This ID gets mapped and used in a Grid Iterator to be used in the Email Query component to download the attachments:
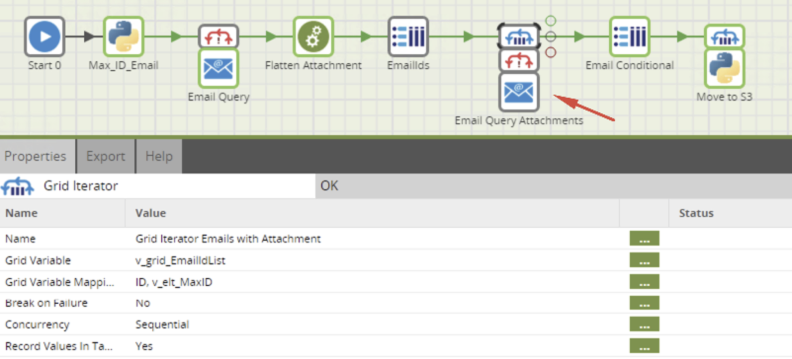
It is important to note that to download attachments, it is necessary to specify in the query a specific email ID. That’s why the Grid Iterator is required to go through the IDs and save extracted data in a table (in our example, DATA_EMAIL_ATTACHMENTS). Remember to verify that the component Load Options has set Recreate Target Table to Off.
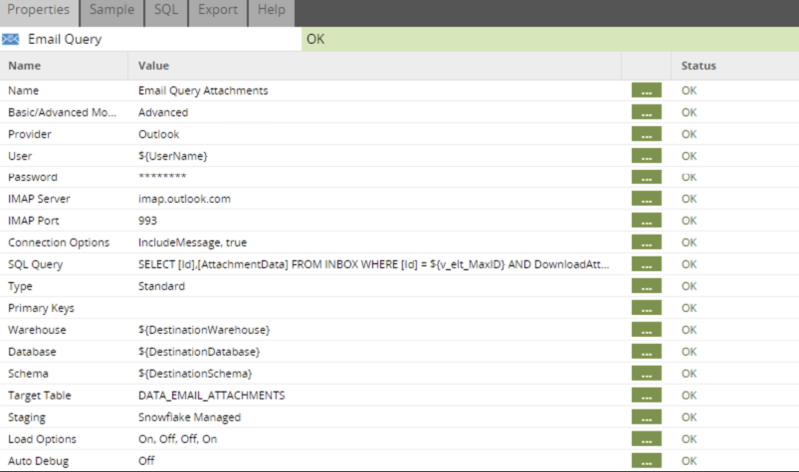
The query to be used in the Email Query component is:
SELECT [Id],[AttachmentData] FROM INBOX
WHERE [Id] = ${v_elt_MaxID}
AND DownloadAttachments = 'true'
AND AttachmentFolder = '/data/emailattachments/'
You will need to create the folder in your Matillion box as required. In this example, it is ‘/data/emailattachments/’.
Pro Tip: If you don’t need to download the physical file and just need the encoded string in Snowflake table, simply delete the clause “AND AttachmentFolder = ‘/data/emailattachments/’“ in the email query; if you are using this clause, the table will show the string ‘Saved to: /data/emailattachments/’. The field AttachmentData in DATA_EMAIL_ATTACHMENTS will be encoded. You can use the Snowflake function TRY_BASE64_DECODE_STRING(<input> [, <alphabet>]) to decode it to plain text.
This is useful to be used directly on the table if the attachment is a small single text file (tab, comma or text separated) and no further processing is required:
SELECT
D.ID,
Y.VALUE::VARCHAR() as CONTENTS
FROM {DestinationDatabase}.{DestinationSchema}."DATA_EMAIL_ATTACHMENTS" D,
LATERAL FLATTEN (INPUT => SPLIT(try_base64_decode_string(D.ATTACHMENTDATA) , '\n')) Y;
Move the Files to Cloud Storage
The last step will be to move your downloaded attachments to a cloud storage location such an S3 bucket for further processing. In this example, we only want to further process the attachments that come from a specific email address. For this, we will use a Grid to Query component in combination with a Query Iterator to loop through the name of the files that we require to move:
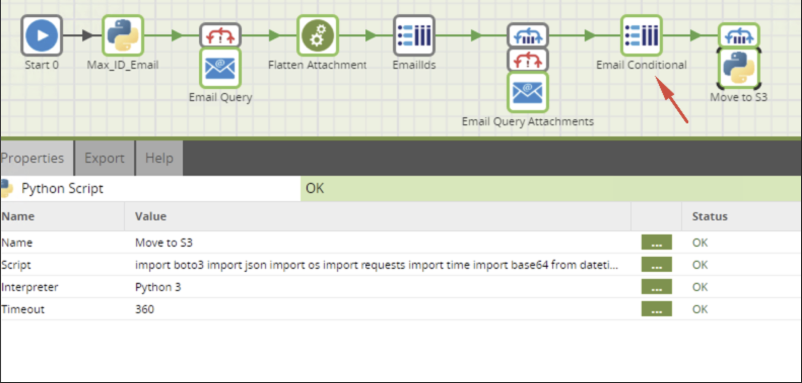
The Email Conditional component will have the conditions of the emails you want to further process:
SELECT ATTACHMENTS FROM
${DestinationDatabase}."EMAIL"."DATA_EMAIL_FLATATTACHMENTS" ft
WHERE "FROM" = 'vip_emails@important.com'
The attachment emails will be passed to the variable ${jv_curr_attachment} and later used in the Python component that moves to S3:
import boto3
import os
###########
# CONFIGS #
###########
# AWS Simple Storage Service client
s3 = boto3.client('s3')
def main():
os.chdir('/data/emailattachments/')
currfile = '${jv_curr_attachment}'
s3.upload_file(currfile,'mybucket','myfolder/'+currfile)
if __name__ == '__main__':
main()
From here, you can further process your files as required.
Voila! There it is. Now, with Matillion and Snowflake, you can automate the dreaded email attachments. Happy pipeline building! If you have any further questions, please do not hesitate to reach out to myself or the InterWorks team! We’d love to help.