

I was doing some performance tuning for a client recently, trying to improve their query performance from a SQL Server Parallel Data Warehouse. As part of the benchmarking process, I compared performance of a classic star schema (separate fact and dimension tables) with a single flat table holding everything. With a star schema, the database has to handle more joins. On the other hand, it has to wade through much less raw data. It wasn’t clear to me which would be quicker. In this event, I found that my benchmark queries consistently performed nearly twice as fast when using a flat table vs. a star schema.
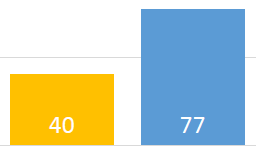
Query time was 40s for flat table vs. 77s for star schema.
Performance Discoveries and Conclusions
During the performance tuning I discovered:
- Really robust benchmarking is a lot harder than it looks. To do it properly, you need to run multiple complex queries over large data sets in a carefully controlled way.
- Other people have already done extensive benchmarking looking at this precise question and came to a similar conclusion.
The conclusion I have come to is:
- Data expressed in a flat table will return results up to twice as fast as the equivalent data in a star schema.
- A flat table will take more disk space (but maybe less than you think).
How much more disk space would be required for a flat table depends on the size of the fact table and the number of dimensions. Flattening multiple tables into a single flat table can result in large numbers of duplicate values. In the past, this would have increased the amount of storage required in proportion to the number of duplicates, but the picture today is more complicated.
Modern cloud platforms such as Snowflake store data in a compressed format. Compression algorithms are very efficient at handling duplicated data, so a table with 10x as many rows because of duplicates may only take a little more space on disk. This complexity means that there’s no easy rule of thumb when trying to determine how much storage might be required. You just have to measure it.
There are other factors to consider when choosing between a star schema and a single table. For example, a dimension table might relate to different fact tables, but could act as a common filter for both in a Tableau workbook. There will also be an overhead in creating these large single tables, so for data that is frequently updated, the cost of maintaining these tables could be significant.