This blog post is Human-Centered Content: Written by humans for humans.
I’m seeing in today’s data landscape that many companies find themselves drowning in a sea of disjointed data. (Apologies in advance for the nautical references, I’m a fan of history and the Royal Navy in the 1800’s, so there will be more!) Imagine a scenario where your customer data is scattered across different systems: marketing, sales and support. Each department has its own data silos, making it difficult to get a complete view of the customer journey. Now, add in the need to get things done as soon as possible, and we end up with data silos, disparate vendors and unnecessary complexity that increases risk. This is a common example of the challenges posed by fragmented data architectures that we see in many organisations. Traditional data architectures often suffer from limitations such as:
- Data Silos: Data silos are everywhere. People need to find answers to their questions, and that necessity causes people to just get things done at the expense of creating noise. This creates isolated islands where critical information (treasure) remains locked away (buried treasure) from the broader organisation (there are no pirates in this story, sorry).
- Data Duplication: These untracked assets multiply. Confusion reigns and costs increase as people build many of the same assets through duplication of effort and not knowing where the data they need is.
- Vendor Lock-in: Reliance on proprietary systems can limit flexibility and increase costs. If an organisation relies on a specific vendor for its data warehouse, it might be difficult and expensive to switch to a different vendor if the need arises.
- Governance Challenges: Maintaining your data quality, security and compliance becomes complex with fragmented data. Ensuring that data is accurate, consistent and secure across multiple systems can be a significant challenge not only in technology terms but also your culture and effort requirements.
The aim of a unified data architecture addresses these challenges by providing a single source of truth for all data, simplifying data management and reducing reliance on specific vendors. The data tooling landscape is growing year on year. Just take a look here at the latest MAD diagram. Due to the number of tools available, the possibilities are limitless; however, our time is not. The level of data engineering required to get even 1% of these working is vast unless we start with a unified data architecture using an open data format that most, if not all, of these tools will support. Multiple versions of the truth float around organisations, eroding trust and decision-making. Data, still a powerful asset, now resembles an uncontrolled flotilla—raw, unruly and impossible to organise to find the gold in our information. In the words of many a navy captain of the early 1800’s, “There’s no time to waste!”
Let’s talk about sorting this data mess out.
A Unified Vision to Reshape the Future of Data Usage
A Unified data architecture transforms the chaos described above into clarity. Imagine a data lake. This is somewhere that all of your data assets live and could be a particular platform such as Snowflake and Databricks, or a virtual platform utilising a semantic layer to provide observability of the data silos and making them accessible. This serves as the flag ship of your analytics ecosystem. It all begins here — a repository of raw, unfiltered information, that is known (observable) and available. We’ll come to data governance shortly as this is an essential part of your future data culture.
My argument for unified data is that this structure should be based on Apache Iceberg (or Deltatables if you are a Databricks fan), alongside unstructured data, as this provides a data format that is both unified and cross-technology. It opens the door for the interoperability of analytics tools without the need for extracting data from its source into copy as this creates duplication and risk.
Apache Iceberg is a high-performance table format, based on top of the Parquet file format, for large-scale analytical datasets. It brings the reliability and simplicity of the SQL language we all know and love to massive-scale data while providing a scalable and efficient way to store and manage data. Iceberg achieves this by adding a metadata layer on top of your data lake files, providing features such as:
- Transaction Support: Traditional data lakes often lack built-in support for ACID properties. This can lead to issues like data corruption or incomplete reads and writes during concurrent operations. Apache Iceberg, on the other hand, provides ACID (Atomicity, Consistency, Isolation, Durability) transactions, enabling concurrent reads and writes and ensuring data integrity. This is essential for scenarios where multiple processes or users need to access and modify the data simultaneously.
- Schema Evolution: Iceberg enables schema evolution by allowing you to add, rename or delete columns without requiring expensive and time-consuming data migrations. This ensures that data remains consistent and accessible as it evolves, and we all know data is never static.
- Time Travel: Iceberg supports the ability to query data at different points in time, enabling historical analysis and data rollback to specific versions. This capability is invaluable for debugging, auditing and analysing historical trends. This is especially useful for those of you with specific compliance that you need to follow. It adds another layer of governance to your data.
