
Dan Murray explores three core areas of data and shares insight into how we should think about each in order to work with data more effectively.

Big data has been the rage for a couple of years. There have been many posts written on the explosion of digital data.
It’s no longer surprising to learn that we are creating more digital data through machine-generated sources than humans. What’s more surprising to me is how inexpensive it has become to collect and store data. A 2009 blog post by Matthew Komorowski got me thinking about this.
Imagine for a moment that your iPhone could have been built in 1981. Forget about the form factor and think only of the cost of the storage. Your phone probably has 64GB of memory. How much would that much memory have cost in 1981?
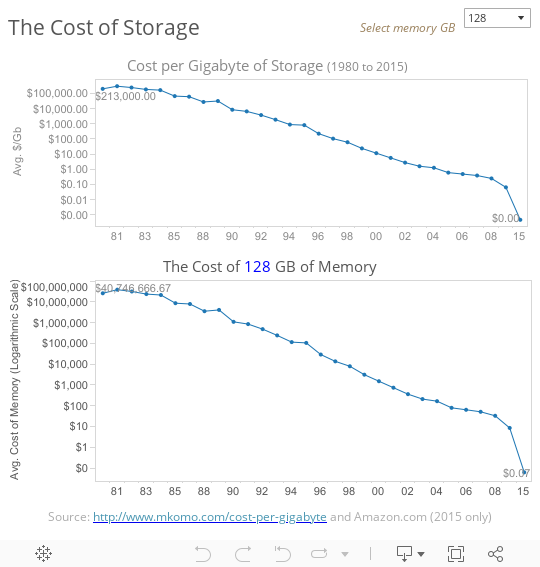
Figure 1 – The falling cost of storage.
I’ve been asking that question of audiences over the past year, and the typical answer is orders of magnitude off. People just don’t fully appreciate how inexpensive storage has become. It’s virtually free. In 1980, the memory for a 64GB iPhone would have cost over $20.3 million.
The Exploding Variety of Databases
The advent of the internet and web search, social media, online shopping and kitty pictures has also driven the development of new database technologies to keep up with the torrent of raw data we can store. This mass of data represents an opportunity and a challenge. When I graduated from Purdue in 1982, SQL was a proprietary invention of IBM. Ed Codds’ “12 Rules” didn’t exist yet. The first commercially-available relational database didn’t come until 1979 via Relational Software.
Rolling forward to today, there are no less than 292 commercially-available database tools:
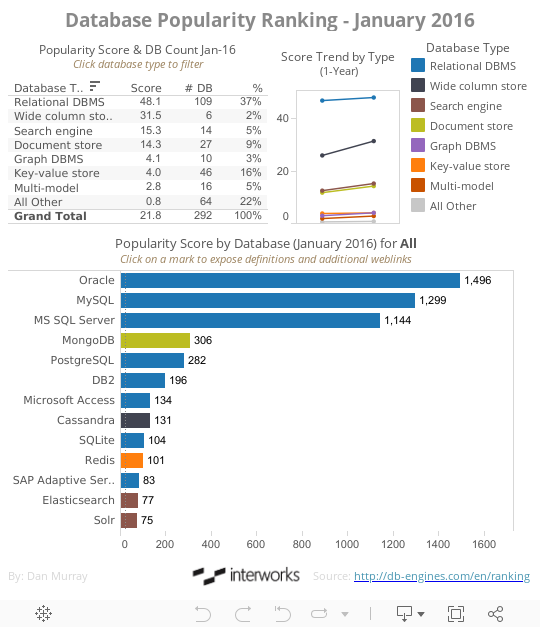
Figure 2 – Database dashboard.
Database models are becoming more specialized to accommodate many different kinds of data streams in the most cost-effective way. This is driving-down the cost of storage further because many of these tools (Hadoop for example) are open source. The links included in the database dashboard provide more details on the different kinds of database products available.
In the old days, coders worried about building the most efficient program possible because the cost of storing and executing code was so expensive. Today the cost has shifted to insuring that the mass of data being collected is complete and accurate. Extract, transform and load (ETL) is normally where projects bog down.
Big data is here to stay and will only get bigger. This is why training data scientists has become so hard at universities. There is a tremendous demand for people with the skill to collect, clean, store and render data in ways that are accurate and understandable.
Descriptive or Predictive?
While predictive analytics are the rage, there is a much larger universe of people that still don’t enjoy the benefit of seeing and and understanding their data. Most of the data that resides in businesses, government and education isn’t seen by anyone. It’s just coming in too fast, and there are too few people that have the skills to collect, clean and transform the data for other people to use. One has to understand what has already happened in order to appreciate fully what may happen in the future.
In part three of these series, we’ll explore how Tableau Software helps less technical people address this opportunity. If you haven’t already, check out part one.