
The wheel. The lightbulb. The internet. Dataiku. All revolutionary creations that disrupted life itself. Okay, well, maybe Dataiku won’t disrupt life itself. It will, however, continue to push the data industry in a great direction.
So, what is Dataiku? It’s a company that develops collaborative data science software called the Data Science Studio (DSS). DSS is loaded onto a server that allows for maximum collaboration and comes with loads of features that support everything from ETL to scoring and deploying robust machine learning models without having to touch code—unless you want to.
Automation Scenarios
The feature we’re going to explore in this post is automation scenarios. These scenarios are a set of actions you define that can be triggered in a few different ways. You want your data to update at the top of every hour? Create a scenario for that. You want to run some Python code when you upload new data? Create a scenario for that. You want to train a machine learning model every time a button on your web page is clicked? It’s scenario time.
For our demo, we’ll retrieve New Orleans, LA (NOLA) weather data from the Dark Sky API, do some data preparation to get the schema where we want it and add the data to a table in Snowflake. We’ll then set up a scenario to build the dataset and add the new data to the Snowflake table every hour. The flow looks like this:
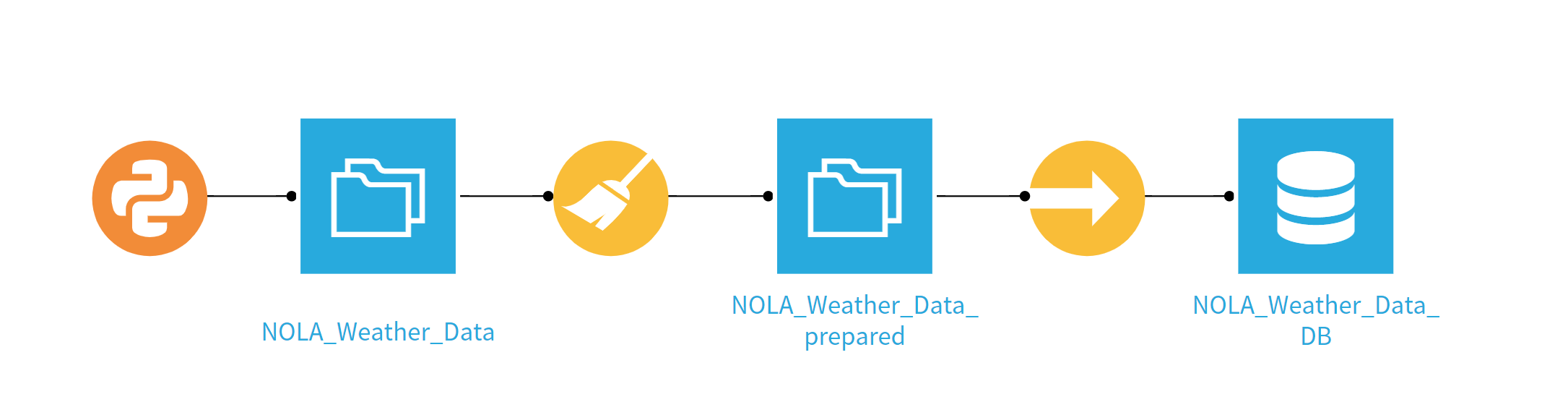
Let’s build this thing! We chose to use the Python script as opposed to the HTTP input because the Dark Sky API returns more information than we want (current and forecasted weather), and the script allows us to be selective. Quick note: a huge selling point for Dataiku is the many built-in features that allow you to avoid coding altogether, but you always have the ability to drop in Python or R code blocks for any function that might not be included. Here is the code we used for the API call:
