
A few years ago, the dominant architecture for data and analytics was based around an enterprise data warehouse (EDW). The intention was to replace separate departmental data silos with a central hub that would allow data to be shared much more easily throughout the organisation.
Early adopters of these EDWs had considerable success. By comparing data across the business, they were able to uncover unexpected insights and new opportunities. These kind of successes have led to a boom in business intelligence investment over the last 20 years or so.
EDWs could be particularly successful where the underlying data source was already well integrated. EDWs that drew much of their data from enterprise resource planning (ERP) systems such as JD Edwards or Oracle eBusiness Suite were working with data that was already well documented and highly integrated. Remodelling the data to support rapid analysis was straightforward so a project could start showing value quickly.
After a while though, some cracks started to show. Data sources became more diverse, the complexity of the data increased and patchy documentation meant that integrating some of these new sources required more than a little trial and error.
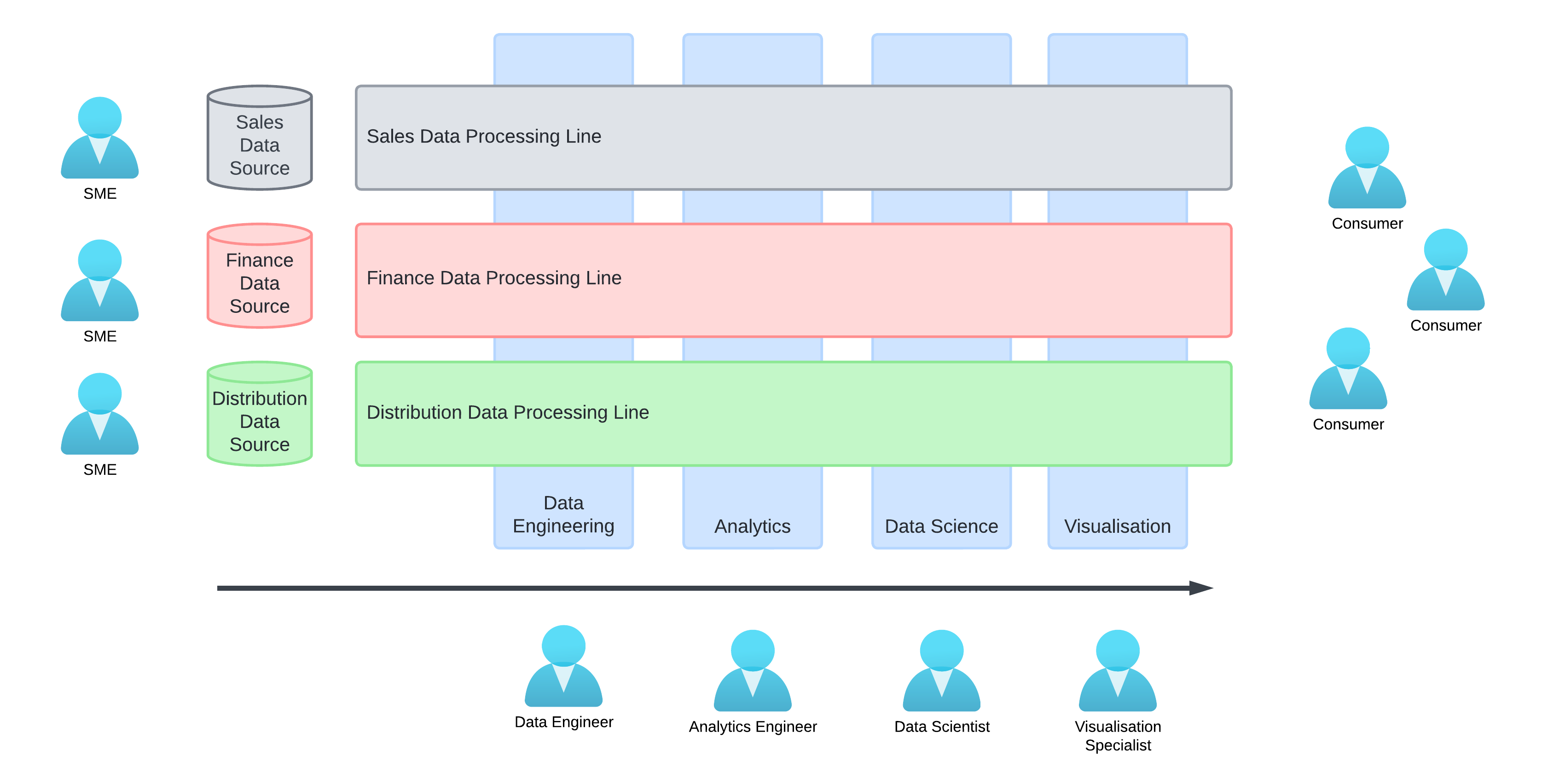
With a centralised architecture, the people operating on the data are technologists, whose skills are based around familiarity with particular tools rather than familiarity with the data. Data processes are handled by data engineers, then analytics engineers, then passed on again to data analysts or data visualisation specialists. We get a kind of Chinese whispers effect where contextual knowledge is lost each time data is passed along.