- Hidden Partitioning: Iceberg’s hidden partitioning automatically manages partition evolution, allowing you to change the partitioning scheme without rewriting data. This simplifies data management and improves query performance. It’s incredibly simple to re-partition Iceberg tables to improve query performance
- Data Compaction: Storage is cheap these days but Iceberg still provides for multiple compression strategies to optimise file layout and size.
For me, Apache Iceberg is a game-changer. It offers a robust table format that brings structure and reliability to vast, ever-growing repositories of raw data. With Apache Iceberg, the traditional challenges of managing data lakes — such as handling multiple versions of the truth — dissipate. The inherent support for ACID transactions means that data remains consistent and reliable, even in the face of concurrent operations.
Going back to my statement above on the growth of data tooling, how does Iceberg help here? Due to Apache Iceberg being an open format for datasets many vendors have built there tools to support the connection and querying of Iceberg data. Some examples include:
- Apache Spark — Very good for interoperability to use tools in Data Science, SQL Analytics and querying Iceberg.
- Snowflake — High-performance analytics warehouse.
- Databricks — Provides governance through Unity and Data Warehousing; however, it’s designed to use Delta Lake and Delta Tables as the data format.
- Dremio — Great as a semantic layer and catalog for lakehouse architecture. Now, the real power of the fleet (your data) unfolds when a semantic layer breathes life into the data lake, it channels your data into outcome-specific data warehouses where insights are tailored potentially using a data mesh or medallion paradigm.
Creating a Semantic Layer to Govern Your Data
Data governance isn’t merely an afterthought — it is the admiral of our data fleet. It is the audit trail, documenting and tracking of every data asset to build trust and ensure compliance. We’ve already imagined the data store using Iceberg. Now, let’s imagine a world where your data speaks the same language — a system where every stakeholder, from the data scientist to the business executive, taps into a unified, coherent narrative describing your data. A semantic layer acts as the translator turning raw, disparate inputs into accessible insights. It is the bridge between complex data architectures and user-friendly analytics, ensuring everyone is on the same page and aiming at the utopia of the single source of truth. Extending this translation layer is the catalog layer. This stores the metadata, that narrative mentioned above, that describes your data using the terminology and language of your business. It also makes that metadata easy to search for users to when they need to get things done the first place they visit is your business metadata search engine.
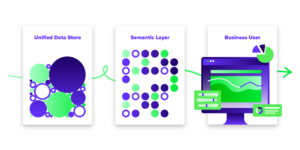
How Do I Get Started with a Unified Data Architecture in Iceberg?
Here’re the steps to create a unified data architecture based on Apache Iceberg:
- Choose a Storage System: Iceberg is storage-agnostic and can be deployed on various cloud storage systems like AWS S3, Azure Data Lake Storage or Google Cloud Storage. Choose a storage system that meets your needs for scalability, cost-efficiency and data durability, or the one you already use.
- Set Up an Iceberg Catalog: The Iceberg catalog stores metadata about your tables, such as schema and partitioning information. You can use various catalog implementations, including Hive Metastore, AWS Glue Data Catalog or Nessie.
- Define Your Data Model: Design a comprehensive data model that captures all your data assets and their relationships. Consider using nested structures for complex data and plan for future analytics needs when defining partitions. It’s very possible to replicate a data structure you have in an existing database to at least get started.
- Ingest Data into Iceberg Tables: Ingest data from various sources into Iceberg tables. Iceberg supports both batch and streaming data ingestion, allowing you to handle diverse data pipelines. For example, you can ingest batch data from a CRM system using a tool like Apache Spark and stream real-time data from a Kafka topic using Apache Flink.
- Optimize Table Layout: Optimize the layout of your Iceberg tables for efficient querying. Consider partitioning strategies, compaction and clustering to improve performance. For example: If you have a table with time-series data, you might partition it by date to improve query performance for queries that filter by date ranges.
This is only the beginning, and there would be work to be done on data cataloging, quality, pipeline engineering and the overall management of the architecture. Reach out to InterWorks if you need help here! If you want an out-of-the-box solution, it’s worth trying Fivetran’s Managed Datalake service.
Let’s Sum Up
So, where has this got us? At the core, this architecture is not just about managing data, it’s about crafting a narrative where each data asset is stored in a format that is open, there is a descriptor for every asset and it’s easily searchable. This provides us both unified data and interoperability that reduces duplication, builds trust and minimises vendor lock in and its associated cost. This takes effort, as we’ve got to get the data assets into an open format via Iceberg. This needs data engineering work.
