
I’m sure we can all relate to the following scenario: A client or boss requests a change to a query, so you plop your hands on the keyboard and start cranking out some SQL. At the end of your last revision, you’re about 75% sure that it’s the correct change. Just prior to executing your changes, a few thoughts run through your mind: Am I going to be stuck waiting for 10 minutes for this query to run? Is the change correct? If it’s not, am I now going to have to wait another 10 minutes to run the original query to compare values?
The normalization of wasted time due to query execution is a very real issue. Up until Snowflake arrived, there was not a way to avoid it without shelling out huge amounts of cash. Sadly, a lot of time working with databases can look like the image below:
Snowflake: The Solution
While you might miss your sword fight, I can assure you that the amount of work you can get done in what used to be execution purgatory will make everybody much happier in the long run. Snowflake has built in a handful of tools that are provided at no additional cost to make running queries faster than ever and at an extremely reasonable price. In this blog post, I am going to discuss how Snowflake’s architecture enhances performance as well as how the Query Cache feature gives you the ability to run common queries fast and free.
Architecture 101
One of the big discussions around Snowflake is it’s MPP columnar structure. Columnar databases are designed for quick analytic queries, but there are still columnar databases that require a fair bit of tuning and optimization to actually receive faster query results. Snowflake changed the game by automatically optimizing all queries that run through the data warehouse. In Snowflake’s Cloud Services layer, all query planning and optimization techniques are determined at the time the data is loaded. From the moment you place data in your table, Snowflake begins gathering information so that when query time comes, it knows how to distribute the query across all compute nodes in the most effective way possible.
This means you no longer need to spend countless hours tuning the data warehouse. You no longer need to determine partitions, partition keys and indexes. Querying in Snowflake is truly as simple as finding out what you want the query to return, then drafting a SQL statement. Boom, your life just got ten times easier.
If you don’t trust that Snowflake is optimizing queries in the most efficient way for your data, there’s even a way to double check their work. In the Web UI, after you execute a successful query, it will be stored in the History tab. From the History tab, you can then select that query’s ID and view a visual diagram outlining how it is executing. This helps to identify bottlenecks in performance.
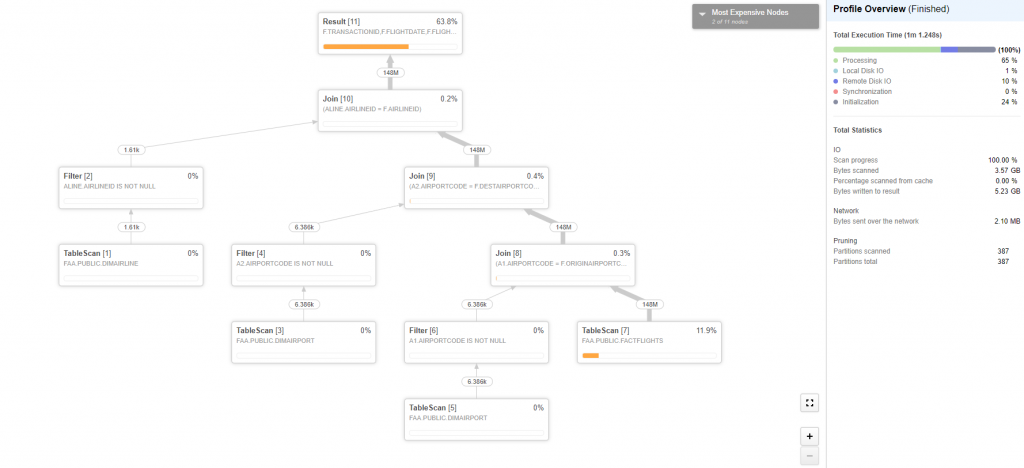
Above: Query Profiler example.
Query Cachin’ Out
Snowflake’ query optimization is a great feature in itself, but a big concern around cloud services in general is the pay-as-you-go model. Let’s say one day I have a single group of Tableau analysts querying my database to figure out a business problem. In that situation, I can make a reasonable estimate of what my bill will look like. However, what if I am going to make my database available to hundreds or thousands of employees? Will my bill be exponentially higher?
One of the ways that Snowflake has made cost savings available to the customer is through their Query Cache feature. Query Cache is built into the Cloud Services layer of Snowflake’s architecture. The Query Cache is exactly what it sounds like – run a query, and the result set is cached in memory for quick access. Where they took it a step further is by offering the Query Cache component in the Cloud Services layer, which is not a billed component of Snowflake. Normally, to run queries, you must resume a warehouse. These warehouses consume Snowflake credits by the second, with a minimum of 60 billed seconds. To execute a query stored in the query cache, you don’t need to have an active warehouse – meaning that the query execution is free.
Query Cache in Action
To showcase the Query Cache feature at scale, I built a query that returns about 148 million rows of airline data.
select f.*, aline.*, a1.*, a2.* from factflights f left join dimairline aline on f.airlineid = aline.airlineid left join dimairport a1 on f.originairportcode=a1.airportcode left join dimairport a2 on f.destairportcode = a2.airportcode;
After executing it one time, the next time I submit the same query, the results are retrieved from my query cache. Here is the history of each time I executed the statement above:

Execution went from over a minute to under a second. The great thing about this is that I will be able to access this query’s results for a default of 24 hours or until the underlying data changes – whichever happens first. The Query Cache can be configured to retain query results for 24 hours all the way up to 31 days. The duration of your cache piece is dependent on your account with Snowflake and heavily influenced by how often your data changes. After running this query a second time, I can even go and check out the Query Profiler to see how Snowflake handles the execution.
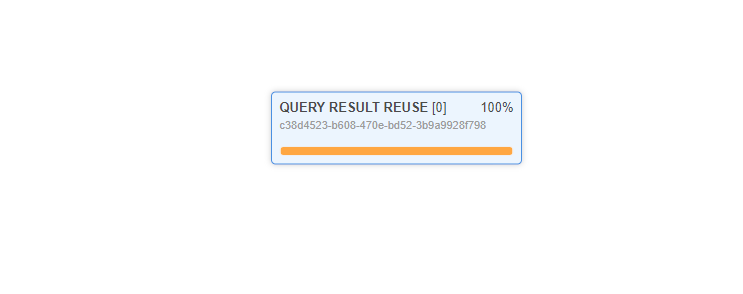
There we have it, a built-in way to run queries at scale for free. This is one of the key features that separates Snowflake from other cloud data warehouse solutions.
To get the most out of Query Cache, there are a few things to keep in mind:
- To access a query from the cache, the syntax must be identical.
- The underlying data accessed must be unchanged; if rows have been updated or inserted, the query will be executed with an active warehouse to retrieve new data.
- The query cannot contain functions that are evaluated at the time of execution (e.g. current timestamp).
You can find Snowflake documentation about Query Cache here.
Why Do You Care?
In a cloud environment, cost saving is a huge factor. Being able to take advantage of the pay-as-you-go model is what has moved businesses to rely on cloud products for mission-critical applications. Snowflake has architected its product to not only save you man hours optimizing queries or tuning databases but to also save compute credits through its query cache feature. Both features pass savings along to the client and help you get the most out of your data warehouse.
This allows businesses to power Tableau dashboards live from Snowflake with insane efficiency and no downside to sharing that dashboard across the entire business. The nature of the cloud implies infinite scalability – a feature that has always been approached with caution. Snowflake has done a great job removing the caution tape from the compute side of the equation, letting you focus on putting the data warehouse to work.