In her book “Data Mesh,” Zhamak Dehghani introduces the idea of domain ownership as one of the four pillars of a distributed data mesh architecture. With reference to centralised data architectures, she talks about how domain knowledge exists on a different axis to tool knowledge
Above: Diagram axes of domain knowledge and technical knowledge.
What Is a Domain?
In his book “Domain Driven Design,” Eric Evans defines a domain as a “sphere of knowledge, influence or activity.” Dehghani extends the definition to say that the domain represents “either the source of data, or its main consumers”.
Within the context of an organisation, this might correspond to a function, such as sales or finance. In a conglomerate, it could correspond to a division of the business that specialises in a particular product or market.
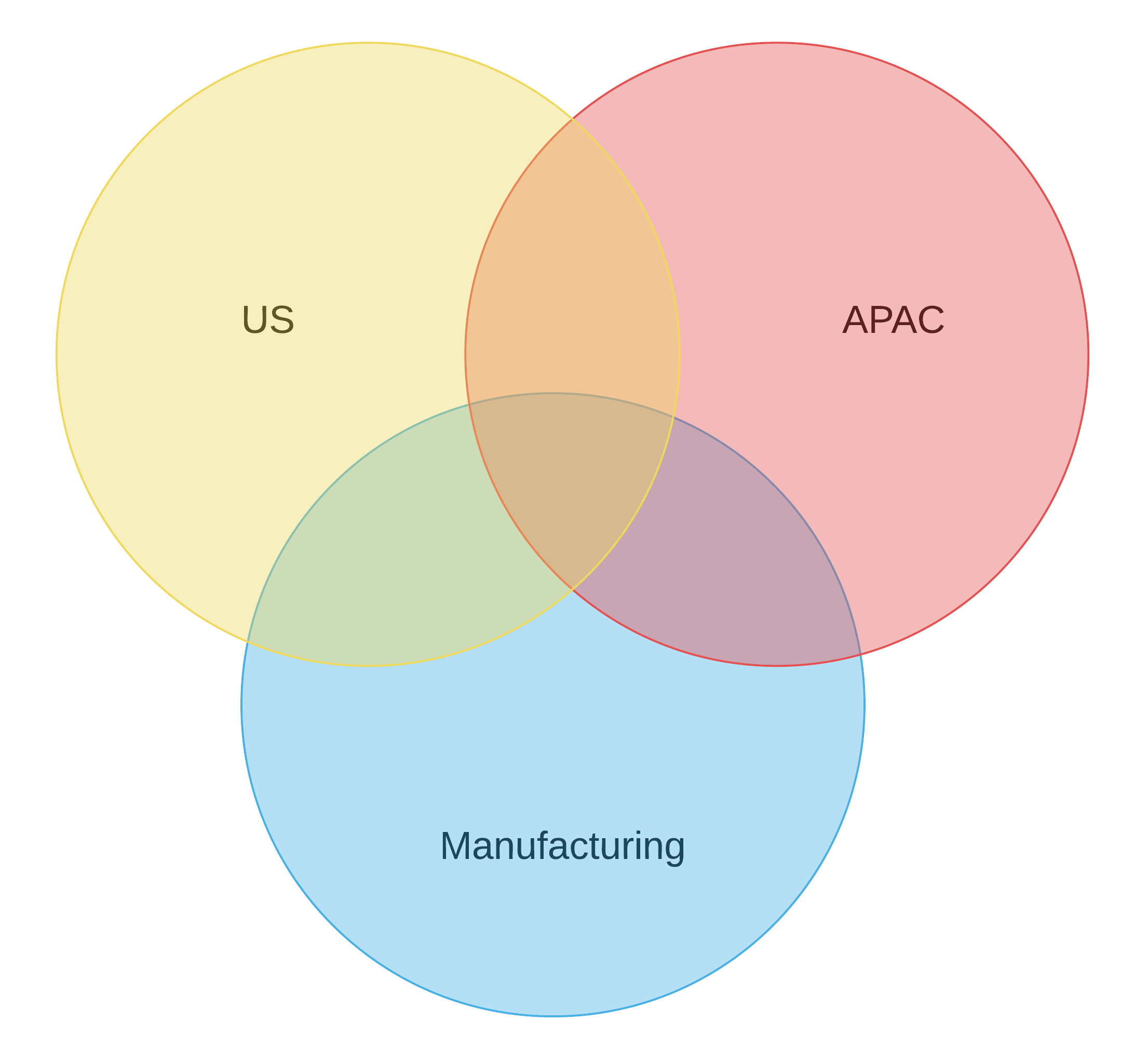
Domains can represent both organisational and functional segments within a business and may overlap:
 Above: Venn diagram with US, APAC and Manufacturing.