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# -*- coding: utf-8 -*-
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
import requests
import json
# REST API call, API Key redacted, Coordinates for New Orleans, LA
response = requests.get("https://api.darksky.net/forecast/*API-KEY*/29.9433,-90.0641").content
# Getting just current weather
data = json.loads(response)['currently']
# Creating DataFrame to be loaded into Dataiku Dataset
nola = pd.DataFrame(data, index=[0])
# Write recipe outputs
nola_Weather_Data = dataiku.Dataset("NOLA_Weather_Data")
nola_Weather_Data.write_with_schema(nola)
The output is one row with the current weather data for New Orleans:

Next, we added a prep step to format the time feature to be more useful. We did this in two quick built-in functions:
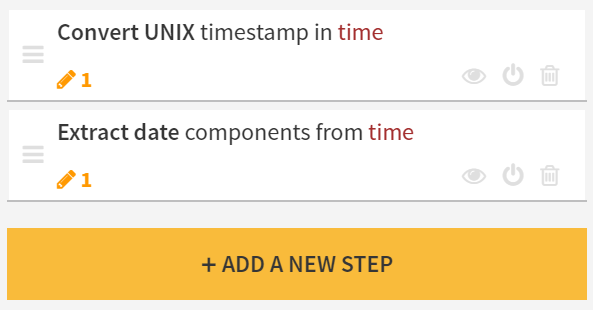
Now that our data is prepped, all we have to do is add the sync step to insert the new data into our Snowflake table to complete our flow! Notice that we have “Append instead of overwrite” checked:

With the flow complete, we can create a scenario that will automatically build the prepared dataset and insert it into the Snowflake table.

Under the menu icon (highlighted above) that can be found at the top of the screen, select Scenarios and then select + NEW SCENARIO on that page.
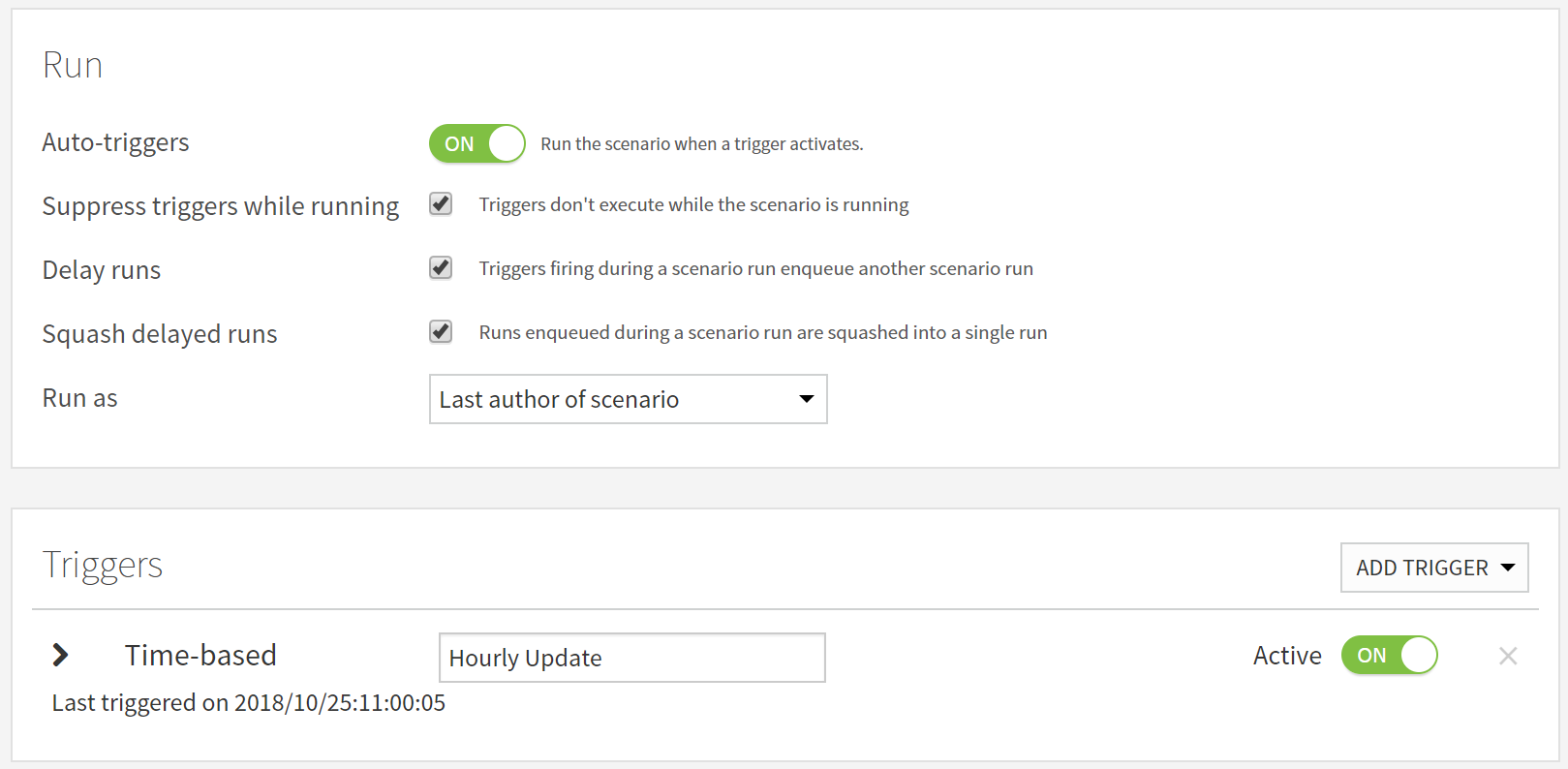
We chose to have auto-triggers activate, so we could hit the scenario with the Dataiku DSS API to get the current weather at that moment. Setting the triggers is very simple. We just choose to add a time-based trigger to go every hour and it’s done!
