
2020 has been filled with unexpected surprises. From the global pandemic we find ourselves in to the disappearance of the business travel I had grown to love, the way this year has wrapped up was not at all expected. While the days of traveling to a high-energy tech conference might be on pause, there has been an unintended benefit of this year: we were able to have not one but TWO Snowflake virtual conferences! The first virtual conference in July set the stage for what to expect from these events.
Encore! Snowflake Data Cloud Summit, Take 2
The first iteration of the virtual Data Cloud Summit made it pretty clear that these sessions weren’t fluff filled with empty promises or unachievable goals. I recall sitting in my home office scrambling to keep up with the pace of innovation being revealed in the technical demonstrations. Those demos followed this pattern:
- “Let me introduce to you this new feature that expands the capabilities of our platform exponentially.”
- “Here is a basic use case for how this feature works.”
- “Congrats! This feature is currently available to all accounts in preview. Enjoy tinkering.”
- Holt faints while the world as he knows it drastically changes before his own eyes.
Well … that last point might be a little bit dramatic, but you get the point. The first conference set the tone for what we have come to expect from Snowflake events: thought leadership, valuable innovation and thoughtful presentations of features that are actually ready to use. If you missed the conference, you can watch the playback here.
Highlights from Our Time in the Cloud
This new Snowflake virtual conference took the momentum from July and delivered an experience that emulated the big stage in Vegas. In the Summit, we were given a direct lens into Snowflake’s vision of the data cloud and the features coming to deliver that vision. On top of that, we heard countless customer success stories with insights into how organizations are using Snowflake in unique ways to deliver business value.
If you only have time to watch one session, I highly recommend The Rise of the Data Cloud with Frank Slootman, Snowflake’s CEO. Frank does an incredible job setting the stage for how the pandemic has supercharged digital transformation, and he introduces the idea of the time value of data. Something we’ve always been aware of but have never quite put into words is that the actionable value of data decreases as it ages. The vision of Snowflake is alive and well: the cloud data platform that businesses can rely on is foundational to the software and essential to their mission.
New Features Coming Soon to Snowflake
My favorite part of these events is seeing what’s coming next. Snowflake introduced these changes along with their new product strategy:
- Data Cloud Content
- Extensible Data Pipelines
- Data Governance
- Platform Performance and Capabilities
You can watch the recording of this session here.
Data Cloud Content
Data sharing has always been at the core of what separates Snowflake from the other cloud warehouse vendors. As the data marketplace has grown, it is obvious that content is the most important piece of the equation. Snowflake views the Data Marketplace as the gateway to the Data Cloud. Currently, there are a little over 100 data providers on the Marketplace, and it is clear that this is an area that will continue to be expanded.
Extensible Data Pipelines
This area of the platform saw a significant boost early in the year with the introduction of external functions—the ability to bring data from Snowflake to external processing engines like cloud functions. During the Data Cloud Summit, they brought some of those capabilities inside of Snowflake by announcing that Snowflake Functions and Procedures will be able to support SQL, Java, Scala and Python programming languages in the future. Bringing these programming languages into Snowflake allows organizations to author transformations in the programming language of their choice. There was no launch date mentioned for these new programming languages in Snowflake, so we’ll stay on the edge of our seats until then!