We need to think about the questions and outcomes the business has. This will allow us to design the data mesh contracts and processes. Then there is the audit of the captured data to connect the dots effectively building the data catalog and semantic layer.
I wouldn’t say this is anything revolutionary, but this isn’t just a technical framework — it’s the foundation for everything data in your business. Whether that is simple reporting, ad hoc queries, search analytics or LLM powered AI, it all depends on this basic foundation of unified data and a semantic layer that will take your business on a fantastic voyage into the unknown of AI data culture.
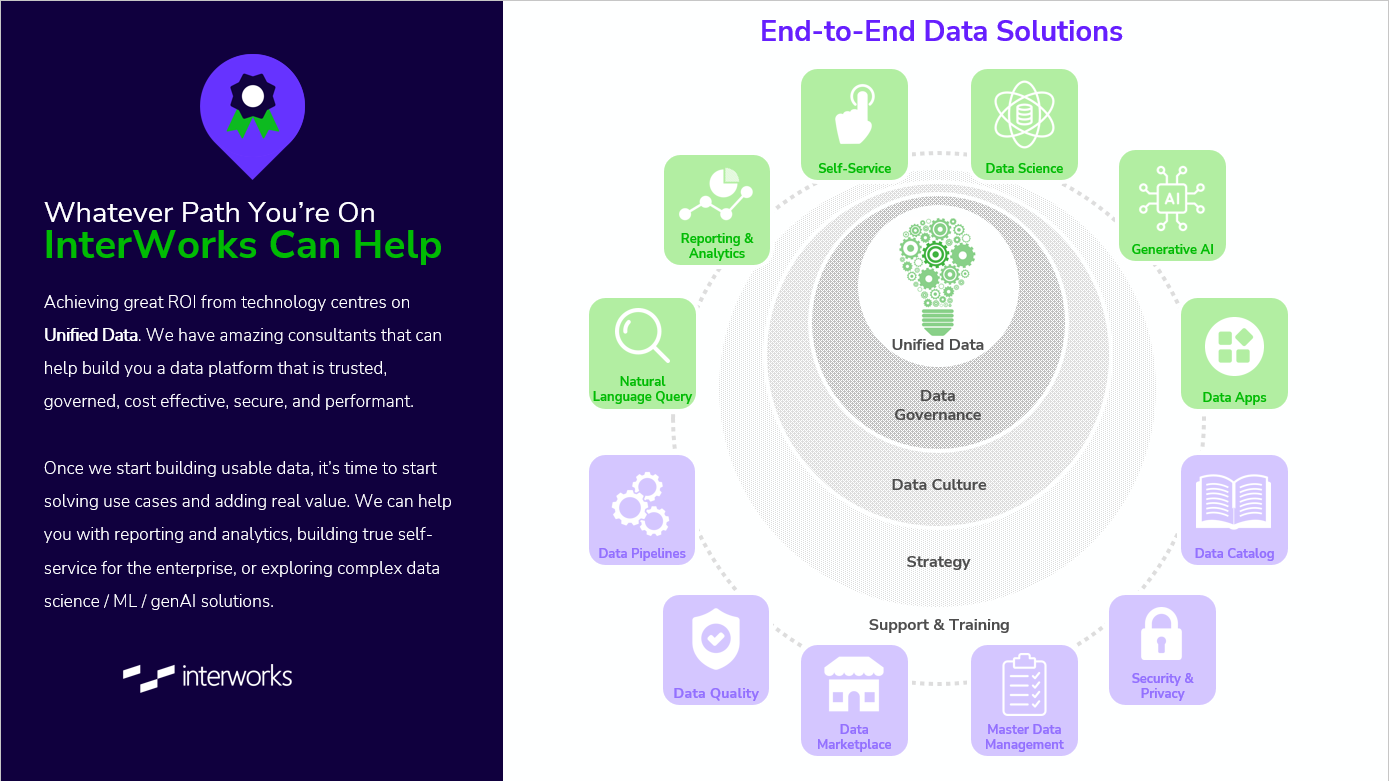
For further reference, I recommend checking out how Unified Data fits into the broader picture of your data practice in the image below, courtesy of my colleague Robert Curtis. As you might have guessed, the InterWorks team is happy to assist in any and all of these areas. You can connect with us here.