
The Quick Version
The Data Mesh architecture provides a credible blueprint for managing data at scale. It offers a solution for organisations that are simply too large or complex to be able to centralise all of their data within a single enterprise data warehouse. It enables self-service analytics, democratising access to data.
Data mesh does not depend on any particular product or service and can work well in heterogeneous environments where data is shared between different tools and platforms produced by different vendors.
A data strategy based around the principles of data mesh provides a strong foundation for enterprise scale data and analytics. Its inherent flexibility means it’s well placed to accommodate a wide variety of data applications including traditional reporting and analytics, data science, machine learning and AI.
The Longer Version
There’s an apocryphal story about a Soviet official visiting London in the 1980s. During his visit, he toured various parts of the city, including the stock exchange and the London School of Economics. While traveling through the city, he couldn’t help but notice many local bakeries piled high with breads and pastries of all kinds, and little sign of queuing. This was in stark contrast to the Soviet Union, where long queues for basic goods like bread were common. After a while, the Soviet official turned to his hosts and asked if he could be introduced to “the person in charge of bread supply for London.”
Economists have long known about the limitations and inefficiency of a top down, command and control economy. This inefficiency became a significant factor in the collapse of the Soviet Union a just few years later.
By contrast, networks of independent entities that can communicate through a set of commonly agreed protocols can operate efficiently at huge scales and levels of complexity. Today’s internet is based on the principle that a network of computers sharing information through a set of commonly agreed protocols can provide greater adaptability and resilience than a single giant computer, however powerful.
The dominant architecture in data analytics for a long time has been based around a single centralised datastore: the enterprise data warehouse. There are certainly benefits if you can consolidate all your organisation’s key data in one place and create a “single source of truth.” This notion of a single centralised data store works well at a small to medium scale and is still a valid strategy for many small to medium sized organisations today.
As the size of an organisation increases, so does the complexity of its data landscape, and we can get to the point where trying to manage all the different data sources and bring them together in one place just becomes impossible.
Once we get to that point, there has been no commonly accepted method of sharing data with other data platforms. Many business intelligence projects have started well, but faltered as it became increasingly difficult to add new data sources and new functionality over time.
This is the situation many larger organisations face today. Let’s look at some typical scenarios:
Scenario 1 — Classic Enterprise Data Warehouse Becomes Unwieldy
This company has existed for some years, and, over time, has made attempts to develop analytics using a data warehouse. While having some initial success, the projects have faltered as uncommunicated changes to source data regularly cause errors within the data pipeline. As new data sources and reporting requirements have been added, the internals of the system have become increasingly complicated, making each change more difficult than the last. Use of the system is declining as errors and lead times for new functionality increase and end users cease to trust the output.
Scenario 2 — Growth Through Acquisition
A company has grown over time by acquiring other companies. These individual companies already had their own analytics solutions, including several separate data warehouses. There is no organised method for the data-warehouses to share data with each other, so what emerges is a hodgepodge, where data output from some warehouses is used as a data source to others, and data consumers have to resort to spreadsheets in order to try and consolidate the data from these different data warehouses.
Scenario 3 — Public Bodies Sharing Data About Vulnerable Adults.
A group of social services departments, working for separate local authorities within a region, wish to cooperate with each other as well as the local health authority and the police to ensure that vulnerable adults who may have lived in sheltered housing, then moved out of the authority area do not get lost in the cracks. Effective sharing of confidential data between different public bodies can ensure that there is a continuity of help available.
Introducing the Distributed Data Mesh
The Distributed Data Mesh, or more commonly just Data Mesh is a data architecture, was first proposed by Zhamak Dehghani in 2018. It is based on the idea of cooperating, independent data domains, rather than a single central data store.
The four key pillars of the data mesh architecture are Domain Ownership, Data as a Product, Federated Governance and Self Service:
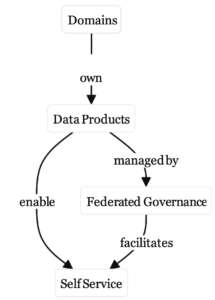
Domain Ownership
Domains in this context represent parts of an organisation that produce or consume data. They may correspond to departments within an organisational hierarchy or geographic regions or separately owned companies that are part of a conglomerate. The point is that specialists in a particular area will have a closer understanding of the data that they produce and consume than a centralised IT department.