The most exciting announcement in this space is the introduction of SnowPark: a family of libraries that will bring a new experience of programming data in Snowflake. SnowPark allows organizations to write code directly against Snowflake using familiar concepts like data frames, removing the barrier to run data-science and machine-learning workloads in the Cloud Data Platform. The most exciting part of SnowPark is that from the ground up, it integrates with the things we know and love about Snowflake to deliver unmatched performance in this new use case. SnowPark has libraries available in Python, Scala and Java and is available in testing environments only right now:
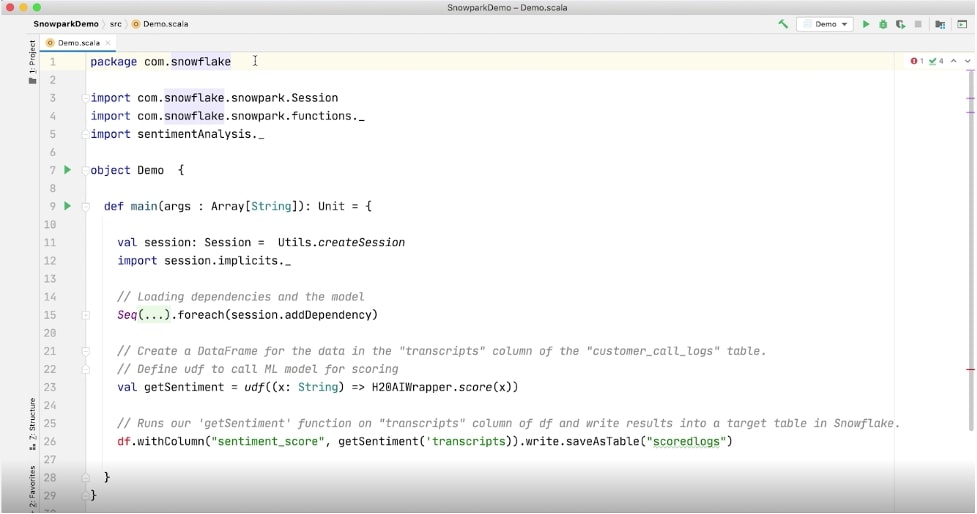
Above: SnowPark demo from the Data Cloud Summit
Data Governance
Security has always been a primary conversation topic for Snowflake. A part of security that Snowflake has really executed well is the concept of data governance, and that area of the platform continues to grow. The announcement of tagging is welcomed by Snowflake practitioners far and wide. Tagging unlocks the potential to annotate warehouses with cost center information, group resources into projects, and mark columns with sensitive information for easy masking. Tagging is industry standard in other cloud platforms, so seeing its introduction to the data cloud makes perfect sense.
Another introduction into Snowflake’s data governance suite is the Row Access Policy. Similar to Snowflake’s Masking Policies introduced earlier this year, Row Access Policies introduce the ability to achieve row-level security within Snowflake in an easy-to-maintain fashion. Keep an eye out on the InterWorks blog for future posts about how these features work from a technical perspective!
Platform Performance & Capabilities
This section of the product roadmap is honestly the one I am happiest to see. Snowflake defines this as the way they improve the core platform and expand its capabilities based on customer feedback. This section contains quite a bit of statistics about general performance improvements, along with the announcement of the new Query Acceleration Service. This is a really interesting concept. Essentially, you define in your virtual warehouse a maximum number of resources that you would want to make available, and Snowflake auto-magically spins up additional resources for complex queries that could benefit from parallelization. The concept of letting Snowflake provision resources to meet the need of your query is truly what I think of when I hear the term “as a Service”, and the Query Acceleration Service is something users should certainly keep their eyes on as it rolls into public preview.
Snowflake’s Impact on the Future of Data
Looking at Snowflake’s announcements and product launches makes it clear that the Data Cloud is here to execute on a strategy much larger than data warehousing; it’s much larger than even their IPO. Snowflake is here to fundamentally change the way organizations work with and power their businesses with data. Expanding the platform’s ability to service data science workloads through SnowPark is a huge step in the right direction towards unifying what has historically been a separate line of thought with a separate set of tools.
Looking Back, Looking Ahead
Watching Snowflake grow over my time at InterWorks has been an eye-opening experience. Seeing an organization execute its vision is motivating, and our partnership with Snowflake couldn’t be thriving more due to their investment in features, mission and customers.
If you are reading this and are curious about Snowflake, please feel free to reach out to me. I look forward to many more of these Snowflake Summit write-ups. I genuinely have no clue what’s next for the Data Cloud, but I am confident it will be something great!