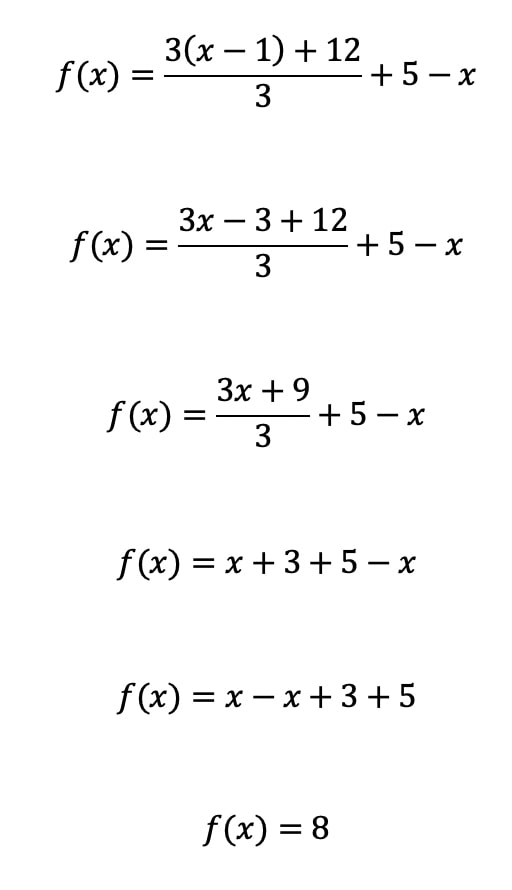Ready for some magic?
Think of a number.
Subtract 1.
Multiply the result by 3.
Add 12.
Divide that number by 3.
Add 5.
Subtract the original number you thought of.
And the answer is … 8
It’s a pretty rubbish magic trick, and, of course, the answer is always 8 regardless of the starting number, but it’s a neat illustration of an algorithm: a step-by-step set of instructions to get from some starting data to a final output.
The magic trick relies on the fact that when laid out in this algorithmic fashion, even a simple process can be quite opaque. Most of us were first taught to program using exactly these kinds of step-by-step instructions. Did the first computer program you ever wrote look something like this?

This algorithmic style of coding is more formally called imperative programming, and it’s everywhere. It’s the way that most of the world’s software works today, and much of it is similarly opaque. In a real-world context, of course, the programs are much more complex, harder to debug, and the consequences of errors can be far more serious.
Real-World Examples
In December 2019, the UK Post office paid £58 million in compensation to 550 former postmasters who were wrongfully accused of theft after shortfalls were found in the post office counters accounts system. The British High Court found that the software system being used had defects that had directly led to the shortfalls.
While I have no direct experience of working with the Post Office, I think this situation is more common than we would like to believe. In my 20 years of experience working as a data consultant for commercial and government organisations around the world, I have seen numerous instances where the accounting systems contained buggy imperative code and inadvertent errors that led to the organisation misreporting their financial position. These errors can remain undetected for years and can lead to large historic liabilities when they are eventually discovered.
What Alternative Is There?
Let us go back to the magic trick. What if we restate the logic using a mathematical function rather than an algorithm? In this case, x represents the number we first thought of and f(x) is the result:
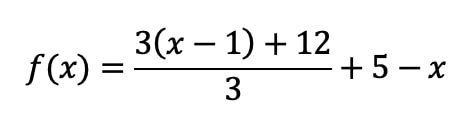
When expressed in this way, we can apply regular algebraic techniques to simplify the expression. In this case, most of the elements cancel each other out, and we are left with:
![]()
Note: If you wish to see the full working, I’ve included it at the end of this post.
We’ve rather killed the magic, but the simplified function is much clearer and, more importantly, mathematically provable. In a larger system, logic expressed this way is free of side effects, and if any errors are found, we can precisely trace how any particular value is calculated. Errors can still happen, but they are contained and more easily discovered and fixed.
This style of programming (known as functional or declarative programming) is common in safety-critical settings such as the aerospace industry but is only now becoming widely used in business intelligence. Where the data produced is used as the basis for high-stakes decisions, the added reliability of traceable, side-effect free declarative code can be hugely valuable.
Declarative Programming in Business Intelligence
In the context of a modern data warehouse such as Snowflake, it is possible to implement complex logic with no imperative code at all. Features such as common table expressions, views and user-defined functions allow us to specify the required output purely in terms of the available inputs. Databases and data warehouses use a built-in query planner function to find the optimal way to process the code based on the hardware available and statistical information about the data being processed.
Managing Performance
In some cases, the declarative style can lead to identical calculations being executed repeatedly on the fly and thus slowing the whole thing down. This can be managed by making proper use of caching, materialised views and simple CTAS tasks (which render an exact copy of a view to a table purely to improve performance). Sometimes, declarative code will run faster than the equivalent imperative code as it can more easily take advantage of the parallel processing potential of modern hardware.
Greater Efficiency
Giving the software more freedom to manage its own processing has additional advantages. It can employ different strategies to take account of the available hardware and the characteristics of the data being processed.
In the same way that a chess program can outperform a human player by selecting the best move from many thousands of alternatives, so the in-built query planner function in a data warehouse can work out an optimal set of steps to get to the required output most efficiently. In a cloud data warehouse where processing is priced by the processor/second, code that runs more efficiently will directly save money.
The impact is not just financial. In the end, more efficient code means less electricity powering less silicon. It is predicted that the world’s data centres will be responsible for around 3.2% of global carbon emissions by 2025. Using smarter programming techniques to reduce this figure can only be a good thing.
Looking for More Help?
Thank you for taking the time to read this post. If you would like more information about how to manage your critical processing using this declarative approach, or more general advice about modernising your data warehouse, contact us for an informal chat. We’d love to help you.
Appendix – The Rest of the Owl
Here is the complete step-by-step simplification of the magic trick function. If your algebra is a little rusty, not to worry. Websites like mathpapa can do it for you. The fact that a computer can reliably do this simplification for you and you really don’t need to understand the process in detail is part of the point.