Members of these individual domains will understand not just the data itself, but the contextual information around it, including its nuances and limitations, how it might usefully be applied, and where it might be misleading. These are the people best placed to be appointed as data stewards, ensuring that the data they manage is timely and accurate. They are also best placed to understand what parts of their data should be flagged as sensitive or confidential.
I’ve written in more detail about the concept of Domain Ownership in this separate article.
Data as a Product
Users within an individual domain will have a good understanding of their own data. Where data is shared outside of the original domain in its raw form, this kind of contextual information is lost.
To preserve this contextual information, raw data can be packaged into data products. A data product can be thought of as a blob of data, packaged together with descriptions of each of the data elements, example use cases, information about freshness and accuracy, and warnings of any licensing or legal limitations on its use.
We can make a simple analogy here with other manufactured products: A sack of beans purchased from a wholesale market won’t have much in the way of labelling. The purchaser is expected to know what they have purchased and what to do with it. The sack is a size that is mainly convenient for the producer. By contrast, a tin of baked beans is designed to be convenient for the consumer. The beans come pre-baked and soaked in sauce so they’re ready to consume. The label on the tin includes an ingredients list, a use by date and cooking instructions.
Packaging data in the form of data products increases the usefulness of that data when it is shared outside its original domain.
I’ve written more about data products in this article.
Federated Governance
For data products produced by different domains to work together seamlessly, there needs to be some agreement on common standards to use. These standards may specify a character encoding format, or a common classification system for different levels of confidential data. The standards and protocols that form the backbone of the internet (things like TCP/IP, HTTP and TLS) are developed by the Internet Engineering Task Force, a global non-profit organisation. When implementing a data mesh architecture, it can help to have a body, separate from individual domains that is responsible for creation and maintenance of standard protocols and policies that apply across domains.
A central body, separate from individual domains is often best placed to handle user authentication (the process of verifying that a user is who they say they are). Once a user is authenticated, a local domain administrator is usually better placed than the central authority to determine what resources that user should be able to access. This balance of central (federal) and local (domain) responsibilities is at the heart of the data mesh principle of Federated Governance.
I’ve written more about the concept of federated governance in this article.
Self Service
If an organisation’s data is poorly documented, messy or inaccurate, then trying to pull together useful analyses is difficult and requires specialist skills. If we need technical specialists to build any new reports or dashboards, that creates a bottleneck with long lead times for any new requests.
Where the data is cleaned, prepared and well documented with the right tools, data consumers can explore and analyse data, sometimes in new and innovative ways without the need for specialist assistance.
If a decision maker has a hunch about something that isn’t currently covered by existing analyses, they can get a solid, evidence based answer either way within minutes.
Insights can come from anywhere within an organisation. Enabling decision makers at all levels of an organisation to explore data themselves and analyse it in innovative ways will lead to new insights and a better quality data-based decisions. This can lead to many small efficiencies and improvements that would be invisible if just viewed from the top down. Over time these improvements add up. Like London bakeries rather than Soviet bread shops.
I’ve written in more detail about a resurgence in self-service analytics here.
The State of the Market
The data mesh architecture has attracted a lot of interest over the last couple of years. As a result, we’ve started to see vendors alter their marketing message to try and show how their particular product or service can be used in the context of a data mesh. Inevitably, this leads to many vendors trying to massage some of terminology and concepts of data mesh to suggest that what they offer is ideal for this architecture (meshwashing?).
To be clear, there are certainly innovative products and services available that can help to manage and operate a data mesh based architecture, but the architecture does not rely on any particular technology, and it’s certainly not the case that a data mesh has to based around a single platform, any more than the internet requires a single type of computer hardware or software to connect to it. Indeed some of the strength and scalability of the mesh architecture comes from its flexibility allowing existing heterogeneous systems to communicate with each other.
At InterWorks, we can help you with every step of the journey from raw data to finished data products, from on-premise data into the cloud, and from centralised data warehouses to a distributed data mesh. Contact us for an informal chat.
About the Author
Mike Oldroyd has worked in data and business intelligence for over 20 years. In 2023, he was the lead data architect designing and implementing a global data mesh architecture for a well known international consumer goods manufacturer.