Above: Venn diagram with US, APAC and Manufacturing.
In the above diagram, we have US and APAC domains that each serve their own geographic region, but we may also have a manufacturing domain that cuts across the the geographic domains and enables manufacturing specialists to share knowledge that may apply globally.
What Does Domain Ownership Mean in Practice?
The data products managed by a domain are treated as one of the core functions of that domain. This is true for many business functions already. Delivery of regular balance sheets, income statements and cashflow forecasts are a key function for any finance department. In the same way, other departments may be required to publish data that helps the company as a whole track performance and anticipate obstacles. A facilities management department might for example gather and publish statistics around building occupancy, maintenance costs and energy use.
Where domains take on this accountability, they also take on the responsibility to determine many of the details of how the data is collected and managed:
- Domains determine what data needs to be collected
- Domains determine what data is sensitive and should be restricted, obfuscated or redacted before being published
- Where a domain publishes a data product, they are responsible for maintenance of that data product including the management of catalogue entries and SLAs
Difficulties
Historically information technology has been a centrally provided facility. Many domains lack the technical expertise to manage API calls to third-party data sources, data modelling, transformation and governance. This problem has been compounded over recent years by the greatly increased complexity of the modern data stack.
Without a common framework to create and share data products, organisations risk creating a Tower of Babel, with large numbers of competing and incompatible data formats hindering rather than helping communication between domains.
How to Do It Right
Moving to a model where domains own and manage their own data may involve changes to technology, but it also requires changes to working practices and the structures of teams. Organisational change can be challenging to implement and you may not get there all in one go. Here are some recommendations for baby steps that will move you in the right direction.
1. Simplify the Stack to Allow Increased Breadth of Technical Knowledge
A data stack that has evolved gradually over time will most likely be formed from a large number of separate tools, including a mixture of proprietary, bespoke and open source packages. Depending on the tools used, you may need to manage hardware, connectivity, backups, redundancy, updates and version upgrades. If you need teams of technical professionals to manage your data pipeline, then unless data pipelines are part of your organisation’s core value proposition, you may be trying to do too much of this yourself.
Modern, cloud based SaaS packages allow you to outsource much of this complexity, reducing the depth of knowledge needed. An in-house technical specialist can then become competent with multiple tools across the breadth of your data stack rather than a technical expert in just one or two.
2. Embed Technical Staff in the Domain
To provide domains with the technical expertise they need, embed technical staff directly within domain teams. There are multiple examples where embedding technical staff outside their usual boundaries can significantly enhance their effectiveness.
In manufacturing environments, embedding engineers directly within operational or production teams can improve process efficiencies and innovation. By being on the shop floor and closely interacting with the production staff, engineers can identify bottlenecks, inefficiencies and opportunities for process improvements in real time. They can then quickly design, test and implement small, highly targeted solutions. This approach can foster a culture of continuous improvement and innovation within the manufacturing environment.
In the healthcare sector, embedding IT professionals directly within clinical teams can lead to better health informatics solutions. These IT specialists, by working closely with doctors, nurses and other healthcare providers, gain a deeper understanding of clinical workflows and challenges. They can also develop solutions that are both technically sound but also a closer fit to consumer needs. For instance, electronic health record (EHR) systems designed with direct input from end-users tend to be more user-friendly, leading to higher adoption rates and fewer errors.
Embedding journalists directly within military units offers an unparalleled depth of coverage on conflicts. By living, moving and experiencing the realities of military operations alongside soldiers, they can gain a better understanding of the complexities, challenges and human aspects of warfare. It leads to reporting that is more insightful and helps bridge the gap between the public and the often remote realities of military engagements.
3. Preserve Contextual Information by Packaging Data into Data Products
A data product packages data together with descriptive metadata including information about:
- Where the data came from
- How often it is updated
- Example usage
- Any licensing or legal restrictions on its use.
Keeping all this information together makes it much easier for anyone unfamiliar with the data to understand it and use it appropriately. We have a separate post about the value of data products here.
4. Work with a Trusted Partner to Build and Maintain Momentum
Once you’re at the point where you’ve decided that you want to have domains owning and managing their own data, the hardest part can be getting started. Freeing up technical staff to embed within domains can be challenging when your existing technical teams already have ongoing responsibilities across multiple domains.
Working with a trusted partner like InterWorks that has experience across a wide variety of tools, architectures and industries can give you the boost you need to build and maintain project momentum when internal resources are already stretched.