Now that we have the triggers set up, let’s add some steps for the scenario to execute. The primary thing the scenario will be doing is building the prepared dataset and adding it to the Snowflake table. To do this, we add a build/train step and select the Snowflake dataset with the “Force-build dataset and dependencies” build mode.
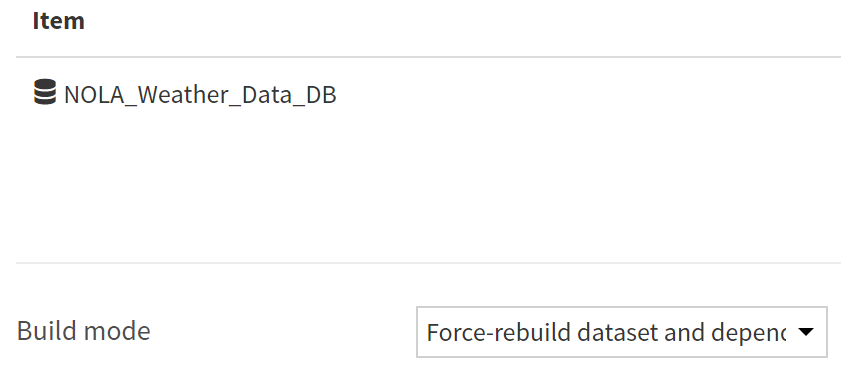
At this point, the scenario will get new weather data from Dark Sky, prepare it, and insert it into the Snowflake table at the top of every hour (or when the DSS API call is made). Something to note is that every time this happens, a log is created and stored on the server where your Dataiku instance lives. If you don’t clear these logs, it can fill up your available storage, so we added the Clear Logs macro and the Clear Old Exports macro to the steps in our scenario to prevent this. If you’re triggering the scenario at a higher frequency than every hour, make sure your Dataiku admins are monitoring disk space and doing appropriate server maintenance that goes beyond these macros:
The scenario is complete! We took this a bit further and created a Tableau dashboard using the Snowflake table as the data source, added that dashboard to the InterWorks Portals for Tableau demo and used Wordsmith to add narrative to accompany the dashboard. That demo can be found here.
You can do many, many different things with scenarios. It’s a huge benefit to choose Dataiku DSS as your data science tool. Our demo here just scratches the surface. If you have any questions about whether Dataiku is the right tool for your business or how it can take your business further, reach out to us. We’d love to help! You can also do a 14-day free trial of Dataiku on your own if that’s more your speed.